第3章 ハイエンドコンピューティング研究開発の動向
4. 航跡型MHTの並列化
航跡型MHTでは、個々のデータ(観測ベクトル、クラスタ、航跡、仮説など)毎に独立して処理しているのではない。従って、全体を統一的に並列化することはできず、それぞれの処理を個別に並列化するしかない。そこで、どの処理に時間を要しているのかを解析し、最も負荷の高い処理から並列化することにした。
4.1 負荷解析
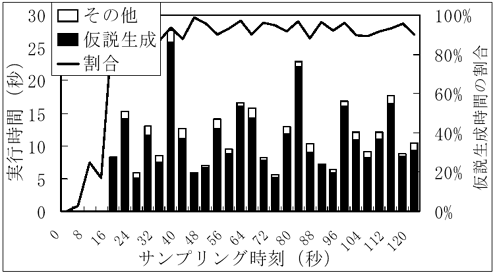
図7に各サンプリング時刻毎の実行時間(左軸で棒グラフ)と仮説生成の全実行時間に対する割合(右軸で折線グラフ)を示す(生成仮説上限数は3,000個)。棒グラフの黒い部分が仮説生成の時間であり、圧倒的に仮説生成に時間を要していることが分かる。実行時間を要しているサンプリング時刻24秒以降の仮説生成時間の割合の平均は、92%である。なお、「その他」の内で最も負荷の高い処理は、クラスタ統合である。クラスタ統合では、お互いのクラスタ内の仮説同士を組合せるので、組合せ数が多くなると処理時間がかかっている。
図7 各サンプリング時刻毎の実行時間
以上の負荷の解析結果から、仮説の生成部分を並列化することにした。逐次の航跡型MHTプログラムにおけるこの仮説の生成方式は、以下の通りである。
(a)全ての親仮説について、それぞれの最も信頼度の高い子仮説を生成する。
(b)N個の親仮説から生成されたN個の子仮説の中で最も信頼度の高い子仮説を採用する。 採用された子仮説を生成した親仮説は、次に信頼度の高い子仮説を生成する。
(c)(b)の処理を子仮説がN個になるまで繰り返す。
4.2 並列化方式
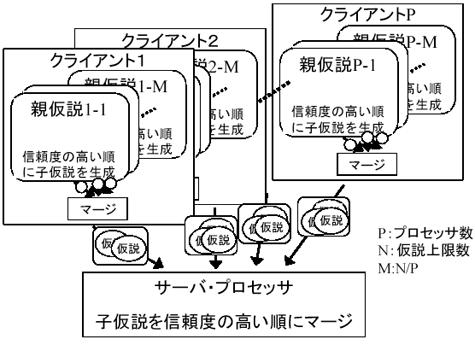
この仮説生成において、各親仮説で子仮説を生成する過程は独立して実行できる。そこで、その親仮説毎の子仮説生成の部分を以下にように並列化する(図8)。なお、子仮説を生成するプロセッサをクライアントと呼び、各クライアントで生成された子仮説を信頼度の高い順にマージするプロセッサをサーバと呼ぶことにする。サーバの処理は子仮説のマージだけであり負荷が低いので、サーバのプロセッサはどれか1つのクライアントのプロセッサと同じあっても良い(ある1つのプロセッサはサーバでありクライアントでもある)。
(a)N個の親仮説をクライアント台数Pで割り、各クライアントに分配する。
(b)各クライアントでは、サーバからの要求に基づき、分配された親仮説群を基に逐次版と全く同様に子仮説を信頼度の高い順に幾つか生成し、それらをサーバへ送信する。
(c)サーバは、各クライアントから送られてきた子仮説群(各クライアント内では信頼度順にソートされている)を信頼度順にマージ・ソートする。このマージの際に、あるクライアントからの子仮説群を使い果たしたら、次の子仮説の生成をそのクライアントに要求する。
(d)(c)のサーバでのマージ処理を子仮説数がN個になるまで繰り返す。
この並列処理方式では、親仮説から信頼度の高い順にある個数の子仮説を生成するという単位で並列化しているので、子仮説の生成方法(MunkresアルゴリズムやMurtyアルゴリズム)には全く依存していない。従って、その生成方法を別のアルゴリズムに変更したとしても、本並列処理方式はそのまま適用できる。
4.3 並列化方式の特長
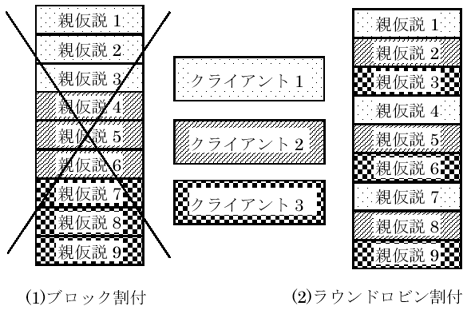
(1) ラウンドロビンによる静的負荷分散
親仮説の各クライアントへの分配は、静的に割り付ける(処理を最初に割り付け、負荷状況によって移動させない)。前述したように、子仮説の信頼度は、親仮説の信頼度と航跡と観測ベクトルの相関度等から算出される。そのため、親仮説の信頼度がそこから生成される子仮説の信頼度に影響する。従って、信頼度の高い順に並んでいる親仮説をNをクライアント数Pで割ったブロック毎に各クライアントに割り付けてしまうと、上位のクライアントに高信頼度の親仮説が集中し、それらのクライアントから生成される子仮説のみが採用される可能性が高くなり、クライアント間で負荷のアンバランスが起き易くなる。そこで、ブロックではなく、高信頼度の親仮説から1つずつ順に各クライアントへ割り付けるようにする(図9)。これにより、各クライアントの親仮説の信頼度が均衡化され、それに従って各クライアントの負荷も均等になる。
(2) 複数仮説単位での通信
各クライアントは子仮説を一つ生成したら直ぐにサーバへ送るのではなく、複数個生成してから送信する。これは、子仮説を一つ生成する処理が粒度として小さすぎる可能性があり、一度に生成する子仮説の数でその粒度を調整できるようにするためである。現在、一度に生成する子仮説の数は、N/P/10としている(N:親仮説数、P:クライアント数)。すなわち、各クライアント毎に平均10回程度サーバへ子仮説群を送信することになる。この数は、本来、並列処理環境のプロセッサ速度と通信速度の比率により調整すべきものである。
(3) 仮説生成のダブル・バッファリング
各クライアントは、生成した子仮説群をサーバへ送信した後は、次の生成要求がサーバから来るまで暇となり、クライアント・プロセッサが遊休状態になる可能性がある。そこで、各クライアントは、次にサーバから子仮説生成の要求が来る前に、次の子仮説群を前もって生成して溜めておく(バッファリングする)ようにしている。これにより、各クライアントの遊休状態が緩和されるだけでなく、早めに生成を開始しているので、サーバからの生成要求に対してのレスポンスも早くなる。
5. 評価実験
今回の並列化による効果を評価するために、シミュレーションによる計測実験を行った。誤信号密度及び新目標密度は同じ値を取り、それぞれ低、中、高の3種類のデータを用いた。サンプリング間隔は4秒で、シミュレーション時間は初探知の時刻0秒から120秒までであり、測定は乱数のシードを変えて30回行い、その平均を取った。また、仮説の生成上限数(=N)は3,000個である。実験に用いた並列処理環境を表1に示す。Alpha21264プロセッサを2つ持つマシンをMyrinetで3台接続した環境である(CPU総数は6)。本計測でクライアント台数を増やす場合は、各マシンに1つずつ割り当てていき、次に2つ目のCPUに割り当てるようにしている。
|
表1 並列処理環境の主な仕様
|
5.1 実行時間
表2に、各クライアント数毎の1サンプリング時刻当たりの全実行時間及び仮説生成時間の平均を示す。クライアント数が0とは、従来の逐次の航跡型MHTプログラムでの実行時間であり、クライアント数が1とは、仮説の生成のみを別プロセッサで実行した場合の実行時間である。また、図10に、各クライアント数毎の高速化率(全実行時間の逐次プログラムとの比率)及び並列化効果(仮説生成時間の1クライアントとの比率)を示す。これらの結果から、以下のことが言える。
前記のクライアント数以上の効果が出ている理由としては、プロセッサ数を増やすことによりキャッシュメモリ量も増加し、キャッシュヒット率が向上するためであると考えられる。すなわち、クライアント数が増えるに従って個々のクライアントで扱う仮説数が少なくなるが、クライアント当たりのキャッシュメモリ量は変わらないので、キャッシュヒット率が向上するのである。試しに、キャッシュがヒットし難いように、データを飛び飛びに格納するように変更したら、実行時間がかなり長くなった。
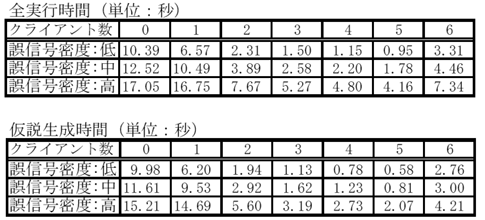
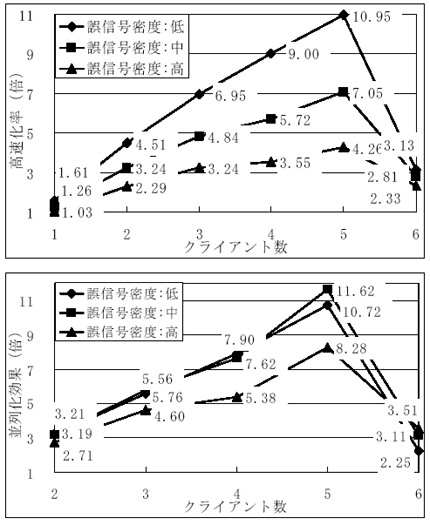
図10 全実行時間の高速化率と仮説生成部分の並列化効果
5.2 通信量と負荷の均等具合
次に、並列化効果を妨げる要因である通信オーバヘッドと各プロセッサでの負荷の不均衡を調べるために、サーバと各クライアント間での通信量と各クライアントで生成した子仮説の数を計測した。なお、計測に用いたデータは、前節の誤信号密度:中であり、クライアント数は5台である。
(1) 入力データ(サーバ→各クライアント)量仮説生成を始める前にサーバから各クライアントに送られる仮説生成に必要なデータは、どの仮説がどの航跡を保持しているかという情報と各航跡と観測ベクトルの相関度情報である。前者はバイトデータ(本来はビットデータでも可)の2次元配列であり、後者はダブルワードの2次元配列である。それぞれの要素数は、仮説数、航跡数、観測ベクトル数で決まる。この入力データの1クライアントの1並列実行当たりの平均データ量は、89Kバイトであった。通信にはMyrinetのMPIを使用しており、実効性能は別途計測により134MB/s(レイテンシーは40μ秒)なので、この入力データの通信時間は0.7ミリ秒程度である。5台実行で仮説生成時間が810ミリ秒なので、この通信時間を5倍したとしても、通信は全くオーバヘッドにはなっていないと言える。
(2) 出力データ(各クライアント→サーバ)量
出力データは生成した子仮説の情報そのものであり、基となった親仮説の識別子と航跡と観測ベクトルの組である。
この出力データの1クライアントの1並列実行当たりの平均データ量は、16Kバイトであった。これは、入力データよりかなり小さいので、全くオーバヘッドはないと考えて良い。(3) 子仮説生成数
各クライアントで生成する子仮説の数を計測し、それが各クライアントでどの程度異っているかを調べた。その結果、各クライアントで生成する子仮説の数は、1クライアントの1並列実行当たりの平均で657個であった。これは、仮説上限数3,000個をクライアント数5で割った600に、先行して生成した数60を加えた数660に近い数字である。また、各クライアントの生成数の標準偏差(ばらつき)の平均は、55個であった。これは、657個に対して12%であり、静的負荷分散にもかかわらず、それほど負荷が不均衡になっていないと言える。
次に、ラウンドロビンによる分配の効果を知るために、ブロック割付した場合も計測した。その結果、各クライアントで生成する子仮説の数の平均は変わらないものの、標準偏差は963個と圧倒的に大きくなっていた。また、全実行時間は1.78→2.16秒、仮説生成時間は0.81→1.20秒に増えており、ラウンドロビン分配による効果を確認することができた。
6. おわりに
以上、信頼度の高いものから順に固定数の仮説しか生成しないNベスト版航跡型MHTの並列化について報告した。並列化に際しては、最も負荷の高かった仮説生成部分を並列化し、各プロセッサで負荷が均等化されるように処理を分配し、並列処理粒度を調整することによりプロセッサ間の通信オーバヘッドが出ないようにし、各プロセッサでは先行して仮説生成を行うことにより遊休状態にならないようにしている。その結果、キャッシュメモリの増量効果もあり、6プロセッサを使用して、全実行時間で4倍〜11倍、並列化した仮説生成部分に関しては8倍〜11倍の高速化を確認した。
このようにセンサ・データ処理においても、従来の情報処理分野の技術が活かせるようになってきている。今後は、更にデータの抽象度を上げ、センサ配置の最適化やセンサ・データに基づく意思決定支援等のAI的な要素を含んだ処理も必要とされると考えられる。
参考文献
[1] 小菅義夫, 辻道信吾, 立花康夫, ”航跡型多重仮説相関方式を用いた多目標追尾,” 信学論(B-II), vol.J79-B-II, no.10, pp.677-685, Oct. 1996.[2] 小幡康, 系正義, 辻道信吾, 小菅義夫, “Nベスト解探索アルゴリズムによる航跡型MHTの高速化(1)−Nベスト解探索アルゴリズムの導入方式−,” 2001信学総大, B-2-32, Mar. 2001.[3] 系正義, 小幡康, 辻道信吾, 小菅義夫, “Nベスト解探索アルゴリズムによる航跡型MHTの高速化(2)−演算時間および追尾維持性能の評価−,” 2001信学総大, B-2-33, Mar. 2001.[4] 系正義, 辻道信吾, 小菅義夫, “航跡型MHTによる追尾維持性能のシミュレーション評価,” 信学技報SANE99-117, SAT99-154, P.71-78, Fep. 2000.