3.3.1 高性能計算連続体 ― NPACIプログラムの概要 ―
近山 隆 委員
3.3.1.1 はじめに
National Partnership for Advanced Computational Infrastructure(NPACI)は米国National Science Foundation(NSF)のプロジェクトである。このプロジェクトは、地理的に離れた計算資源を有機的に結合し、いつ・どこからでも同じやり方で高性能計算ができる新たな研究インフラストラクチャを築くことにある。
NPACIの実現を目指す新たな目標のひとつに、伝統的な数値計算のためのインフラストラクチャと、比較的最近発展してきた大量のデータを中心とした処理のインフラストラクチャの統合がある。今後の高性能計算では、数十から数百テラバイト級のデータを扱うことは必須になる。NPACIの中心的なサイトであるSan Diego Supercomputer Center では1998年時点で50TBのデータを高性能記憶システム上で運用しており、2000年にはペタバイト級のデータを保持できる見込みである。このようなローカルな記憶容量の拡大のみならず、遠隔地にあるデータへの円滑なアクセスも重要であり、NPACIの目標のひとつとなっている。
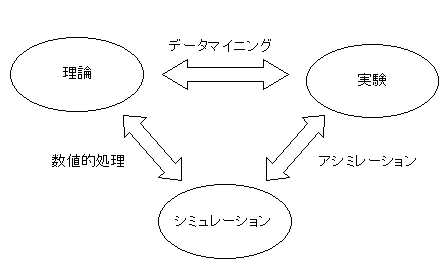
計算技術の発展により、理論と実験に加えて、計算機によるシミュレーションが科学の手段として重要になってきている。NPACIではこの理論・実験・シミュレーションを円滑に結合する情報技術体系(図1)の確立を目指している。
|
図1 理論・実験・シミュレーションを統合する情報技術
NPACIには数多くのサブプロジェクトがあるが、本稿ではアーキテクチャとメタシステムについて述べる。
3.3.1.2 アーキテクチャ
過去十年程度の間に高性能計算機システムの性能は約千倍向上した。この性能向上がどのようにしてもたらされてきたかを概観し、この性能向上速度を今後十年継続するためには計算機アーキテクチャ上どのような変更が必要になるか、それがシステム全体にどのような影響をもたらすかについて予測する。
・大規模並列計算機
高性能計算機の実現に並列処理を用いることはすでに常識となっているが、将来ともこの傾向は強まっていくであろうと予測できる。しかし、今後の半導体技術の更なる進展によってプロセッサの性能が向上し、また結合できるプロセッサの数が増大していくにつれて、プロセッサの性能を十分発揮させるだけのデータを供給する技術が性能向上の鍵となることは間違いない。
並列計算機の黎明期には、複数のプロセッサを専用のハードウェアで、特殊な形態で結合するのが一般的であった。近年、並列計算が一般化するに伴い、複数のプロセッサ間結合にも汎用品(Myrinetなど)が用いられることが多くなってきている。また、独立した計算機システムを接続するためのネットワーク機器も高性能化しており、汎用のLAN機器での結合も費用対性能比の面で有利になってきている。
・階層メモリ技術
プロセッサの高速化に比して、メモリはさほど高速化していない。プロセッサの速度向上が年率60%にも上るのに対し、DRAMの速度向上は7%に過ぎない。大規模な並列計算機システムでは、一次キャッシュ中のデータへのアクセスが1〜2サイクルで済むのに対し、遠く離れたメモリにあるデータのアクセスには数十万サイクルもかかることになる。このギャップを埋める技術が、高性能アーキテクチャ実現の鍵となると予想できる。
そのためには、現在用いられているよりもさらに深い階層構造を持つメモリシステムが必要になる。こうした階層メモリもアクセスの局所性が低くては十分な性能を発揮できない。そこで、キャッシュなどの階層をうまく利用するアルゴリズムや、メモリ階層を意識したコンパイル技術の開発が重要になる。
また、遠隔メモリのアクセス遅延が性能低下をもたらさないためには、アクセス遅延の間に他の有用な計算をする必要があり、このためには多数の実行スレッドを低オーバヘッドで切り替えられるアーキテクチャが求められる。
別の方向として、プロセッサ−メモリ間のスループットを改善するためにはProcessor In Memoryと呼ばれる、プロセッサとDRAMを同じチップ上に実装する方式も注目されている。DRAMのアクセス速度のボトルネックはプロセッサとのインタフェースを整えることにあり、同じチップ上に実装することによってこの点を大きく改善できる可能性がある。
・ベクトル計算機
大規模並列計算機だけではなく、ベクトル計算機も進歩を続けている。しかし、近年ベクトル機のクロック向上は頭打ちの状況で、もはや最大級の問題を扱うシステムではないといえる。一方、ベクトル機においても並列度を上げて性能を向上させる手法が一般化してきている。また、コスト的に有利なCMOS技術への移行の動きも顕著である。
前述のとおりベクトル機はもはやハイエンドとはいえなくなってきているが、ソフトウェア資産は潤沢で、豊富な応用ソフトウェアの供給や安定したシステムソフトウェアを有する強みから、今後しばらくは重要な地位を占めつづけるであろう。
・性能向上の見通し
過去十年で高性能計算機システムはピーク性能において約千倍の向上を果たした。さらに千倍の向上を果たして、ペタフロップス級の性能を実現するには、何が必要であろうか。CMOS技術の進展は10〜15年程度で限界に達する。SIAは、今後十年間のクロック速度向上は3倍以内であろうと予測している。一方、ジョセフソン素子など、原理から異なる新素子技術に基づくシステムが商用になるには10〜15年が必要であろう。
今後の性能向上のための要素技術としては、CMOSに代わる素子技術の利用によるクロック速度向上、プロセッサアーキテクチャの改良によるクロックあたりの性能向上、そしてシステムアーキテクチャの改良による向上が考えられるが、今後十年のこれらの要素による性能向上は、十倍程度にとどまるであろう。となると、ペタフロップス級の性能を実現するには、現在の百倍程度高い並列性を持つシステムが必要になる。
・入出力
仮にペタフロップス級の計算機システムが実現できたとすると、従来と同様の応用ソフトウェアを動かすには34テラバイト程度のメモリが必要となる。これと見合う量のオンラインディスクとしては1ペタバイト程度が適切である。2007年のディスク技術では、これは45GBドライブ22,000台と予測され、その合計バンド幅352GB/secと予測される。
34TBのチェックポイントダンプを5分で取れるためには113GB/secのバンド幅が必要である。これは22,000台のディスクをピークの1/3の性能で並列動作させることになり、これは容易なことではない。
一方、1PBのディスクのバックアップにはexabyte級のアーカイブ装置が必要になる。これには、今日のテープとロボット技術では500,000立方フィート(14,000m3)の容積が必要になる。こうした点の解決も重要な課題である。
・まとめ
高性能計算機システムの性能を従来のペースでは向上させていくことは非常に難しく、性能向上には複雑度の増加が伴うことを避けられない。このため、今後の高性能システム実現にはソフトウェア面の非常な努力が必要になる。オペレーティングシステムは、非常に多数のスレッドと複雑な階層メモリを管理しなければならない。コンパイラや実行時システムは、プロセッサ内の高い並列性や、多層にわたる階層メモリを有効に扱う必要がある。たとえこうした基本ソフトウェアについての改善を施せたとしても、高性能を実現するために応用ソフトウェア開発にかかる負担は現在よりもさらに大きなものとならざるを得ない。
現在の技術の延長では10年程度で性能向上の限界が来るであろう。さらにその先の高性能化を求めるには、従来と異なる新たな技術体系の開発が急務である。
3.3.1.3 メタシステム
メタシステムは、ネットワーク上に広域分散した数多くのファイル、データベース、計算機、入出力機器などを統合し、あたかもひとつの巨大な計算機環境を利用しているような使い勝手を利用者に提供するシステムである。メタシステムを用いれば、利用者はデータがどこにあるのか、それをどの計算機で処理をするのか、ついてはどのデータとどのプログラムをどこにコピーする必要があるのか、といった物理的な層を意識せずに処理を行なうことができる。
ここではNPACIのメタシステムを構成する要素である、共有永続オブジェクト空間、透過的遠隔実行、広域キュー、広域並列処理、そしてメタ応用について概説する。
・共有永続オブジェクト空間
共有永続オブジェクト空間は、メタシステムのもっとも基本的な機能である位置透過性を実現するものである。すなわち、さまざまな資源がどこにあるのかを意識せずに、利用者が使えるようにする機能である。ファイルアクセスについては従来からNFSやAndrewのような分散ファイルシステムが使われてきたが、共有オブジェクト空間においては、ファイルはもちろんのこと、実行中のタスクなどに至るまで、適宜名前を与え、権限をもつ利用者間で共有するようになる。
こうしたオブジェクトは、たとえばファイルひとつをとっても、単一のインタフェースを持つとは限らない。同じ物理的構成を持つファイルを、異なるインタフェースを持つクラスでオブジェクト指向に抽象化できる。たとえば、特定の応用に特化したファイルなら、通常のread, write, seekなどの他に、2次元の配列データを表すものとして扱う、行単位、列単位、あるいは部分配列に対する入出力などのインタフェースを持つことも考えられる。キャッシュやプリフェッチの仕方を利用者が指定すること、入出力を応用プログラムの実行と非同期的に行なうこと、複数の入出力要求をキューイングすることなども考えられる。逆に、異なるフォーマットで格納したデータに対して、同じインタフェースを提供することも考えられる。さらに、受動的にデータを提供するだけでなく、自律的に動作するようなオブジェクトも考えられる。
・透過的遠隔実行
透過的な遠隔実行はやや高度なサービスになる。現在普及しているシステムでは、利用者が自分のプログラムをどこで実行するか(自分の目の前にあるワークステーションか、近くの高性能計算機か、それとも遠隔地の計算センターか)を決めなくてはならない。この際には、どこで実行すれば転送時間まで含めてもっとも早く結果が得られるか、遠隔システムを利用するのに技術的問題はないか、アカウントはあるのかなど、さまざまな点を考慮に入れた判断が必要になる。
メタシステムにおいては、利用者は単にどのプログラムを実行するかを指定しさえすればよい。システムがその利用者が利用可能なホストの中から適切なものを自動的に選び、必要なプログラムの転送も自動的に行なって、プログラムを実行してくれる。データは上述の共有永続オブジェクト空間から入力し、結果も同様に共有永続オブジェクト空間に格納する。
・広域キュー
これは現在でもよく用いられているバッチシステムを、分散した複数のシステムに広げて運用するものである。メタシステムにおけるバッチシステムは、単一の機種に対するものではなく、多様な機種の計算機が交じり合った環境でも利用できるようにする。
・広域並列処理
メタシステムは与えられた問題をうまく分割可能な場合、複数のホストに仕事を割り振って実行することにより、非常に大規模な並列処理を実現することができる。もちろんこのような分割がうまくできない問題も少なくないが、独立性の高い部分計算からなるデータ並列問題については、比較的容易にこのような並列化が可能である。
・メタ応用
メタ応用とは、従来個別の要素問題として扱われてきたような複数の計算処理からなる、全体としてひとつの応用である。それぞれの要素問題の特性は異なり、たとえば共有メモリ並列処理に向いた問題、ベクトル計算機に向いた問題、分散した超並列処理に向いた問題が含まれていることが考えられる。これらを単一のホストで処理するのは得策ではない。システムはこうした問題の性格を考慮に入れて実行方針を決めねばならない。
これは容易に解決できる問題ではないが、NPACIが目標としている機能のひとつである。
・まとめ
メタシステムの技術は実験的な状況から、実用に耐える技術へと成熟しつつある。メタシステムの持つべき様々な機能が実用に供されるようになれば、科学技術における計算処理の生産性は飛躍的に向上するであろう。
参考文献
Sidney Karin and Susan Graham, Eds., “The High-Performance Computing Continuum”, Communications of the ACM, Vol. 41, No. 11, November 1998.
3.3.2 ハイエンド計算におけるグローバルコンピューティング
関口智嗣 委員
3.3.2.1 はじめに
ハイエンド計算技術はハイパフォーマンスコンピューティング(HPC)を実現する上で今後重要な課題である。応用としての計算科学技術は純粋な真理追究の科学のみならず、生産・加工・設計・製造等のいずれにおいても実際の産業活動に直結している(図1)。ハイエンド計算技術はこの計算科学を支持する情報基盤システムである。すなわち、ハイエンド計算を通じて高性能計算機資源の利用が社会生活においても非常に重要な意味を持っていることを示している。このため、ハイエンド計算技術は大企業だけではなくベンチャーや中小企業も技術革新のためにはこの技術導入が必至である。ところが、スーパーコンピュータのような高性能計算機はパソコンと較べて価格性能比が悪いので、企業による個別導入が困難になっている。スーパーコンピュータはスーパーコンピュータらしく利用される局面、例えば数ギガバイト級の大規模メモリを必要とする計算とか絶対性能が必須で時間的制約がある計算など他では代替が不可能で、かつミッションクリティカルな場合には不可欠な計算能力を提供する。一方で、ハイエンド計算技術はハイエンド計算のみならず、ダウンスケールした波及効果として、より価格性能比の優れた計算技術が望まれている。
本稿では、ハイエンド計算技術に求められる今後の技術としてグローバルコンピューティング技術を紹介し、その必要性と将来像について述べる。
3.3.2.2 グローバルコンピューティング技術概観
グローバルコンピューティング(Global Computing)関連技術は様々な呼称を持つ。例えば、コンピュータの物理的配置や接続を隠蔽するメタコンピューティング(Meta Computing)と呼ばれたり、グリッド(GRID, iGrid)と呼ぶ場合には仮想的な計算資源の供給インフラを構築するという意味合いが強い。さらに、ネットワーク可用サーバ(Network enabled server)という計算サービスやダトゥール(Datorr: Desktop access to remote resources)やポータル(Computing Portal)と呼ばれることもある。いずれも、定義が明確なものではないが、広域に敷設された高速ネットワークを利用したコンピュータの集合体をインフラとして構築または利用する技術であることは疑いない。
グローバル コンピューティングは様々な側面を有している。高速計算はひとつの明白な応用であるが、もちろん、それだけではない。いくつかの具体的応用システムイメージについて示す。
3.3.2.2.1 スーパーコンピュータ・アンサンブル
当初の広域分散コンピューティングのイメージである。世界中に分散されているスーパーコンピュータをネットワークで接続し、仮想的に超大規模スーパーコンピュータを作り出し、これまでに絶対解くことができなかったような問題への挑戦である。広域分散コンピューティングにより、これまでのコンピューティング環境をはるかに凌ぐ計算パワー(ピーク性能)を提供することが目標である。
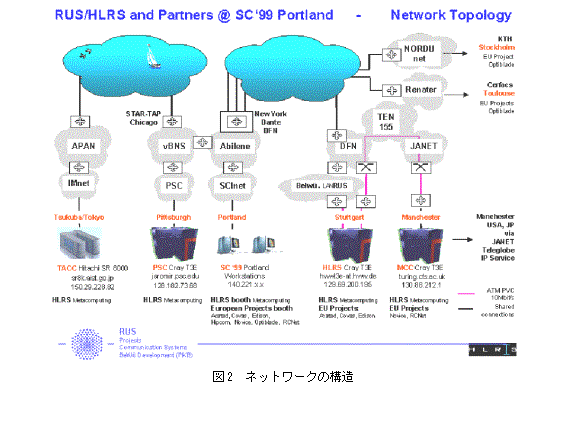
Supercomputing'99においてこうした大規模計算の実験が行われた。プロジェクトチームはドイツのHLRS(High Performance Computing Center Stuttgart)を中心に、イギリスのCSAR/MCC(Computer Services for Academic Research/Manchester)、アメリカのPSC(Pittsburgh Supercomputer Center)と日本の工業技術院先端情報計算センター(TACC)によるメンバー構成であった。デモンストレーションではHLRS、CSAR/MCC、PSCのT3EとTACCの「SR8000」(64ノード)とを高速ネットワークで接続し、接続されたコンピュータの総合最高性能が2.2 TFLOPSコンピュータとして、分子動力学、計算流体力学のシミュレーションを実行した(図2)。具体的な計算例としてはまだまだ小規模であったが、こうしたスーパーコンピュータをネットワーク接続して利用する可能性を示したものとして、また国際的な協力下において実現したことは興味深い。
3.3.2.2.2 広域分散コンピュータオーケストラ
一方、グローバルコンピューティングは世界中の遊休計算機を有効に活用して、無尽蔵の要求に対して高いスループットを提供することを目指している。同じくSupercomputing'99で行われたデモでは世界10カ国に設置されたワークステーションやPC UNIX機の合計150台上に計算処理を分割して分散配置を行った。今回のこの挑戦の面白いところは世界中の計算機を集めてくることにほとんどお金がかかっていないことである。並列性の高いモンテカルロ計算であったが、世界中の遊休計算機を活用すれば大規模計算ができる可能性を示した。システムの提供方法などは個人による依頼ベースであり、システム的な対応ではなく、技術的な問題は山積みである。例えばアカウントを作成する必要があること、事情により供出が困難になってもそれをマスタ側に伝える方法がないこと、別のプログラムを実行させようと思ったときには全部の計算機でそのプログラムを用意する必要があること、などまだまだ実用的にはほど遠いものがある。しかし、インターネットの世界でハウジングビジネスが成立しているのであるから、計算そのものをサービスとして受けるという科学技術計算におけるASP(Application Service Provider)が成立することが期待される。
3.3.2.3 グローバルコンピューティング技術動向
グローバルコンピューティング(広域分散計算)の近年の発展はコンピューティング技術の高性能化とネットワーク技術の高速化という技術的発展ばかりではなく、これらが社会的にも普及し、従来のコンピュータが占有的資産であり排他的に用いることから共有的資産でGive & Takeにより活用される資産であるという認識の中で現在注目を集めている技術である。もちろん、広い意味でインターネット技術の一応用に過ぎないのではないか、なんら新しいものを産み出していないのではないかという批判があるのも確かである。しかし、インターネットばかりではなくや地域ネットワーク、職場や大学のキャンパスエリアネットワーク、ローカルエリアネットワークなどがこうしたグローバル化を実現するための基盤を提供することで初めて実現が間近になった技術である。これらの基盤を用いることで、電子商取引、電子政府他のインターネットビジネスチャンスは大きく広がってきた。ここではあえてグローバルコンピューティングが「コンピューティング」とあえて付けているところに着目したい。すなわち、コンピュータ生来でかつ人間の苦手な計算処理技術を中心として広い意味のインターネット技術への応用を目指している。安易な言い方をすれば、これまでのWeb がデータアクセスを中心に考えていたのに対して、計算処理における Web を目指していると考えてもよい。このために必要な要素技術と実際の応用技術、これらの統合化技術が求められている。
代表的なグローバルコンピューティングシステムを下記に示す。また、下記を含めて代表的なプロジェクトの名称等を図3に示す。
・Akenti http://www-itg.lbl.gov/Akenti/ アメリカ
Ø 分散ネットワーク環境でのスケーラブルなセキュリティサービスを提供するセキュリティモデルおよびアーキテクチャ。
・Albatross http://www.cs.vu.nl/albatross/ オランダ
Ø グローバルコンピューティング環境におけるクラスタシステム(広域クラスタシステム)上でのプログラミング方法や、高性能を得るための方法などに関する研究プロジェクト。
・AppLeS http://apples.ucsd.edu/ アメリカ
Ø アプリケーションレベルでのスケジューリングに着目した研究プロジェクト。
・Condor http://www.cs.wisc.edu/condor/ アメリカ
Ø 分散配置された多数のワークステーション等を使って高スループットな計算を行なうための開発環境等の枠組みを提供するシステム。
・EuroTools http://www.irisa.fr/EuroTools/ ヨーロッパ各国
Ø ヨーロッパ全体で高性能計算・ネットワークを利用するためのプロジェクト。
・Globus http://www.globus.org/ アメリカ
Ø アメリカを中心とした、現在最も大きなプロジェクト。グローバルコンピューティング環境のソフトウェアインフラストラクチャを構築するためのツール群を提供。
・Grid Forum http://www.gridforum.org/ 世界中
Ø グローバルコンピューティングシステムの標準化を目指し、様々な技術要素に関して標準化策定など交換を行なう会合。
・IceT http://www.mathcs.emory.edu/icet/ アメリカ
Ø グローバルコンピューティング環境における仮想的な計算機の併合/分割や、コードやデータの可搬性などの機能を備えたメタコンピューティングシステム。
・IPG http://www.nas.nasa.gov/Groups/Tools/IPG/ アメリカ
Ø コンセントにプラグを差し込むだけで誰もが電力の供給を受けることができるのと同様に、国中/世界中の情報を簡単に引き出すことが出きるような枠組み、仕組みを提供するシステムに関する研究プロジェクト。
・Legion http://legion.virginia.edu/ アメリカ
Ø デスク上のパソコン/ワークステーションから世界中の資源にアクセスすることのできる、オブジェクトベースのメタシステムソフトウェアプロジェクト。
・NetSolve http://www.cs.utk.edu/netsolve/ アメリカ
Ø ネットワークを介して遠隔地にある科学技術計算用ライブラリを利用するためのクライアント・サーバモデルに基づくシステム。
・Ninf http://ninf.etl.go.jp/ 日本
Ø 電総研を中心として開発中の日本発のシステム。遠隔手続き呼び出しの手法を利用し、プログラマが容易に遠隔地にあるハードウェア、ソフトウェア、データベース等を利用することのできるシステム。
・PACX-MPI http://www.hlrs.de/structure/organisation/par/projects/pacx-mpi
ドイツ
Ø グローバルコンピューティング環境用に拡張したMPI通信ライブラリ。
・UNICORE http://www.kfa-juelich.de/unicore/ ドイツ
Ø ユーザが遠隔地にある計算資源にリモートジョブエントリを行うシステム。

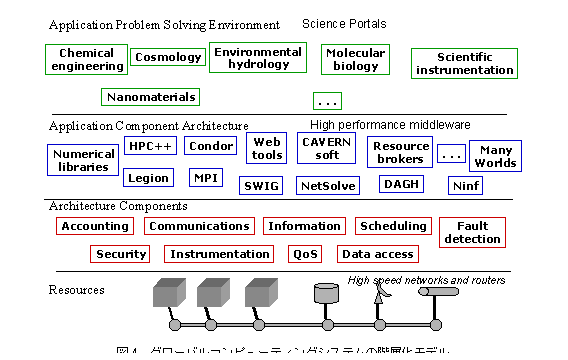 グローバルコンピューティングはこれらのプロジェクトは単独で広域分散コンピューティングに関する全ての機能を有するわけではない。それぞれのプロジェクトがそれぞれの役割を担っている。グローバルコンピューティングシステムにおいても階層化モデルにより表現することが可能であり、それを図4に示す。
グローバルコンピューティングはこれらのプロジェクトは単独で広域分散コンピューティングに関する全ての機能を有するわけではない。それぞれのプロジェクトがそれぞれの役割を担っている。グローバルコンピューティングシステムにおいても階層化モデルにより表現することが可能であり、それを図4に示す。
当初、広域分散コンピューティングに関する研究が盛んになり始めた頃は、主にミドルウェア層に位置するシステムが盛んに研究・開発されてきた。現在でも数多くのシステムが実績を残している。図3に示したシステムの多くも、このミドルウェア層に位置することになる。これらのシステムは広域分散コンピューティング環境で動くアプリケーションの作成や、実際に動かす際の手助けをしてくれるシステムであり、プログラマが直接触れることになる部分である。このミドルウェア層に位置するシステムの中から、遠隔地にある計算資源をアクセスするための仕組みを提供しているNinfと、並列プログラミングに良く利用されるメッセージ通信ライブラリであるMPIをグローバルコンピューティング環境向けに実装したPACX-MPIに関して紹介する。
また、米国でのスーパーハイウエー構想に関してI-WAY実験ネットワーク上で様々なツールが開発されてきた。Globusはこれらのツール群をとりまとめたプロジェクトであり、1997年に発足した。Globusプロジェクトはグローバルコンピューティングのソフトウェアインフラストラクチャを構築するためのツール群として近年非常に注目されているGlobus Metacomputing Toolkitの構築をはじめとし、短期間で数多くの実績を残している。現在ミドルウェア層に位置する多くのシステムが、何らかの形でGlobus Toolkitを利用するようになってきている。そこで、最後にGlobus Toolkitに関して紹介する。
【Ninf: ネットワーク数値情報ライブラリ】
いわゆるスーパーコンピュータ(スパコン)や大規模クラスタシステムなどの高性能計算システムは、そう簡単に手に入れられるものではない。日本でもそれらのシステムを導入している企業、研究機関、大学等は限られている。それら高性能計算システムの魅力は、何と言っても高い計算処理能力にある。大規模計算においてはスパコンを使えば数分、数時間で答えを求めることが可能となる。従来の分散処理は単に処理時間の短縮を求めていたが、こればかりではなく、高品質ソフトウェアを簡便に共有することが可能となる。例えばあるスパコンに搭載されている計算ライブラリを使えば、非常に精度の高い計算結果を得られるなどである。また、計算のみならず、同様なAPIによりどこかのサイトが保持している大規模データベースに手元の端末から簡単にアクセスする事も可能である。
このような要求を満たすシステム、つまり手元にある計算資源(PCやワークステーション)上でユーザインタフェースを提供し、遠隔地にある高性能計算機(スパコンなど)を利用するシステムのことをDatorr(Desktop Access to Remote Resources)という。NinfはこのDatorrシステムの1つであり、電子技術総合研究所で当初設計、開発された。現在はお茶の水女子大学、東京工業大学等とも共同で開発を行っている。
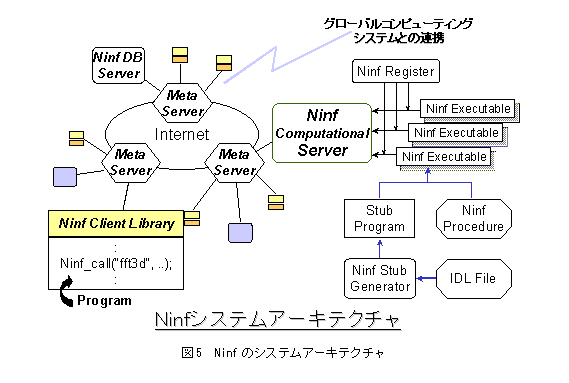 Ninfは広域ネットワーク上の数値計算ライブラリや科学技術計算に必要な数値情報データベースを通じて、主に科学技術計算分野の情報ならびに計算資源を提供・共有する仕組みを備えている。Ninfの基本システムはクライアント/サーバモデルに基づいて設計されており、図5に示すようにNinfクライアント、Ninfサーバ、要素ルーチン、メタサーバの4つの要素から構成される。
Ninfは広域ネットワーク上の数値計算ライブラリや科学技術計算に必要な数値情報データベースを通じて、主に科学技術計算分野の情報ならびに計算資源を提供・共有する仕組みを備えている。Ninfの基本システムはクライアント/サーバモデルに基づいて設計されており、図5に示すようにNinfクライアント、Ninfサーバ、要素ルーチン、メタサーバの4つの要素から構成される。
Ninfシステムは、「計算サービスを提供する側(サーバ)」に対し、手元の端末(クライアント)から計算要求を発信し、遠隔地にある計算資源を利用することを可能とするシステムである。しかも、サービスが増えた場合でも従来のSunRPC a等とは異なり、サーバ側だけで更新が行える。
【PACX-MPI: グローバルコンピューティング環境向けに実装されたMPI】
メッセージ通信を用いた並列プログラミングを広域分散システム上に展開するために標準的なMPIを拡張したものがPACX-MPIである。MPIは最も標準的でもっとも多く利用されているメッセージ通信ライブラリであり、C言語やFortranなどで利用することができる。MPIは利用する計算機のアーキテクチャに応じた方法でメッセージ通信を行うように実装部分が留保されている。例えば共有メモリ計算機においては、共有メモリを介したり、ネットワークで接続されたクラスタシステムにおいてはTCP/IPによる通信を利用したりするのと同様に広域分散システムにおけるMPIのデザインがいくつかある。ただし、MPIは元来グローバルコンピューティング環境を意識して実装されていたものがなく、既存のMPIをグローバルコンピューティング環境で利用するのはアーキテクチャの異なる計算機間での利用や遠隔システム上でジョブプロセスを生成する方法に関して障害があり、また性能の面においても問題がある。
PACX-MPIはドイツのHLRS(High Performance Computing Center Stuttgart)で開発された、グローバルコンピューティング環境向けに実装されたMPIである。PACX-MPIが提供するライブラリ関数のAPIやセマンティクスはMPIに準拠しており、MPIを使って書かれたプログラムならばソースコードに修正を加えることなく、PACX-MPIのライブラリをリンクすることにより広域分散コンピューティング環境でプログラムが動作。この場合、広域分散で問題になるのがネットワークの遅延に起因する性能である。例えばそれらの並列計算機がインターネットで接続されている場合、異なる計算機上で動くプロセス間ではTCP/IPを用いて通信することになる。一方、構成要素の並列計算機ノードには、その計算機固有の方法で高速なメッセージ通信を行なうことのできるMPIが実装されている。内部の通信とノード間の通信を区別し、性能を維持するためPACX-MPIは同じ計算機上で動作するプロセス間ではその計算機固有なMPIを使って通信し、異なる計算機上で動作するプロセス間ではTCP/IPを使って通信を行う。図6に計算機内部とノード間MPIの関係を示す。
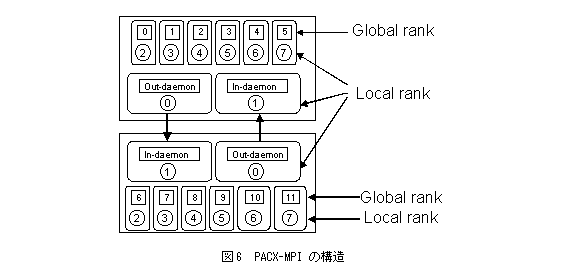
PACX-MPIは現在並列プログラミングの際に非常に多く用いられているMPIをソースコードレベルでの互換性を保ちつつ広域分散コンピューティング環境で効率良い動作を目指したシステムであり、次に述べるMPICH-G(MPICH on Globus Device)と並んで広域分散コンピューティング環境上でのプログラミングの標準である。
【Globus Metacomputing Toolkit】
NinfやPACX-MPIなどミドルウェア層に位置するシステムを構築するためには、ユーザ認証、通信、遠隔計算機上でのプロセス生成、計算資源に関する情報サービス等の要素技術が必要となる。個別ではなく共通のツール群の提供を目指し1996年頃に開始されたGlobusプロジェクトは並列・分散計算、ネットワーク、セキュリティといった様々な分野の研究者達が参加するプロジェクトである。現在も広域分散コンピューティングの分野におけるトップレベルの研究者達がこのプロジェクトに参加している。Globusプロジェクトの大きな産物の1つに、Globus Metacomputing Toolkit(以下Globus Toolkit)がある。Globus Toolkitはユーザ認証システム、通信ライブラリ、計算資源管理機構といった広域分散コンピューティングシステムの構築に必要とされる基本的なサービスの集まり(toolkit)である。Globus Toolkitが提供するツールを用いて上位レベル(ミドルウェア層など)にグローバルコンピューティングシステムを構築することができる。例えば、通信やユーザ認証にGlobus Toolkitを用いてMPICHを実装したMPICH-G(MPICH Globus Device)などがある。
前述のNinfもGlobus Toolkitが提供する通信ライブラリを使って実装したバージョンなどが存在する。このようにGlobus Toolkitは広域分散コンピューティングシステムに必要とされる様々な基本的サービスを提供しており、ソフトウェアインフラストラクチャの事実上の標準となってきている。
1998年10月にGlobus ToolkitのVersion 1.0.0がリリースされ、昨年12月にVersion 1.1.1がリリースされた。図7に、Globus Toolkitが提供するサービスの一覧を示す。
| サービス | 名前 | 概 要 |
| 資源管理 | GRAM | リソースの割り当ておよびプロセス生成 |
| 通信 | Nexus | Unicast/Multicast通信サービス |
| 情報 | MDS | システムの構造および状態に関する情報へのアクセス |
| セキュリティ | GSI | authenticationなどのセキュリティサービス |
| 状態管理 | HBM | システムの状況サービス |
| 遠隔データアクセス | GASS | データへのリモートアクセスサービス |
| 実行ファイル管理 | GEM | 実行ファイルの構築、キャッシングおよび配置 |
図7 Globus Toolkitのコアサービス
Globusが提供するこれらのサービスは必要に応じて個別に利用することができるようになっていて、既存のアプリケーションへのインクリメンタルな導入が可能となっている点が特徴的である。
3.3.2.4 ハイエンド計算におけるグローバルコンピューティング
ハイエンド計算において高性能計算機は一朝一夕には導入ができず、また利用技術を蓄積することが困難である。しかし、時代の流れとして、HPC技術のアウトソーシングが必須である。すなわち、通常はインハウスにあるパソコンや中規模サーバで普段の仕事をするが、ミッションクリティカルの局面ではどこか、まさに地理的、組織的にもどこかの計算能力資源への要求が高まる。この要求と余剰の計算能力を保有しているサーバ群との間でなんらかの受給を満たす市場原理が働くことが期待される。サーバ側はその余剰分に関する情報を交換用マーケットに流しておき、エージェントはクライアント側の計算資源要求をその質に応じて満足するよう振る舞う。なんらかの交渉メカニズムにより合意に達すればクライアントへサーバを紹介する。
サーバはクライアントを集めようと思えば、より高品位なサービスを提供することに努力をするであろう。例えば、裸のCPU利用権ではなく、ある特定のアプリケーションをパッケージにして利用のノウハウまで併せて提供するようになる。いわゆるASPのHPC版に近いイメージである。また、マーケットを成立させるためには、標準的な手順の確立が急務だと考えられる。これらを実現するにはグローバルコンピューティング技術が不可欠となる(図8)。
公的機関としてグローバルコンピューティングの市場機能を構築するニーズは緊急事態策として、緊急事態に陥った場合の危機管理体制下の準備をする必要がある。すなわち、例えば、ある事故により環境汚染が予想される場合には、これまでに計算された様々なシナリオと、現時点で得られる測定値を比較検討しながら、一刻も速い計算とその結果に対応させる対策が必要となる。こうした場合には、国内だけではなく、世界中へCPUを提供することによる貢献が期待される。また、それが可能となるようなシステムを構築するべきである。
3.3.2.5 グローバルコンピューティングテストベッド
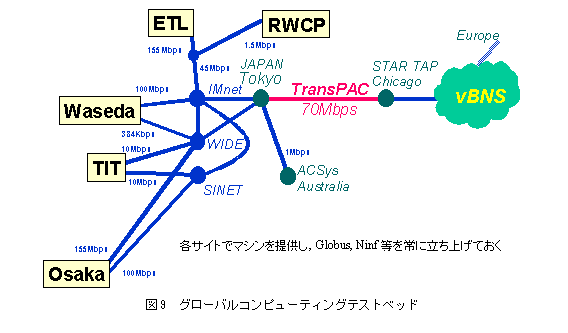
現状の問題点は研究者の絶対的な不足である。広域分散コンピューティングの関連技術を試験的に実行する環境が必要である。単にどこかのWWWサイトを訪れて、必要なソフトを持ってきて、インストールすれば済むほど単純ではない。少なくとも、計算サーバ、高速ネットワーク、クライアントの3者を維持することが必要である。すなわち、自分でサーバとクライアントを兼ねてしまっては本質的な広域分散コンピューティングではない。広域分散コンピューティング技術が発展するためには、魅力的なアプリケーションソフトや開発環境を維持提供し、多くのクライアントを抱えて、実際に有効性と利便性をユーザに展開しないといけない。
こうした開発を促進するには公共的サービスとして計算サーバ構築し、ネットワーク経由でアクセスしても常に安定した運営の継続が必要だと考える(図9)。計算サーバなどもある程度の計算能力がないと、クライアントユーザにとってはネットワーク経由でアクセスする魅力がない。これまでにもコンピューティングテストベッドの維持・構築を小規模で行ってきたが、広く使えるように整備が必要だと考えている。特に計算サーバを強化した大規模なテストベッドを構築し、多くのアプリケーションを創出することが、世界に対する貢献である。
グローバルコンピューティングはハイエンドコンピューティングの将来に必須な技術のひとつであり、かつ現在各地で精力的な研究開発が進められている。また国際的な協力関係が大きく期待される分野である。このため、国内におけるカウンタパートの設定はもとより、グローバルコンピューティングテストベッドを含めた国内の環境の整備、またaGrid ともいうべきアジア地区におけるテストベッドと研究開発を緊急に整備する必要がある。また、非常に動きの早い分野であるため、毎年定例になっている会合がいくつかある。今後定期的に開かれるであろうものはGrid Forum である。すでに昨年の6月と10月に開催され、参加者は150名くらいであるが、いくつかのワーキンググループに分散して最新情報の交換、標準化に関する議論を行っている。現在のワーキンググループは下記の9つである。
・ Scheduling Working Group(Sched-WG)
・ Grid Information Service Working Group(GIS-WG)
・ Security Working Group(Security-WG)
・ Remote Data Access Working Group(Data-WG)
・ Application and Tools Requirements Working Group(Apps-WG)
・ End-to-end Performance Working Group(Perf-WG)
・ Advanced Programming Models Working Group(Models-WG)
・ Account Management Working Group(Accounts-WG)
・ User Services Working Group(Users-WG)
2000年度のグローバルコンピューティング関連会議の予定では下記のものがあり、いずれもフォローを続ける必要があると考える。
・ 3/15-17 グローバルとクラスタコンピューティングに関するワークショップ (WGCC2000)、つくば市
・ 3/22-24グリッドフォーラム(Grid Forum)、米国サンディエゴ市
・ 7/10-12グリッドフォーラム、米国レッドモンド市
・ 7/18-21インターネットカンファレンス (INET2000)、横浜パシフィコ
・11/4-10 SC2000、米国ダラス市
3.3.3 大規模並列シミュレーションのためのHigh Level Architecture
古市昌一 委員
3.3.3.1 はじめに
現代社会において、計算機とネットワークは水道や電気と同様社会基盤として重要な役割を果たしている。その中でも最も重要な役割は、人と人、人とシステム、システムとシステムの間のコミュニケーションのための道具としての利用であろう。その次に重要なのは、多様で複雑化するシステムを効率良く設計・製造し、運用開始後における教育・訓練において必須となる、シミュレーションを行うための道具としての利用であると考える。以下に計算機シミュレーションの目的を分類した例を示す。
・自然および物理現象の解明や予測:風洞実験、気象予測、宇宙の進化など
・システムや社会現象の解明や予測:道路交通、株取引、戦略など
・教育および訓練、エンタテイメント:フライトシミュレータ、ゲームなど
シミュレーションを利用する理由は、1)実際に実現するのが不可能、2)安全性や予算面で現実的に実現するのが不可能、3)一度しか操作を実現できず、繰り返し経験を積むことが重要、などが考えられる。
ここで、例えばある自治体が新しい空港の建設を計画した場合のシナリオを考えてみる。すると、以下に列挙するように新空港の開港までには様々な目的でシミュレーションが行われ、各種のシミュレータを用いて解析や訓練が繰り返されるであろう。更に、運用開始後も引き続きシミュレーション技術が活用されることになると予測される。
・空港ビルの構造解析シミュレータによる強度評価
・道路交通シミュレータによる周辺道路の渋滞予測と、新道路建設計画立案
・航空交通流シミュレータによる滑走路長と本数の立案
・避難シミュレータによる空港ターミナルの避難誘導路の立案
・航空管制官の訓練用シミュレータによる管制官の訓練
・旅客機の操縦シミュレータによるパイロットの新空港離着陸訓練
・気象予報や乱気流予測シミュレータによる航空管制業務支援
このように、新空港建設一つを例としても様々な種類の計算機シミュレーションが不可欠であり、今後もシミュレーション技術の発展と実行用計算機の性能向上に対する要求はとどまることがない。
計算機の性能向上は、プロセッサの性能向上と並列処理技術の発展が期待できる。しかし、今後益々多様化するシミュレーションシステムをその都度新規に開発していては、開発コストが増すばかりで効率良いシステム開発を行うことはできない。
例えば、米国国防総省においては長年に渡って多数の解析評価用や訓練用のシミュレーションシステムを開発し、1998 年3 月の時点では約800 種類が実際に運用中だと報告されている[1]。
東西冷戦終結後の米国では、防衛産業の民需転換と国際競争力の強化を目的とし、国防予算の多くが情報産業の育成に注入されている。特に、1995 年に出された"Modeling and Simulation Master Plan"[2] 以降、モデリング&シミュレーション技術の育成に対する投資額が大幅に増大し、結果として軍隊の近代化を促すと同時に、今日の米国情報技術(IT) 産業の隆盛となって効果が現れているのは間違いないであろう。
そこで、本報告では米国におけるモデリング& シミュレーション技術の育成の中核となって現在研究開発が進行中の、HLA(High Level Architecture) の紹介を通して、HECC のアプリケーション分野の一つとしての並列分散シミュレーション技術に関して考察する。
3.3.3.2 High Level Architecture
HLA は1995 年に米国国防総省が提案し[3,4]、SISO(Simulation Interoperability Standardization Organization)[5] が中心となってIEEE 1516 標準化[6] が推進されている、異機種シミュレーションシステム間の接続仕様である。特に、多種多様なシミュレーションシステムが利用されている防衛分野において、システムの再利用性と相互接続性を高め、今後の開発・保守コストを低減できるという効果があると共に、他の多くの分野においても同様の効果を期待することができる。
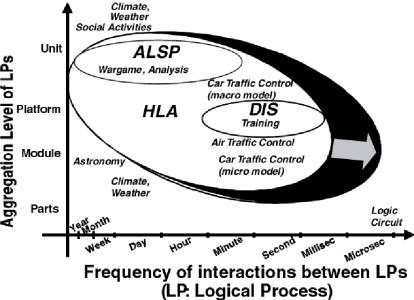
図1にHLAが対象とするアプリケーション分野を示す。図中DIS(Distributed Interactive Simulation)[7, 8]とALSP(Aggregate Level Simulation Protocol)[9]はそれぞれ現在防衛用の分散シミュレーションシステムで使われている接続仕様で、米国国防総省下で現在利用されている全てのシステムは、2000年度中にHLA化が完了するよう作業が進められている。
|
図1 HLAが対象とするアプリケーションドメイン |
元来HLAは既存の異機種シミュレータを多数共通の接続仕様で連接し、全体として一つの分散協調型シミュレータとして機能させるためのアーキテクチャである。一方、大規模なシミュレーションプログラムを分散計算機環境や共有メモリ型の並列計算機上で実行するための、論理プロセス(LP)間の同期とデータ交換プロトコルとしてHLAを利用しようという研究もなされている[10, 11, 12, 13]。これらの研究により、将来的には図1中黒く塗った部分に対象アプリケーションが拡大されるものと予想される。
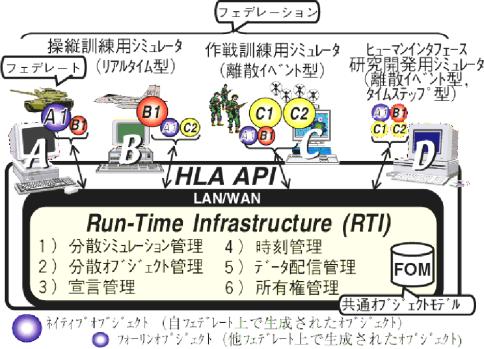
図2に、HLAに基づく分散シミュレーションシステム(HLAではフェデレーションと呼ぶ)の構成を示す。図中、HLAに準拠した各シミュレータ(HLAではフェデレートと呼ぶ)は、ネットワークを介して接続された他のフェデレートと、それぞれ共通のAPI(Application Program Interface)を用いて通信及び同期を行う。APIの下位では、HLAインタフェース仕様書[6]により規定された各サービス(通信)を実行するためのRTIと呼ぶソフトウェアが動作する。
HLAではRTIの実装方式は規定されておらず、DMSO (Defense Modeling and Simulation Office) が開発してフリーで利用できるDMSO-RTI1.3および1.3NG[14,15] を代表に、eRTI[16,17]、pRTI[18] やJavelin[19]などが知られている。
フェデレートとRTI間のサービスとしては、シミュレーション管理機能やオブジェクト管理機能をはじめとして、図2に記載した6種類が規定されている。
HLAの特長は、各フェデレートは他に対して公開するクラスと属性をRTIに対して宣言し、また自分が必要とするクラスと属性を購読宣言することにより、フェデレート間では互いに相手の所在や論理時刻の違いを意識することなく、RTIにより通信と同期が行われる点である。例えば、図2でシミュレータA がクラスB1の購読宣言をしておくと、シミュレータB上でクラスB1のインスタンスオブジェクトが生成されるとRTIからB1の生成が通知され、B1を参照することが可能となる。
HLAと同様にオブジェクト指向で分散システムを構築するための標準仕様としては、CORBA(Common Object Request Broker)があるが、分散シミュレーションでは必須の時刻管理機能と、オブジェクトの所有権管理機能がCORBAには備わっていないため、これらをアプリケーションプログラム側で実現する必要がある[20]。
|
図2 分散シミュレーション統合アーキテクチャHLA |
3.3.3.3 アプリケーション例
(1)JSIMS: Joint Simulation System
従来より米国国防総省において指揮幕僚訓練で用いられているシミュレータは、陸・海・空軍それぞれで全く異なるシステムが用いられてきた。しかし、近年各軍は共同で作戦を実施する機会が増えており、また、今後システムの改良や拡張をする上でも、できる限り仮想訓練環境は統一するのが望ましいと考えられている。
そこで、HLAが提案されるとほぼ同時期に研究開発が始まったのがJSIMS(図3)である。JSIMSの基本的な概念は、訓練用のシミュレータ、人工知能を応用したSynthetic Forcesと、実際の指揮統制システムが同一の仮想環境を共有し、遠隔地に所在する多数の訓練生が同時に訓練を実施することができるための環境を構築することである。
(2)SBA: Simulation Based Acquisition
ゴア米国副大統領のNPR(National Partnership for Reinventing Government)[21] では、調達コストの25%削減を目標として掲げている。これに基づき、米国国防総省では調達のサイクルタイムの半減と発注者側の総コスト削減を目指している。そのためのキーとなるのが官民連携による調達におけるシミュレーションの活用である。
具体的には、デジタルモックアップ(DMU)の技術により、試作品を作ることなく、コンピュータ内部に構築したCADモデルとその可視化(ビジュアライゼーション)ツールを駆使して、部品の組立や製品の運用、補修等の模擬を繰り返すことが可能となる。これにより、新製品の開発期間が劇的に短縮され、コストを大幅に削減することができる。
|
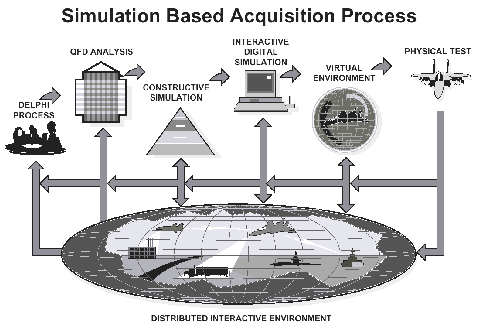
図4 SBA (http://www.dsmc.dsm.mil/pubs/mfrpts/mrfr10a.htm のpp.4-4 より引用) |
図4にはDSMC(Defense Systems Management College)が作成した"Simulation Based Acquisition: A New Approach" (4-4 ページ)[22] の図を引用する。図からわかるように、例えば航空機を開発する過程において、設計、製造、操作系の評価、訓練、フライト試験に至るまで全てのフェーズは同一の分散協調型シミュレーション環境を共有し、各フェーズ間でデータ交換を行う。更に、フェーズ間を逆戻りすることも可能とすることにより、スパイラルな開発による柔軟なシステム開発を可能としている。
米国国防総省では、全ての調達品にSBA手法を適用すべく整備を進めており、シミュレータ間の連接とデータ共有の部分でHLAを利用することから、HLAの応用として最も巨大なアプリケーションの一つとして育とうとしている。
3.3.3.4 おわりに
HECCのアプリケーション分野の一つとしてHLAをとらえ、HLAの概要を紹介するとともに、現在米国国防総省下で研究開発が進行中のアプリケーションの一部を紹介した。しかしながら、ここで紹介したアプリケーションは多数の異機種シミュレータを連接するための技術としてHLAを利用した例であり、大規模並列分散シミュレーションの具体的事例紹介とはなっていない。これは、HLAを大規模並列分散シミュレーションの基盤として使うために必須の、実用的な性能を得られるHLA-RTIがまだ開発途上にあることと、プログラミング環境がまだ整備されてないからである。
既に、米国においては主要なシミュレーションシステム開発支援ツールのHLA化が実現され、欧州のNATO加盟各国や極東アジア諸国でHLAに関する研究が大変盛んになっている。一方、国内においてはHLAに関する研究開発例は大変少ないのが現状である。今後シミュレーション技術が益々重要になる中、HECCのアプリケーションとしてHLAは重要な位置を占めると考える。
参考文献
[1] Defense Modeling and Simulation Office: HLA Architecture Management Group Home page, http://hla.dmso.mil/amg/meetings/ (2000).
[2] Under Secretary of Defense for Acquisition and Technology: DoD 5000.59-P Modeling and Simulation Master Plan, Department of Defense,
http://www.dmso.mil/documents/ (1995).
[3] Dahmann, J. S., Calvin, J. O. and Weatherly, R. M.: A Reusable Architecture for SIMULATIONS, Communications of the ACM, Vol. 42, pp. 79-84(1999).
[4] Fujimoto, R.:Parallel and Distributed Simulation Systems, John Wiley & Sons,Inc., pp. 209-221 (2000).
[5] SISO: Simulation Interoperability Standardization Organization,
http://www.sisostds.org (2000).
[6] IEEE Std P1516: Draft Standard for Modeling and Simulation HLA -Federate Interface Specification-, http://www.sisostds.org/doclib/ (1998).
[7] IEEE Std 1278-1995: Standard for Information Technology, Protocols for Distributed Interactive Simulation, IEEE (1995).
[8] Hofer, R. C. and Loper, M. L.: DIS Today, Proc. of the IEEE, Vol. 83, pp. 1124-1137 (1995).
[9] Banks, J.: Handbook of Simulation -Principles, Methodology, Advances, Applications and Practice-, John Wiley & Sons, Inc., pp. 645-658 (1998).
[10] Mellon, L. and Itkin, D.: Cluster Computing in Large Scale Simulation, Proc. of the 1998, Fall Simulation Interoperability Workshop, pp. 1119-1127 (1998).
[11] Furuichi, M., Mizuno, M., Izumi, H., Ozaki, A., Takahashi, K., Satou, H., Matsukawa,H. and Aoyama, K.: The Applicability of High Level Architecture to Large Scale Parallel and Distributed Simulation, Proc. of the '99 Spring Simulation Interoperability Workshop, Vol. 2, pp. 466-473 (1999).
[12] Ferenci, S. L. and Fujimoto, R.:RTI Performance on Shared Memory and Message Passing Architecture, Proc. of the '99 Spring SIW Workshop (1999).
[13] Christensen, P. J., Hook, D. J. V. and Wolfson, H. M.: HLA RTI Shared Memory Communication, Proc. of the '99 Spring SIW Workshop , Vol. 2, pp. 571-574 (1999).
[14] Bachinsky, S.T., Mellon, L., Tarbox, G. H. and Fujimoto,R.: RTI2.0 Architecture, Proc. of the '98 Spring SIW Workshop, Vol. 2, pp. 871-880 (1998).
[15] Defense Modeling and Simulation Office: High Level Architecture Run-Time Infrastructure RTI 1.3-Next Generation Programmer's Guide,
http://www.dmso.mil/hla/ (1999).
[16] Furuichi, M., Mizuno, M., Miyata, H., Miyazawa, M., Matsumoto, S. and Aoyama,K.: Design and Implementation of Experimental HLA-RTI Without Employing CORBA, Proc. of the 15th DIS Workshop, Vol. I, pp. 195-201 (1996).
[17] Furuichi, M., Mizuno, M. and Miyata,H.: Performance Evaluation Model of HLA-RTI and Evaluation Result of eRTI, Proc. of the '97 Fall Simulation Interoperability Workshop, Vol. II, pp. 1099-1109 (1997).
[18] Pitch Inc.: pRTI (portable RTI) Pro duct Information, http://www.pitch.se/prti (1999).
[19] Myjak, M. D., Sharp, S. and Briggs, K.: Javelin,Proc. of the '99 Spring SIW Workshop, Vol. 3, pp. 999-1007 (1999).
[20] 服部吉洋, 林富彦, 郡司勝, 村上栄一郎, 二宮勉, 宮園道明: CORBAを利用した分散協調型シミュレーション基盤, オブジェクト指向'97 シンポジウム, pp. 3-10 (1997).
[21] NPR: National Partnership for Reinventing Government, http://www.npr.gov (2000).
[22] Defense Systems Management College: Simulation Based Acquisition: A New Approach,http://www.dsmc.dsm.mil/pubs/mfrpts/mrfr10a.htm, pp. 4-4 (1998).