中島 浩 委員
PIM(Processor-In-Memory)アーキテクチャとは、近年のプロセッサ/メモリ混載技術を活用し、メモリ・チップ上に(比較的小規模の)プロセッサを搭載して、メモリ機能の高度化を図ろうというものである。したがってPPRAMなどのプロセッサ/メモリ混載アーキテクチャがどちらかと言えばプロセッサを主体とする(Large)Memory on Processor Chipであるのに対し、メモリが主体という点でMBPやFLASHなどの所謂プロトコル・プロセッサと近親性がある。ただし、これらのプロセッサでは(実装上の制約もあって)メモリ・バンド幅がさほど大きくないのに対し、PIMではチップ内の大きなバンド幅を生かすようなアプローチとなっている点が異なる。
さて、PIMが目的としているメモリ機能の高度化について、HECC-WGの前身であるPeta-FLOPS WGの平成9年度報告書において、筆者は「メモリ・アーキテクチャの展望と課題」と題して、以下のような議論を行った[1]。すなわち、
・超大容量メモリの必要性
・演算/メモリ・スループットのバランス確保
・von Neumann bottleneckの存在
を前提とするならば、von Neumann bottleneckの解消/緩和がPeta-FLOPSアーキテクチャの鍵であり、そのためにはbottleneck通過物(現状ではアドレスやデータ)の変質が必要であると主張した。またその候補となるアーキテクチャとして、以下の三つのものを取り上げて議論した。
(1)Visible Memory System
キャッシュに代表される不可視のメモリ・システム要素を可視化し、何らかの制御を可能とするアーキテクチャとしてJUMP-1 [2] などを取り上げ、可視要素を含む非均一メモリ・システムの統一的ビューの設定がソフトウェアによる安定的利用に不可欠であると主張した。その後SCIMA [3] をはじめとして、メモリ性能の向上を目的とした種々の可視メモリ要素が提案されているが、統一的ビューの設定に関する提案は見られない。
(2)Memory with Program
プログラム実行のための制御機能の一部をメモリに移管する先鋭的アプローチとしてUPCHMS [4] を取り上げ、アクセスのためにメモリに渡される情報をアドレス列よりも十分小さくできる可能性を議論した。
(3)Code(PC)Flow Model
(2)をさらに発展させたアプローチとして、メモリ上の個々のオブジェクト(あるいはオブジェクトの集合)が固有のプロセッサを持ち、プログラム・コード(あるいはプログラム・カウンタ)と実行コンテクストの組がオブジェクト間を移動するようなモデルを提言した。
今回の報告でProcessor-In-Memory(PIM)アーキテクチャについて議論するために、最近の研究動向を調査したところ、上記の(2)や(3)のアプローチに基づくものが見出され、2年前の提言が必ずしも的外れではなかったことが明らかになった。以下、(2)についてはVeidenbaumらによるDA-DRAM [5,6] を、また(3)についてはHTMTアーキテクチャにおけるsmart RAM [7,8,9] を例にとって議論する。
3.2.1.1 DA-DRAM
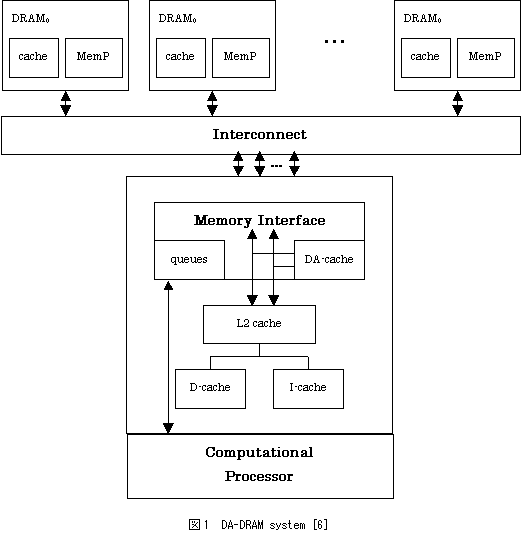
DA-DRAM(Decoupled Access DRAM)は、現在の高性能uniprocessor systemをさらに高性能化することを主な目的としたもので(マルチプロセッサについても可能性は否定していない)、図1に示すように計算の主体である1個のcomputational processor(ComP)と、メモリ・アクセスのためのプロセッサであるmemory processor (MemP)を持つ複数のDRAMから構成される。ComPはsuperscalerなどのような一般的なプロセッサであり、キャッシュあるいはキューを介してMemPとの間の通信を行う。MemPは単純な整数プロセッサであり、アドレス計算を含むメモリ・アクセス操作全般(特に読出)を担当し、ComP が必要とするデータをプログラムの先行実行によってプリフェッチしてComPに供給する。
ComPとMemPの間の通信をキャッシュ/キューのどちらを経由して行うかは、アドレス計算の複雑さによって決定される。スカラあるいは配列要素のように比較的単純にアドレスが求まる場合には、ComPとMemPの双方でアドレス計算を行い、データはキャッシュを介して受け渡される。たとえば
for (i=0;i<N;i++) y[i]=a*x[i]+y[i];
は、以下のようにComP/MemPで分担実行される。
MemP ComP
for (i=0;i<N;i++) { for (i=0;i<N;i++) {
send_to_cache(x[i]); X=recv_from_cache(x[i]);
send_to_cache(y[i]); Y=recv_from_cache(y[i]);
y[i]=a*X+Y;
} }
この例でのキャッシュの役割はデータの再利用というよりもむしろaddressableなバッファである。また再利用を考える場合も、データの存在が確定的ではないキャッシュよりも、UPCHMSやSCIMAのように高速バッファ・メモリを用いるほうが勝るのではないかと思われる(UPCHMSのようにバッファにもプロセッサを置く必要はなかろうが)。
なお、この例では明らかにMemPにおけるメモリ・アクセス・スループットがComPでの演算スループットよりも大きく劣るが、このスループット差は複数のMemPが並列実行する一種のインタリーブによって補われる。M個のMemPにより並列実行するには、個々のMemPが
for (i=m;i<N;i+=M) {
send_to_cache(x[i]);
send_to_cache(y[i]);
}
のように、サイクリック分割に基づく並列化コードを実行すればよい。しかし [5] ではより単純に
for (i=0;i<N;i++) {
if (is_local(&x[i])) send_to_cache(x[i]);
if (is_local(&y[i])) send_to_cache(y[i]);
}
という一種のSIMD的な実行で十分であると主張している。
一方上記のプログラムは、以下のようにキューを使った通信によっても実現できる。
MemP ComP
for (i=0;i<N;i++) { for (i=0;i<N;i++) {
send_to_queue(x[i]); X=recv_from_queue();
send_to_queue(y[i]); Y=recv_from_queue();
y[i]=a*X+Y;
} }
このキューを使った通信は、アドレス計算が複雑である場合により有効であると [6] では主張している。すなわち複雑なアドレス計算は(若干奇異に思えるかもしれないが)MemP で行い、ComPには計算すべきデータのみが送られる。たとえば以下のような疎行列Aと密ベクトルVの乗算を考える。
for (i=0;i<N;i++) {
ip=0.0;
for (j=head[i];j<head[i+1];j++)
ip=ip+As[j]*V[idx[j]];
AV[i]=ip;
}
この例ではAのi 行目の非零要素がAs[head[i]]から連続して格納されており、As[j]の列番号はidx[j]に保持されている。このプログラムでは、Vの要素のアドレス計算にインデックス配列参照が必要であるため、以下に示すようにアドレス計算はMemPのみが行い、ComPはキューを介してデータを受け取る。
MemP ComP
send_to_queue(head[0]); h1 recv_from_queue();
for (i=0;i<N;i++) { for (i=0;i<N;i++) {
ip=0.0;
send_to_queue(head[i+1]); h2=recv_from_queue();
for (j=head[i];j<head[i+1];j++) { for (j=h1;j<h2;j++) {
send_to_queue(As[j]); a=recv_from_queue();
send_to_queue(V[idx[j]]); v=recv_from_queue();
ip=ip+a*v;
} }
AV[i]=ip;
h1=h2;
} }
この例についてのMemPの並列実行も、前述のSIMD的なやり方で行うことができる。ただしV[idx[j]]のアクセスはidx[j]を保持するMemPが行う必要があり、そのため一般には遠隔アクセスとなる。
リスト構造のようなポインタを用いたアクセスについては [5,6] では触れられていないが、たとえば
for (p=head;p!=NULL;p=p->next)
compute(p->elem);
のようなプログラムを
MemP ComP
send_to_queue(head); p=recv_from_queue();
for (p=head;p!=NULL;p=p->next) { for (;p!=NULL;) {
send_to_queue(p->elem); e=recv_from_queue();
compute(e);
bloadcast(p->next); p=recv_from_queue();
} }
のようにMemP間でも通信を行いながら実行することは可能であろう。
さて、上記のプログラムは全て、MemPが制御フローを完全に把握できるものである。しかしComPによる演算結果に制御フローが依存する場合、たとえば
while (e>eth) { ...; e=...; }
のような収束計算を行う場合、MemPのComPに対する制御依存による遅延が問題となる。そこで [6] では、MemPが多重分岐予測を行うことによって、制御依存遅延の問題を解決できると主張している。すなわち上記のループを
ComP MemP
while (pred(TC)) { while (e>eth) {
... ...
TC=!(e>eth);
} }
として実行し、分岐予測(pred(TC))の精度が高ければ、十分な性能が得られるとしている。精度について [6] では、過去18回の分岐履歴に基づいて8つ先の分岐を予測した場合、70〜80%程度の正解率であることを示している。
 |
3.2.1.2 Smart RAM
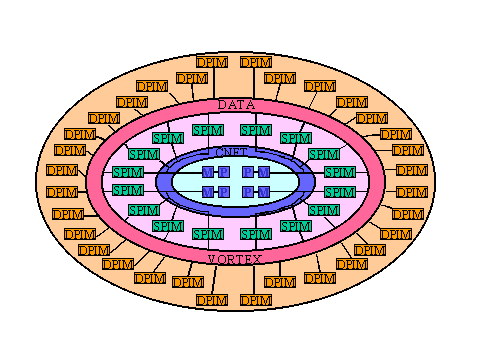
Smart RAMはHTMT(Hybrid Technology Multi-Threaded Architecture)[7,8,9]の構成要素である。HTMTは図2に示すように
・超伝導素子RSFQ(Rapid Single Flux Quantum)で構成された66GHzのプロセッサSPELL
・超伝導素子で構成された1MBの高速RAM(CRAM)
・PIMアーキテクチャによる4×64MBのsmart SRAM(SPIM)のクラスタ
・PIMアーキテクチャによる8×512MBのsmart DRAM(DPIM)のクラスタ
から構成されている。これらは全て4,096個ずつ存在し、以下のネットワークにより相互接続される。
・SPELL-CRAM間:2TB/secのRSFQ
・SPELL/CRAM相互:512GB/secのCNET
・SPELL/CRAM-SPIM間:160GB/secのCNET
・SPIM-DPIM間および相互:80GB/secの光ファイバ(Data Vortex)
図2 HTMT アーキテクチャの概要 [7]
SPIM/DPIMには、SPELLとSRAM/DRAMの間のレイテンシ隠蔽を目的として、それぞれ固有のプロセッサが搭載されている。プロセッサはASAP(At the Sense Amps Processor)と呼ばれ、その名のとおりRAMモジュールのセンスアンプ入出力に直結され、大きなアクセスバンド幅([7]によれば 1K bit)を活用できるようにしている。プロセッサの詳細な構成は「データフローのアレイとマルチスレッドCPUの組合せ」[9]という程度しかわからないが、SIMDやVLIW的な操作に対応できるものであるという。
PIM 相互およびPIMとSPELLの間の通信は、parcel(Parallel Communication Elements)と呼ばれる高機能メッセージによって行われる。parcelはメモリ上のオブジェクトに宛てたメソッドとみなすことができ、PIMやSPELLによってスレッドとして実行される。このparcelを用いたDRAM ⇔ SRAM ⇔ CRAM のデータ転送はpercolationと呼ばれる。
たとえば [7] に示された行列積C = A ×Bの例ではM ×M の行列Aのpercolationは以下のように行われる(図3)。
(1)Aはt 2 個の小行列Ai,j に分割され、Ai,j はさらにs 2個の小行列aα,β に分割される。
図3 HTMT による行列積での percolation [7]
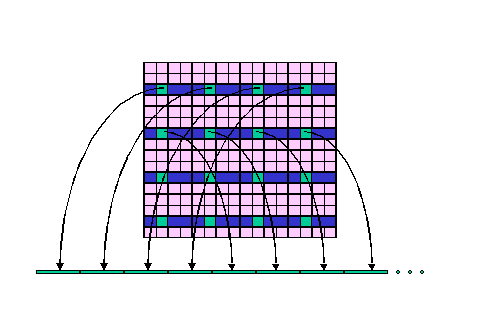
(1)一つのDRAMにはα = m (mod s)なるaα,β が全て格納される。
(2)一つのSRAMにはα = m (mod s )かつβ = n(mod s )なるaα,β がDRAMから「内向きに」percolation される。
(3)一つのSPELLはα = n(mod s )かつβ = n (mod s )なる C の小行列cα,β の生成を担当し、aα,β とbα,β がSRAMから「内向きに」percolationされる。
(4)小行列、aα,β とbα,β は隣接するSPELL間で循環的にシフトされ、Ci,j,k = Ai,k×Bk,j の乗算が行われる。これを全ての k について繰り返すことによりCi,j が求められる。
[7]では前述のRAM容量に基づき、M = t × s ×125 = 26×64×125 = 208,000とし、かつRAMのアクセス時間とSPELLの演算スループットについて以下の仮定を置いて、HTMTの行列積性能を見積もっている。
・DRAM : 7cycle@450MHz / 1K-bit = 0.97ns / W
・SRAM : 3cycle@450MHz / 1K-bit = 0.42ns / W
・SPELL : 5FLOP / cycle@66GHz = 330GFLOPS
見積もりの結果は1.1 PFLOPSとなり、ピーク性能である1.35 PFLOPSの約80 % が得られると主張している。
3.2.1.3 まとめ
今回の報告では、PIMを用いた高性能計算の例として、DA-DRAMとHTMTについて述べた。どちらのアーキテクチャもvon Neumannボトルネックを通過する情報を変質させることによりボトルネックの緩和を図っており、[1]で示した展望に添った形で研究が進められていることは興味深い。
これらのアーキテクチャの有効性についての検討は現時点では十分でなく、一般的に高性能計算に有用であると立証されているわけではない。特に一般性について、今後どのように研究が展開するかを見守っていく必要があろう。
参考文献
[1] 中島浩:メモリ・アーキテクチャの展望と課題、ペタフロップスマシン技術に関する調査研究、3.1.4節,pp. 54-60, Mar. 1998.
[2] 五島正裕,森眞一郎,中島浩,富田眞治:Virtual Queue: 超並列計算機向きメッセージ通信機構,情報処理学会論文誌,Vol. 37, No. 7, pp. 1399-1408, Jul. 1996.
[3] 大河原英喜,中村宏,吉江友照,金谷和至:ハイパフォーマンスコンピューティングに適したメモリ階層の初期評価,情報処理学会ARC 研究報告,ARC-133-10, Mar. 1999.
[4] 牧晋広,岡本秀輔,曽和将容:ユーザプログラム制御階層メモリシステム,情報処理学会論文誌,Vol. 37, No. 10, pp.1512-1526, Oct. 1996.
[5] A. V. Veidenbaum and K. A. Gallivan : Decoupled Access DRAM Architecture, IWIA’97, Oct. 1997.
[6] A. V. Veridenbaum : Increasing the Lookahead of Multilevel Branch Prediction, IWIA’98, Oct. 1998.
[7] J. Nelson, G. R. Gao, P. Merkey, T. Sterling, Z. Ruis and S. Ryan : Performance Prediction for the HTMT: A Programming Example, TFP’99, Feb. 1999.
[8] K. B. Theobald, G. R. Gao and T. L. Sterling : Superconducting Processors for HTMT: Issues and Challenges, FRONTIERS’99, Feb. 1999.
[9] P. Kogge, PIM Architecture to Support Petaflops Level Computation in the HTMT Machine, IWIA’99, Nov. 1999.
天野英晴 委員
3.2.2.1 はじめに
近年のコンピュータは、ハイエンドのスーパコンピュータの性能の向上もさることながら、一般のユーザが広く使うことのできるPCの性能の向上が著しいことが特徴である。このため、一時代前のスーパコンピュータ並の性能を持つPCを個人が利用することが可能となり、マルチメディア処理の発達とコンピュータの利用形態の変化をもたらしている。
これが可能になったのは、CMOS LSIの高速化と高集積化が、ECLを中心としたスーパコンピュータの実装技術に迫る域に達しつつあることによる。ECLを用いたスーパコンピュータの実装技術は、性能だけを考えると、現在の高速PCのCPUが達成した性能を、ずっと前に実現したのだが、サイズ、消費電力、コストを考えると一般ユーザが広く用いることができるような代物ではなかった。すなわち、近年急激に進んだのは、スーパコンピューティングの大衆化であるといえる。
一方で、高速スイッチとリンクについても似たような傾向が現れている。従来から転送速度が1Gbpsに及ぶリンクとスイッチは、GaAsやECL等の技術を用いれば実現可能であった。しかし、これらのスイッチは特殊な基板と実装技術を必要とし、コスト的にも数千万円のレベルであり、主にATM交換器として特定の基地局に装備されるものであった。
ところが、最近は、これと同等の交換能力を持つスイッチが純粋なCMOSの技術で実現可能となり、PCと同様の個人レベルで用いることができるようになりつつある。しかも、この周辺の技術に関しては日本は、かなりの域に達しており、世界を主導することができる位置にいる。本稿では、高速スイッチとリンクについて、最近の状況をまとめると共に、筆者が共同開発しているRHiNETについて紹介する。
3.2.2.2 最近の高速スイッチの状況
3.2.2.2.1 高速スイッチのそれぞれの分野
高速スイッチ、高速リンクは、主として以下の分野で開発されている。
(1)高速計算機のComponentとして: 大型計算機、大規模並列計算機などで、構成要素を接続するため用いられる。一つのComponentで多数用いる場合は、コストはある程度制限される。以下のような例が挙げられる。短距離の転送なので、bit幅が大きめで、周波数帯は200MHz程度。両方向同時転送が可能である。デッドロックを防ぐための仮想チャネルが複数装備され、場合によっては適応型ルーティングも備えている。高機能なスイッチが多いが、接続形態はメッシュ等簡単な形で済む。
SGI SPIDER: 20bit幅で200MHz、両方向同時、両エッヂ転送。8Gbps
Intel Cavallino: 16bit幅で200MHz、両方向同時転送。3.2Gbps
SR2200: ハイパクロスバ用スイッチ 10Gbps
(2)ATMスイッチ: 電話交換網、広域ネットワークに用いられるAsynchronous Transfer Modeのパケット(セル)を交換するスイッチ。スイッチ自体の交換能力よりも、バッファの位置(入力か出力か、両方に置くか)、バッファ容量、制御方法が問題になる。パケットの種類により廃棄可能かどうか等の転送の質を保証するのが最近のスイッチの特色である。
NTT ATMスイッチ: 単体のスイッチは2.5Gbps4x4だが、MCM(Multi-Chip Module)の利用により10Gbpsの転送速度を実現。
Si/SiGe CPSスイッチ: 特殊トランジスタの利用により10Gbpsのリンクを4本交換可能。
(3)Cluster Computing, Local Computer Network用: PC/WSを接続するためのスイッチ、リンク。かつては、低速のものが多かったが、最近は高速化が進んでいる。柔軟に接続できる可能性がある。
Myrinet SW: クラスタ構成用のSAN(System Area Network)として広く用いられている。
16 x 16のスイッチで、各リンクは、リンクにはリボン状のケーブルで9bit幅で80MHzで動作し、1.2Gbpsを実現する。
RHiNET-1/SW: 机上に普通に用いられているPCを接続して大規模計算を行なうシステム。光ケーブルあるいはGigabit Ethernet用ケーブルを用いる。9bit幅で133MHz, 1.4Gbpsのリンクを8入出力交換する。
RHiNET-2/SW: RHiNET-1/SWの高速版。詳細は後述。
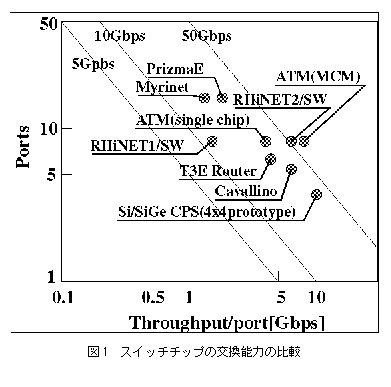
これらのスイッチをまとめて図1に示す。右方向ほどそれぞれのリンクの転送容量が大きく、上方に行くほど交換するリンク数が多い。リンク当たりの転送容量は10Gbpsに達し、交換リンク数は4-16である。
3.2.2.2.2 注目の高速化技術
3.2.2.2.1で紹介したように、現状ではリンクの転送周波数はだいたい800MHz-1GHz程度まで可能になっているが、これは(1)リンクの転送速度の限界(2)スイッチの交換性能の限界による。
(1)リンク転送速度
リンク転送速度は、転送周波数が上がるにつれ、Component内といえどもある程度の距離が必要な場合は、光転送技術が有望となる。米国の光転送技術開発プログラムであるOMNET Program[1]は、以下の技術に重点を置いている。
(a)Parallel Optics: リボンケーブルを用いて並列転送を行なう(もちろんクロックも同じケーブルで送る)。高速転送時にはbit間のSkewが問題となる。短距離転送向き。OMNET Programでは1.25Gbpsの転送速度で12bitの転送を実現している。
(b)Wide WDM: Wavelength Division Multiplexing、すなわち一本のケーブル上に異なる複数の波長の光を載せる技術。2.5Gbpsで1280/1300/1320/1340nmの4波長を載せることが目標である。
(2)スイッチの交換性能
いかに高速スイッチを用いても、800MHz-1GHzの転送速度でやってくるパケットをそのまま交換できるはずはなく、Elastic Bufferで周波数揺らぎを抑え、Demultiplexerでbit幅を大きくする代わりに周波数を落す。多くの場合、200MHzまで周波数を落してスイッチを行なう。しかし、この方法では1GMz以上は難しい。
(a)光スイッチの利用: 光転送を行なうのならば電気的に変換しなければ、速度を落す必要はない。しかし、光スイッチの利用は、光の減衰の問題等で周波数が1Gbpsに達するような場合はまだ困難である。
(b)特殊半導体の利用: Si/SiGe HBT(Heterogeneous Binary Transistor)Technology[2]は、トランジスタの片方のSi領域にGeをDopingする新しいトランジスタの方式である。高速だけではなく、低電力に特徴があり、8GHzで4入出力のスイッチで2Wの消費電力を実現可能である。
3.2.2.2.3 Information Technology Frontiers for a New Millenniumを読んで
米国の将来技術の発展の方向を示すドキュメントの中で、高速スイッチ、リンクに関する記述は、少なく、かつむしろConservativeであるように思える。
(1)High-end Hardware Component: 超伝導クロスバスイッチ
2.5Gbpsの転送速度のリンク128本を交換するクロスバを新デバイスの利用により実現する構想。
(2)大規模ネットワーキング: Parallel Opticsの利用と、波長多重(Wavelength Division Multiplexing)による超高速ネットワークの実現。
前者は、特に新デバイスを用いる必要はないように思える。後者は、技術的な方向性をきちんととらえているが、挑戦的なテーマではない。全体としてこのドキュメントの中で、物理層に近い高速転送技術と高速スイッチ技術は、さほど重視されていない、ということが読みとれると思う。
3.2.2.3 高速スイッチの大衆化
今までに紹介した高速転送、交換技術は、一部はスーパコンピュータ的なものであるが、一面、通常のCMOS技術の発達により、超高速スイッチを、PCと同様の個人レベルで用いることができるようになりつつある。筆者が共同開発しているRHiNETは、このような超高速スイッチを身近に用いることが鍵となるプロジェクトである。
3.2.2.3.1 LASN(Local Area System Network)とRHiNET
超高速スイッチが身近に使えるようになれば、クラスタ構成用に専用PCを用いるのではなく、図2に示すように、フロアやビルに分散して配置されている PC を接続し、PC クラスタマシンと同等のパフォーマンスを獲得することが夢ではない。現在、事業部によっては、百台に及ぶPCがフロア内に配置されているが、大体の場合は、これらのPCはアイドル状態にあって、その計算能力をフルに発揮していない。超高速スイッチによってこれらが強力なスーパコンピュータに生まれ変われば、様々な用途に用いることができるだろう。
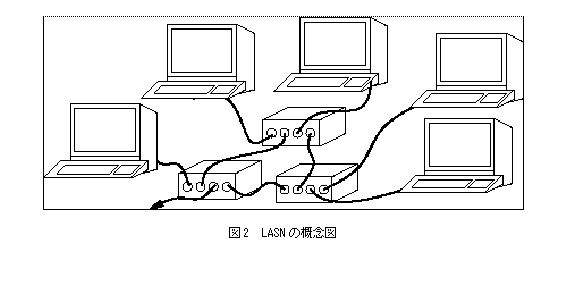
しかし、このことを実現するためには、ネットワーク自体に問題がある。現在、WS/PCクラスタはMyrinetのような専用のSAN(System Area Network)を用いて実装されているが、これは伝搬特性上長い距離を引き回すようにはできていない。一方で、LAN(Local Area Network)は、最近、高速、大容量のものが出現しているが、パケットの転送法の問題や、一定のエラーレートを想定してソフトウェアレイヤを用いるため、どうしても転送レイテンシィが大きくなってしまう。
そこで、この両者の利点を兼ね備え、SANと同様の信頼性のある低遅延通信を、ビル内やフロア内に分散して配置されたPC間で行なうネットワークが、LASN(Local Area System Network)である。我々はRWCのプロジェクトの一環として、LASNを実現するためのRHiNET(RWCP High Performance Network)と呼ばれるシステムを開発している。LASNの要求事項を解決するために、RHiNETでは現在次のような戦略をとっている。
1.レイテンシが大きいstore and forward routingやマルチキャスト時のデッドロック回避が困難でチャネルの占有数が多いwormhole routingを利用せず、asynchronous wormhole routingを用いる。
2. パケットの廃棄や望まない順序の入れかえを行わず、ハードウエアでのエラーレートを低くすることで、上位プロトコル層における通信品質補償に必要な通信コストを極力小さくする。また、パケットの破棄を許さず通信コストを抑えるため、デッドロックフリーを保障する。これには,構造化チャネル法の利用が効果的である。
3. ビル内やフロア内に分散して配置された計算機を接続するために、ループを含むある程度自由なトポロジを許し、100m程度の延長距離と並列処理で要求される十分なbi-section bandwidthを確保する。
現在、LASNのプロトタイプとしてこれらの特徴を全て備えたRHiNET-1を実装し、稼働試験を行っている。このためのスイッチであるRHiNET-1/SW[3] は 0.35μm CMOSエンベッデッドアレイを用いて構成した1チップスイッチで,8×8のクロスバを内蔵し、リンク当り130MHzで9bitデータを交換することができる。
3.2.2.3.2 RHiNET-2/SW
RHiNET-1/SWは現在のPCIバスの性能を考えると十分な性能を持つ。しかし、これだけではすぐにも普及が予想される64bit化された高速PCIバスには対応できないし、超高速スイッチとしてインパクトを与えるものではない。そこで、さらに性能を向上させたRHiNET-2の実装を行っている。このスイッチRHiNET-2/SWは、高速CMOS実装技術、基板実装技術により、最大8Gbpsの転送能力を持つリンクを8入出力持つ世界最高速のスイッチの一つである[4] (ただし、技術的な困難は光インターコネクト日立研究所が解決したものであり、我々の手柄ではない)。
とはいえ、スイッチの設計自体にもLASNを実現するため、様々な工夫が施されている。まず、縮約構造化チャネル法により、トポロジフリーなネットワークを構築でき、その下でどの様なルーティングを行ってもデッドロックフリーが保障される。また、外部に簡単な制御用プロセッサを備えることで、複雑な形状の接続に対しても、ルーティングテーブルを書き換えて、自動的に対処することができる。100mに及ぶ線路長に対応するため、拡張slack buffer方式と称するハンドシェークを行っており、このハンドシェークパケットを利用して、活線挿抜、故障の自動検出等も可能である。
さらに、RHiNET-2/SWでは新たに、以下の工夫を施している。
(a)高速リンクへの対応のため、RHiNET-1/SWでは、チップ外に配置したSRAMをチップ内に組み込み、性能向上を図っている。
(b)それぞれのflitにECCを付けて自動訂正を行なうことで信頼性の向上を図っている。
(c)高速リンクだけではなく、低速リンクに対応するため、3種類のビットレートに対応することができる。
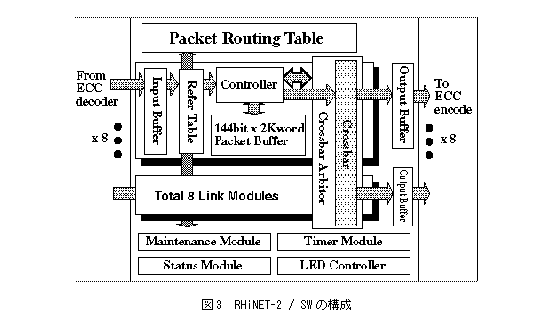
RHiNET-2/SWの構成を図3に示す。RHiNET-2/SWでは、0.25μm CMOSプロセスの利用により、800Mbps 9bitでパケットを入力して内部では200MHzの動作速度で交換する。
パケットはもっとも早い場合、19clockで次のスイッチに送ることができる。ランダムロジック部のゲート数は合計で421,000ゲート、その他に9個の144bit×4Kwordsメモリと16個の 36bit × 16words メモリ、1個の12bit × 256words メモリが配置されている。ダイの様子を図4に、スイッチのチップの写真を図5に示す。
RHiNET-2/SWは、光インターコネクトの部分に日立のParallel Optical Fiber Interface MDR/MDS4212Aを用いており、この部分が十数万円程度のコストを要するが、チップ自体は通常のCMOS技術を利用しており、最近の高速プロセッサに比べて特にコストを要するわけではない。
 |
 |
3.2.2.4 おわりに
超高速スイッチの最近の状況をまとめ、さらに数十万程度のコストで身近に超高速スイッチを用いることを可能とするRHiNET-2に関して紹介した。現状では、光転送技術およびスイッチに関しては、日本の技術は米国に比べても先行していると考えられる。また、米国は他ほどこの分野に力を入れていないこともあり、付け入る隙は大いにあると思う。
ただし、問題は、SANや高速LANの分野での標準化がほとんど米国主導で決まってしまっていることである。さらに、大衆化した超高速スイッチにより計算機の利用状況にインパクトを与えるためには、当然のことながらシステム、アプリケーションソフトウェアを考える必要があり、この点を強化することが今後の課題である。頼もしいことに、研究レベルでは日本はこの点でも決して遅れをとっているわけではないので、この分野は全体としてきわめて有望である。
参考文献
[1] L. Buckman, D. Dolfi, K. Giboney, B.Lemoff, J.Straznicky, K. Wu:
Multi-channel High Speed Optical Interconnects
Proceedings of Hot Interconnects VII,
pp. 145--162(1999).
[2] http://www.eng.auburn.edu/department/ee/amstc/extras/SiGe.html
[3] H.Nishi, K.Tasho, T.Kudoh, H.Amano:
"RHiNET-1/SW: One-chip switch ASIC for a local area system network,"
Proc. COOL Chips III, Apr. 2000 to appear
[4] S.Nishimura, T.Kudoh, H.Nishi, K.Harasawa, N.Matsudaira, S.Akutsu, K.Tasyo,
H.Amano:
"Network switch using parallel optical interconnection for high performance
parallel processing using PCs,"
Proc. 6th International Conference on Parallel Interconnect, pp.5-12,
Oct. 2000.
3.2.3 計算機間を接続して高性能並列処理を実現するネットワーク RHiNET
新情報処理開発機構 工藤知宏 講師
3.2.3.1 はじめに
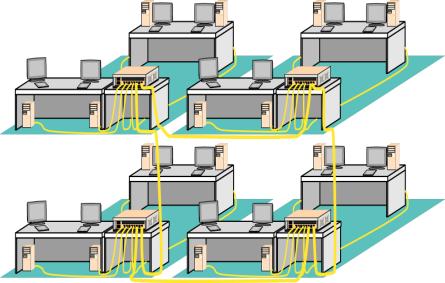
技術研究組合新情報処理開発機構並列分散システムアーキテクチャつくば研究室では光インターコネクション日立研究室および慶應義塾大学理工学部天野研究室と共同で、PCやWSを接続して高性能並列処理を可能にするためのネットワークRHiNET(RWCP High Performance Network)の開発を行なっている。RHiNETは、我々が提案するLASNと呼ぶ新しいネットワーククラスに属し、PCやWSのI/Oバスに装着されるネットワークインタフェースと、高速なネットワークスイッチ、そしてそれらの間を接続する光インタコネクションから成り、図1に示すようにビル内やフロア内に配置されたPCやWSを接続して高性能並列処理を行うことを目指している。
 |
3.2.3.2 LASN
近年、PCを多数使ったクラスタコンピューティングと呼ばれる並列処理が注目を集めている。従来のクラスタシステムは、大きく100Base-TやGigabit EthernetなどのLANを用いてPC間を結合したものと、Myrinet[1]などのSAN(System Area Network)を用いてPC間を結合したものにわかれる。
SANは一般にwormholeやvirtual-cut-through等のルーティングを採用しており、低遅延と高いbi-sectionバンド幅を提供する一方で、配線の延長距離やトポロジにおける制約が厳しいため、集約型の構成をとらざるを得ない。
一方LANを用いたシステムでは、ビル内やフロア内に分散して配置されて利用されている計算機を接続して並列処理を行なうことも可能である。Gigabit Ethernet や 1.06Gbps のFibre Channelなどが実用・普及段階に入り、LAN環境でも数ギガビットクラスの高速な通信が可能となっている。しかし、従来のLANでは物理層でのパケットの廃棄や順序の入れ換えを許しているため、信頼性のある通信を行う場合には、上位レイヤにおいて再送や順序の入れ換えを行うTCP/IPなどのプロトコルを用いる必要がある。しかしこの様なプロトコルはホストプロセッサが行う処理のオーバヘッドが大きく、数ギガビットのバンド幅を持つネットワークを有効利用するだけの実効バンド幅を得ることが困難である。このように、LANは高性能並列計算のためのネットワークとしては問題がある。
そこで、我々はSANとLANの利点を併せ持つ新しいネットワーククラス、LASN(Local Area System Network)を提唱している。LASNはフロアやビルに分散して配置されているPCを接続し、PCクラスタと同様の並列処理を行うシステムである。
・ SANと同様の信頼性のある低遅延通信を行う
・ SANと同様のbi-sectionバンド幅を持つ
・ LANと同様にビル内やフロア内に分散して配置されたPCを相互に結合する
このような特徴を持つLASNは次のような利点を持つ。
・ 日常の業務で利用されているPCを、クラスタの構成要素として用いることができる。常時全ての PC がフル稼働しているとは考え難く、余剰計算能力を集めることで性能の高い並列マシンを安価で構築できる可能性がある。
・ 異なる設置スペースにあるサーバやクラスタマシンの計算能力を集約することができる。
・ ベクトルマシン、MPP、DSPなど、異なる性能や得意分野を持つ計算機を集約することができる。
・ 特別に設置スペースを設ける必要がなくなる。
RHiNET(RWCP High Performance Network)はLASNに属するネットワークであり、並列処理をサポートする。RHiNETはネットワークとネットワークインタフェース(NI)から構成され、上記LASNの性質に加えてNIが並列処理をサポートする様々な機能を持つ。
RHiNETの開発は、1Gbpsクラスの光インタコネクションを用いるRHiNET-1と、8Gbpsクラスの光インタコネクションを用いるRHiNET-2の2段階で行なっている。これまでにRHiNET-1のハードウェアの開発を完了し、現在RHiNET-2の開発を行なっている。
RHiNETはLASNのインプリメンテーションであり、LASNの要求事項を解決するために、RHiNETでは、次のような戦略をとっている。
(1)パケットの廃棄や望まない順序の入れ換えを行わず、ハードウェアでのエラーレートを低くすることで、上位プロトコル層における通信品質補償に必要な通信コストを極力小さくする。また、パケットの破棄を許さず、通信コストを抑えるため、デッドロックフリーを保障する。MyrinetなどのSANでは、Wormhole routingやVirtual cut through routingを用いることにより、遅延(レイテンシ)が小さな通信を実現している。これらのルーティング法では、ノード間のパケット伝達路同士が環状の関係になるとパケットがネットワーク中に滞留したまま動かなくなってしまうデッドロックが発生する可能性がある。これを解決するもっとも簡単な方法は動かなくなったパケットを廃棄することであるが、この場合パケットの到着を確認し、必要に応じて再送する機構が必要となり、並列処理には適さない。そこで、これまでのSystem Area Networkでは、ネットワークのトポロジを限定して、伝達路間に環状の依存関係が生じないように伝達路を定めることによりデッドロックを回避してきた。しかし、フロア内やビル内の計算機群を接続するには、より自由なネットワークトポロジが求められる。そこで、RHiNETでは、Asynchronous wormhole routingと構造化チャネル法を用い、多数のVirtual Channel(VC)を各入力ポートに用意することにより自由なトポロジにおいてデッドロックフリーを実現する。
(2)ビル内やフロア内に分散して配置された計算機を接続するために、ループを含むある程度自由なトポロジを許し、100m程度の延長距離と、並列処理で要求される十分なbi-section bandwidthを確保する。
3.2.3.3 RHiNET-1[2][3]
RHiNET-1は、1〜1.3Gbpsの光インタコネクションまたはGigabit Ethernetで用いられる光リンクを用いる。このためのネットワークインタフェースRHiNET-1/NIと、スイッチASIC RHiNET-1/SWを開発した。
3.2.3.3.1 RHiNET-1/NI
RHiNET-1/NI(図2)は、PCIバスに装着されるネットワークインタフェースで、コントローラにPLD(Programmable Logic Device)を用いており、PLDの設定を変更することにより様々な通信プロトコルを実装、評価することができる。
アドレス変換テーブル(TLB)を内部に持ち、任意の大きさの領域のゼロコピー通信をサポートする。4つのメモリバンクに同時アクセスでき、アドレス変換などの操作とデータ転送を同時に行なうことが出来る。アプリケーション開発は message passing(MPI)ベース、共有メモリ(Open/MP)ベースの両方のスタイルで記述でき、専用のLINUXのライブラリおよびデバイスドライバを用いる。
このプリミティブ処理はNIで行われ、これらを組み合わせることにより、マルチタスク環境でのzero-copy通信を実現する。
図3にRHiNET-1/NIのブロック図を示す。RHiNET-1/NI は、パケット送受信部(Interconnection Interface)、PCIバス制御部(PCI Bus Interface)、プリミティブ処理部(Function Unit)およびプリミティブ処理用に用いるメモリから構成される。高速動作が要求されるパケット送受信部および PCIバス制御部は、高速なQuickLogic社のアンチヒューズ型FPGAを用い、プリミティブ処理部は、in-system programmingが可能なFPGA(Altera社CPLD)を用いている。
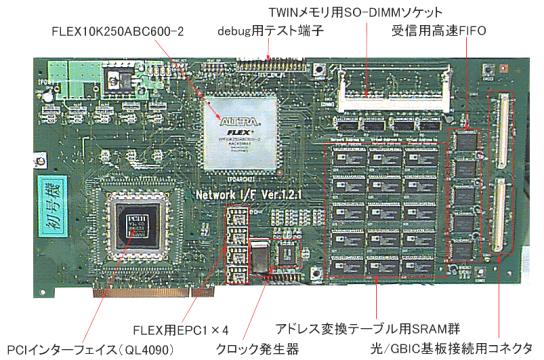
図2 RHiNET-2/NI
図3 RHiNET-1/NI ブロック図
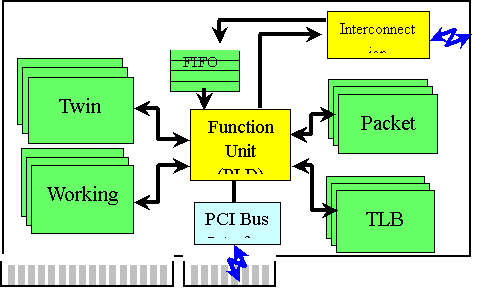 |
3.2.3.3.1.1 RHiNET-1/NI上でのプリミティブ処理
ローカルノード(Initiator)からリモートノード(Remote)にパケットを転送するpushプリミティブの実行(図4)を例にRHiNET-1/NIの動作を解説する。
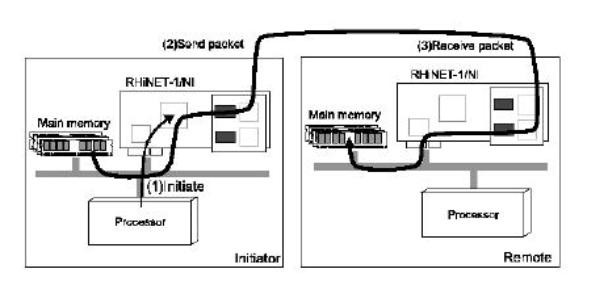
図4 pushプリミティブの動作
(1)起動
プリミティブ処理部は、プリミティブ起動に必要な情報を格納するプリミティブ起動用情報レジスタを持つ。ユーザプロセスが、ライブラリ経由でプリミティブ実行に必要な情報(送信データアドレス、宛先プロセスID、サイズ等)をプリミティブ処理部のレジスタに書き込むことで、プリミティブが起動される。
プリミティブ処理部は、ボード上のTLBを参照して仮想アドレスを物理アドレスに変換した後、PCIバス制御部に転送すべきアドレスおよびサイズを与えることで、DMA転送の要求を出す。PCIバス制御部とプリミティブ処理部は、データ転送用のローカルバスと、DMA転送起動用のDMAバスで二重に接続されており、データ転送中も次回のDMAの起動をかけることができる。
(2)パケット送信
PCIバス制御部は、要求に従い主記憶からプリミティブ処理部にデータ転送を開始する。この間、プリミティブ処理部は、パケットヘッダを準備し、パケット送受信部の送信用FIFOにヘッダの送信を開始する。DMA転送された32bitデータは、即座に送信用FIFOに入れられる。パケット送信部は、送信用FIFOにデータが入り次第、32bitデータを光インターコネクトで転送する8bit形式に変換し、転送を開始する。DMAによる転送が終了した場合、プリミティブ処理部は、主記憶の所定の番地に対して、終了通知フラグを書き込むために、PCIバス制御部に対して再びDMA要求を出す。この処理は単に転送終了を示すフラグを転送するだけのためにDMAを起動するため、一見無駄が多いように見える。しかし、ホストプロセッサが NI 上のフラグをポーリングすると、その度に PCI バスを利用するため、データ転送の効率が落ちる。一方、メインメモリ上のフラグのポーリングではキャッシュにヒットするため、このような損失を避けることができる。
(3)パケット受信
リモートノードでは、まずパケット受信部が光インターコネクトから受け取ったデータを32bitの形に変換し、受信FIFOに入れる。受信FIFOに少しでもデータが入れば、リモートノードのプリミティブ処理部が起動される。プリミティブ処理部は、ヘッダ中のリモートアドレスを、送信側同様にTLBを参照することにより、物理アドレスに変換して、PCIバス制御部に対してDMA要求を発生する。PCIバス制御部は、DMA要求を受け付けると、受信FIFO内のデータを主記憶に転送する。
一連の操作は、PCIバス制御部中でPCIバスの転送を効率化のためにデータをバッファする以外は、ほとんどの部分でデータをバッファリングすることなしに、パケット転送を行うことができる。また、プリミティブ処理部の構造は、in-system programming可能であり、様々な機能のプリミティブを状況に応じて実行することができる。さらに、RHiNET-1/NIは、SDRAMから成るTWINメモリと呼ばれるメモリを装備している。このメモリを利用することにより、複数のプロセッサが同じリージョンに書き込むことが可能な multiple writer protocolをサポートすることができる。
3.2.3.3.2 RHiNET-1/SW
RHiNET-1/SWは0.35μm CMOSエンベッデッドアレイを用いて構成した1チップスイッチで、8 x 8のクロスバを内蔵している。RHiNET-1/SWおよびRHiNET-1/NIは、自由なトポロジと、長距離のパケット転送に対応するために、以下の技法を用いた。
(1)縮約構造化チャネル法とVCC
asynchronous wormhole routingを用いると、転送パス間にループ依存関係があった場合、デッドロックが生じる可能性がある。パケットを廃棄することなくこのデッドロックを回避する手法として、構造化チャネル法が提案されている。これはネットワークの直径に等しい数の仮想チャネルを用意し、スイッチを経由するごとに異なる番号の仮想チャネルを用いる方法である。RHiNETでも、デッドロック回避のために構造化チャネル法を用い、パケットがスイッチを通過するごとに1大きい番号の仮想チャネルを使用する。
しかし、構造化チャネル法には、ネットワークの規模(最大直径)が仮想チャネルの数で制限されてしまうという問題がある。そこで、RHiNET-1/SWでは外部に大容量のSRAMを持たせ、必要なチャネルのみをチップ内のバッファに割り当てるVCC(Virtual Channel Cache、仮想チャネルキャッシュ)を採用した。この方法により、少量のチップ内バッファで多数のチャネルを実現している。
また、分岐のないスイッチ(他のスイッチと接続されているポートが2以下のスイッチ)を経由しても、異なる番号の仮想チャネルを用いる必要がないことに着目して、縮約構造化チャネル法を提案して用いた。この方法では、全てのパケットは、他のスイッチへのリンクを3以上持つスイッチを通過した時にのみ、使用する仮想チャネルの番号を増やすことにより、必要な仮想チャネル数を減らすことができる。
(2)拡張 slack buffer
RHiNETでは、ビル内やフロア内に設置された計算機間を接続するため、最大100mのリンク長(ホストやスイッチ間の線路長)を想定している。100mの光ファイバでは入力端から出力端までの伝送には約500nsを要する。従って、ハンドシェイクには、リンクの往復分のレイテンシと回路の動作時間を合わせた1.5μ秒程度を要する。受信側はパケット送信停止の要求を送信側に送った後でも、この間に受信するデータを受け取らなくてはならない。このため、受信側はリンク中にあるパケットを受信するのに十分な容量がパケットバッファに残っているうちに、送信側にパケット送信をこれ以上行わないように要求する必要がある。これはwindowによるフロー制御の一種であり、Myrinetで用いられている手法でslack bufferと呼ばれる。RHiNETでは構造化チャネル法を用いるので、パケットバッファは仮想チャネルごとに必要であり、送受信のハンドシェイク操作を仮想チャネルごとに行うように拡張する。この方式を拡張slack bufferと呼ぶ。
これらの方法の採用により、RHiNET-1は、リンク当たり1.33 Gbpsのバンド幅を持つLASNを実現した。
3.2.3.4 RHiNET-2[4]
将来のPCやWSの性能向上とこれに伴うネットワークへの要求性能を考えると、さらに高速なネットワークが必要になることが予測される。
並列処理の応用分野には、行列計算など大量のメモリコピーを高速に行うことが必要になる問題が多い。システム全体の性能を上げるには、メモリが提供するバンド幅に近い速度でメモリ間コピーを行うことができるネットワークが求められる。PCのメモリのバンド幅は既存のものでも最大8.5Gbps(133MHz、64bit)に達している。さらに、複数のメモリバンクや RAMBUS 方式のメモリを採用するなどした、より高いバンド幅を持つものが登場しつつある。
一方、ネットワークインタフェースが装着されるPCのI/O部にも、PCIやInfiniBand[5] などの10Gbpsクラスのバンド幅の規格が策定されつつある。近い将来、オフィスや研究室などに設置された通常のPCやWSが数ギガビットクラスのネットワークインタフェースを装備できるようになると考えられる。
このような状況では、近い将来にも、RHiNET-1をはるかに上回る性能を持つネットワークが必要である。そこで、より高速な光インタコネクションを用いてさらに性能の高いネットワークを持つ RHiNET-2 の開発を行っている。
3.2.3.4.1 RHiNET-2/NI
ネットワークインタフェースRHiNET-2/NIは、コントローラにASICを用いる。ASIC内部に大容量のメモリとプロトコル処理プロセッサを持ち、プロトコル処理の内容はプログラムすることが出来る。8Gbpsクラスの光インタコネクションに直接接続可能である。64bit/66MHzのPCIインタフェースおよび外付けSDRAMのインタフェース、専用プロセッサを内蔵している。また、大容量のSRAMを内蔵することにより基本的な処理をチップ内で行なうことができる。現在設計を進めており、2000年度中の稼働を目指している。
3.2.3.4.2 RHiNET-2/SW
RHiNET-2/SWでは、RHiNET-1から以下の点について改良を行なった。
(1)光インタコネクトモジュール
RHiNET-2では、日立製作所製のインタコネクトモジュール MDS4212A/MDR4212Aを用いた。このモジュールは、12組の発振波長1310nm端面発光レーザアレイとフォトダイオードを並列駆動することで、小型パッケージ(3.9cc)で8.8Gbpsの大容量光データ接続を実現している。1本のパラレルファイバケーブルで、クロックと11bitの800Mbpsのデータを転送することができ、最大100mの伝送が可能である。
(2)大容量オンチップメモリの採用
RHiNET-2/SWでは、転送レートの向上にともないslack bufferのために必要なメモリ量(VCあたりのメモリの大きさ)も大きくなる。一方、0.18μmルールのCMOSを用いることにより、オンチップメモリ上にポートあたり512Kbitsの仮想チャネルのためのバッファを持つ。これを用いて、4Kbytesの仮想チャネルをポート毎に16個装備した。これにより8Gbps、100mのリンクでwaveform pipelineと拡張slack bufferを実現した。
(3)柔軟なルーティングテーブルの採用
RHiNET-2/SWでは、パケットのルーティングはヘッダに格納されたルーティングIDによってルーティングテーブルを参照して決定される。ルーティングテーブルは、どの出力ポートにパケットを送り出すかを示すbitmapを返す。これは、8つの出力ポートとおよびスイッチに付随するメンテナンスプロセッサそれぞれにパケットを出力するかどうかを示す9bitのbitmapである。従って、bitmapで複数の出力先が指定されていれば(すなわち1であるビットが複数あれば)マルチキャストとなる。
RHiNET-2/SWのルーティングテーブルにはパケットバッファと同じ大きさのメモリを用いており、65536のエントリを持つ。ルーティングテーブルの設定は、メンテナンスプロセッサもしくはパケットにより行なうことができる。宛先ノードIDを用いてテーブルを参照すれば、最大65536のノードにまでパケットをルーティングできる。
システム全体のノード数が少ない時には、単一宛先とマルチキャスト、ブロードキャストのエントリを混在させたり、同一宛先への複数の経路を設定するなどの柔軟なルーティングが可能である。256ノード以下のシステムでは、宛先と送り先のノード番号の組によりルーティングを行うことも可能になる。
(4)仮想ネットワーク
一般には仮想チャネルは単一ネットワーク上に互いに影響されない複数の仮想ネットワークを実現することにより、パケットのルーティングに優先順位を設けたりQoSを保証するなどの用途に用いられることが多い。RHiNETでは、仮想チャネルをデッドロック回避に用いており、RHiNET-2/SWは各入力ポートに16個の仮想チャネルを備えて直径の大きなネットワークにも対応している。しかし、ネットワークの直径が大きくない場合には、これらの仮想チャネルを仮想ネットワークの実現に用いることが考えられる。
仮想ネットワークを用いることによりRHiNETの通信プリミティブを効率的に処理することができる。RHiNETのプリミティブは複数のrequestとacknowledgeパケットにより構成されるが、これらのrequestやacknowledgeパケットそれぞれに異なる仮想ネットワークを割り当てれば、requestパケットに全く阻害されることなくacknowledgeパケットを受け取ることができる。従来ではプリミティブ間のデッドロック回避の為に、ネットワークインタフェースにイベントキューを設け、さらにプリミティブの発行数を制限する必要があったが、仮想ネットワークの利用により、この制限を無くすることができる。
(5)伝送路のエラーレートとエラー訂正
RHiNETでは、ネットワークの信頼性が高いことを利用して、再送などの動作を省くことにより高速転送を行う。RHiNET-2/SWで使用する光インタコネクションモジュールの単体でのBit Error Rate(BER)は10-20以下である。これは、1000台のPCで構成される程度の規模でRHiNETシステムを構築し、全てのスイッチが最大転送バンド幅で1000時間動作し続けた場合を想定しても、システム全体で1つ以下のエラーしか発生しないことを意味する。また、RHiNET-2/SWではASICパッケージのI/Oや基板上の配線を伝達される電気信号も非常に伝送レートが高いことを考慮して、エラー訂正符号(ECC)を用いることによりさらに信頼性を向上させている。
(6)マルチビットレート
RHiNET-2/SWは、様々な価格や性能を持つインタコネクトの混在を許すため、異なる転送周波数での交換を可能とするマルチビットレート転送機能を持つ。これにより、RHiNET-1/NIと同様のアーキテクチャを持つ比較的低速なネットワークインタフェースにも接続可能である。
RHiNET-2/SWは、電気的特性を調べるための最初のプロトタイプによる実証試験を終え、論理動作を含めて動作する最終プロトタイプを用いた調整を行なっている。図5にRHiNET-2/SWチップのダイの写真を示す。このチップは日立製作所製の16.5mm角の0.18μルールエンベッデッドアレイである。

図5 RHiNET-2/SW チップ ダイ
3.2.3.5 おわりに
現在、RHiNET-1システムを用いてソフトウェアの開発とシステムの検証を行なうとともに、RHiNET-1での経験に基づきRHiNET-2の開発を行なっている。RHiNET-2システムは当初RHiNET-2/SWにRHiNET-1/NIを改良したネットワークインタフェースをつないで運用し、2000年度中にはASICコントローラを用いたRHiNET-2/NIを用いて稼働する予定である。
参考文献
[2] 山本淳二他「高性能並列計算機用ネットワークRHiNET-1の実装と評価」情報処理学会研究報告 2000-ARC 137-11, 2000年3月
[3] 西宏章他「仮想チャネルキャッシュを持つネットワークルータの構成と性能」、並列処理シンポジウムJSPP’99 Vol 99 No.6. pp.71-78
[4] 西宏章他「「LASN用8Gbps/port 8x8 one-chipスイッチRHiNET-2/SW」、並列処理シンポジウムJSPP 2000(採録)
3.2.4 プロセッサ技術およびストレージ技術に関する研究開発の状況 −課題と展望−
花輪 誠 委員
3.2.4.1 ペタフロップスマシンの実現は目前
ハイエンドコンピューティングマシンのハードウェアについて考える際、最近のマイクロプロセッサの動作周波数の飛躍的な向上について触れざるを得ない。当面のハイエンドマシンの目標スペックをペタフロップスとすると、100GFLOPSのプロセッサを10,000個、並列動作させれば達成可能である。ここで、100GFLOPSのプロセッサの実現可能性を考えてみると、20個の演算器を5GHz、または、32個の演算器を3GHzで動作できるか?を考えれば良い。
先ず、「1プロセッサ内で演算器を20〜30個程度、並列に動作できるか」であるが、最近の家庭用ゲーム機向けLSIですら、16個程度の演算器を並列動作させている訳であるから、ハイエンドコンピューティングの分野では、問題無く実現可能であろう。
次に、動作周波数であるが、今年の2月に開催されたISSCC2000(半導体回路の国際学会)において、GHz級のマイクロプロセッサの発表が相次いで行われている。これを見ると、3〜5GHz動作も、間もなく実現可能であると考えられる。
ISSCC2000は、正に、GHzプロセッサの学会と言っても過言ではなかった。テクニカルセッションでは、1GHz級プロセッサで3件、760〜780MHz級で2件の発表があり、テクノロジーディレクションでは、4.5GHzで動作する演算器の試作結果の報告があった。また、ワークショップでは、マルチGHzプロセッサの設計技術の議論が行われた。
 |
|||
|
図1 ペタフロップスマシン
ISSCC2000でのGHzプロセッサは、全て、CMOS-LSIで実現されている。HTMT(Hybrid Technology Multithreaded architecture)で検討されているような超伝導技術を持ち出すまでもなく、一般のワークステーションやパソコンに使われているマイクロプロセッサの延長線上で実現できる訳である。
ペタフロップスマシンの実現は目前である。一方、ペタフロップスマシンを如何に産業に活用していくかと言う質問に対しては、明確な解答を持ち合わせていない。ペタフロップスマシンの利用技術を確立するには、先ず、実在のマシンを手に入れる必要がある。
国の予算で国内にペタフロップスマシンを10台程度、設置し、それを国民が活用して、新製品の開発、新事業モデルの構築などを推進し、GDPを1%拡大できないものだろうか。これが可能なら、1台数百億円のペタフロップスマシン10台でもトータル数千億円であり、国の経済対策として見れば実現可能な計画と思える。
ハイエンドコンピューティングについて、何か提案させてもらえるとしたら、2〜3年後の運用開始を目指して、国内に数台のペタフロップスマシンを配置し、経済活動に有効な利用技術を立ち上げることを提案したい。
ペタフロップスマシンの活用案を広く公募し、有効と判断できる案件に、CPU利用時間を予算として割り当てることにしたい。使用料金は格安にして、結果として生まれた新製品や新事業モデルの利益から、一部を回収する方式、言わば、「出世払い」型が良い。
新規の事業モデルを構築する際、市場動向シミュレーションや、実績データからのデータマイニングなど、ペタフロップスマシンを活用した大規模計算を実施することにより、事業化リスクを大幅に低減できるかもしれない。
ハイエンドコンピューティングの利用技術とマシンの構築技術が車の両輪となって、互いに加速し合うポジティブフィードバックを形成しないと、最近の国内計算機業界の閉塞感を打破できない。
3.2.4.2 プロセッサ技術に関する研究開発の状況 −課題と展望−
前項で、GHz動作のプロセッサがISSCC2000で多数、発表されたと述べた。しかし、これらは、全て米国のプロセッサメーカの発表である。日本からの発表では、450MHz程度である。
マイクロプロセッサの動作周波数を向上させるには、高性能CMOSデバイス技術と高周波数対応設計技術の両方が必要である。高性能CMOSデバイス技術は、最先端の微細加工半導体製造プロセスラインの構築にかかっている。特に、DRAM等のメモリLSI製造ラインでなく、プロセッサ等のロジックLSIの製造ラインの構築が重要である。米国メーカは、早くからロジックLSIの生産に特化していた。
また、この製造ラインの構築に必要な投資ができるか否かも重要なファクタである。特に、最近の微細加工プロセスでは、1ラインの構築に1,000億円規模の投資が必要である。世界市場を相手にして、大量の生産規模を確保することによって、次世代技術に対する投資が可能になる。
国内の半導体産業は、以前は、DRAM主体の事業であったが、近年、台湾や韓国のメーカの追い上げが厳しく、システムLSIへの展開が急務である。ロジックLSI向け高性能CMOSデバイス技術の開発は、先延ばしできない重要なコアコンピタンスである。
この分野に関しては、半導体のリソグラフィ技術など、国家レベルの将来への布石はある程度、打たれていると認識している。
設計技術に関しては、大きな格差を認めざるを得ない。先ず、人材面では、大学におけるLSI設計技術教育の歴史の違い、更に、世界中からカリフォルニア州やテキサス州などに人材が集中してくる状況などが、格差の源であろう。
CAD / DAなどツール類に関しても、新技術を次から次へと生み出すベンチャ企業、更に、ベンチャ企業の技術が有効と判断したら迅速に吸収合併する大手ベンダによって、格差が生じているものと考えられる。
一方、国内のマイクロプロセッサメーカの強みは、低消費電力化技術である。情報家電を始めとした民生品向けのマイクロプロセッサで、第一に必要とされるからである。言わば、低消費電力化技術の開発投資は、回収可能な投資であるが、高周波数化技術の開発は、国内メーカにとって、回収可能な開発投資ではなかったと言うことに他ならない。
前項で提案したペタフロップスマシン全国配備計画が実行されれば、国内メーカにとっても、高周波数化技術の開発投資が回収可能な投資になる。実際、米国ではASCI計画によって、マイクロプロセッサの開発に弾みがついたと見ることもできる。
ISSCC2000で発表されたGHzプロセッサの設計は、DAツールによる自動設計ではなく、人海戦術による力業的な設計である。これらの設計を自動化する研究に対して、米国ではNSFがサポートしている。国内においても、抜本的な加速策が必要である。
以下、ISSCC2000で発表されたGHzプロセッサに関して、概要を紹介しておく。
| 会社名 | プロセッサ | 動作周波数など | 主な発表内容 |
| Compaq | Alpha |
1GHz@1.65V 65W 0.18μm 13.1x14.7mm2 15.2M Trs. Al 7層 |
SPECint/fp2000=700/900(見積り) SPECint/fp95=60/110(見積り) |
| Sun | UltraSPARC III |
1GHz@1.6V <80W 0.15μm 244mm2 23M Trs. Al 7層 |
現世代に比べクロック周波数は1.5倍 ILPは1.15倍 パイプラインステージを9から14に増加 |
| Intel | IA-32 |
1GHz 1.1〜1.7V 0.1818μm 106mm2 28M Trs. Al 配線 |
SPECint/fp2000: 733MHz品に対して1.17/1.22倍 |
| IBM | S390 G6 |
760MHz@1.9V 32W@637MHz 0.22μm 14.6x14.7mm2 25M Trs. Cu 6層 |
1プロセッサで200 MIPS(S390) 12way SMPで1600 MIPS(S390) |
| Motorola | PowerPC |
780MHz@1.5V 0.18μm Cu 6層 |
クロック分配系を工夫 |
| 日立 | 64b RISC |
450MHz@1.8V 0.20μm 28.3M Trs. Al 7層 |
MOSトランジスタの閾値をチューニング |
| IBM | 64b浮動小数点乗算器 |
3.3〜4.5GHz 1.5V 0.18μm |
非同期回路技術 |
3.2.4.3 ストレージ技術に関する研究開発の状況 −課題と展望−
ペタフロップスマシンでは、メインメモリとしてペタバイト級、磁気ディスクとしてエクサバイト級のストレージが必要であろう。また、バンド幅としては、100TB/s級のアクセススループットが必要である。ペタフロップスマシンは、10,000個のプロセッサを想定しているので、磁気ディスクも1,000から10,000個の並列構成が想定される。
ストレージに対する大容量並列アクセス技術の確立に向け、米国DOEは、HPSS(High Performance Storage System)の開発を推進している。実際の活動母体は、サンディエゴスーパーコンピュータセンタであり、IBM社の他、Sun社、Storage Technology Corporation社なども参画している。
最近、データウェアハウス、データマイニングなど非科学技術計算分野以外でも、大量のデータを扱うことが多くなっている。データそのものに価値がある時代である。今後は、生のデータを大量に蓄積していくことが要求されるであろう。
ストレージ装置の方も、ディスクドライブの大容量化とディスクアレイ装置の普及、更に、ストレージ エリア ネットワーク(SAN)の導入などによるアクセススループットの高度化が進展している。
従来、オペレーティングシステムのI / O処理は、シーケンシャルな実行が基本であったので、これを並列化し、データの整合性を維持していくためには、新たな仕組みが必要になってくるものと思われる。日本が得意とする光ファイバ接続との連携により、これらの課題を解決できるのではないかと考えられる。
HPSSの開発においても、実際にハードウェア システムを構築して、計算センタの運用を実際に行いながら、新規機能の開発がフェーズ分けされながら、推進されている。第1項で提案したように、先ず、ペタフロップスマシンによるハイエンドコンピューティングサイトを構築し、その上で、オペレーティングシステムを始めとしたソフトウェアの開発を推進していく必要がある。
 |
||||
|
||||
3.2.4.4 まとめ
ハイエンドコンピューティングマシンの当面の目標であるペタフロップスマシンの実現性について検討した。最近のマイクロプロセッサ高性能化の勢いを見ると、5GHz程度で動作するCMOSプロセッサも近い将来に実現可能であると予想される。その結果、1プロセッサ当り100GFLOPS程度は、実現可能であり、これを10,000個、並列動作させれば、ペタフロップスマシンは構成可能であろう。
ハイエンドコンピューティング分野における研究開発を加速させるために、マシンを実際に構築し、利用技術を早急に立ち上げる計画を提案した。最近のインターネット データ センタの普及と共に、ハイエンドコンピューティングの産業利用が更に加速されるものと予想できる。利用技術と構築技術を車の両輪に、ポジティブフィードバックにより研究開発を加速させたい。
プロセッサ技術への開発投資は、最近の国内メーカにとっては、苦しい状況が続いている。開発成果の市場投入、開発投資の回収と言ったループが構築できていない。上記のペタフロップスマシン計画を利用して、弾みを付けられないものかと考えている。
一方、我が国のマイクロプロセッサ技術力の強みに、低消費電力化技術がある。これを伸ばして行き、民生機器分野での競争力を向上すると共に、今後ハイエンドコンピューティング分野においても、低消費電力化技術は重要な技術の一つになるであろうから、上手に育成していく必要がある。
ストレージ技術に関しては、磁気ディスクの驚異的な容量拡大と言うシーズと共に、データウェアハウス、データマイニング技術の一般化により大容量化のニーズも拡大している。課題は、大量のデータを如何に高速にオペレーションするかであり、今後、この分野の技術開発が重要になってくるであろう。
今回は、ネットワークについて余り配慮できなかったが、本来は、グローバルコンピューティング等の検討が重要である。今後の検討課題としたい。
参項文献
[1] ISSCC2000 Digest of Technical Papers, IEEE SSCS, Feb. 2000