本節では、将来の高性能計算を支える重要な要素技術として、計算とそれに付随する様々な事象を精密に予測する技術を取り上げる。すなわち、本質的に不可知あるいは可知ではあるが知ることが困難な情報について何らかの予測を行い、その結果に基づいて計算の高速化を図る技術について、以下のような議論を行う。
並列計算は一般に、分散と統合という2種類の相反する性質の処理から構成される。このうち分散的(あるいは局所的)処理には計算の本質的部分が多く含まれるのに対し、統合的(あるいは大域的)処理には非本質的操作が少なからず含まれる。
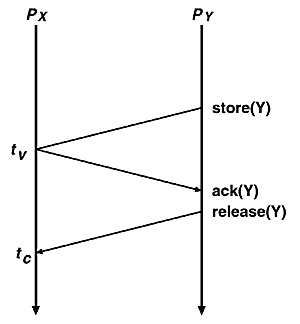
たとえばプロセッサPXがある値Xを、またPYがYをそれぞれ独立に計算し、その和ZをPXが計算するという、ごく単純な例について考える。これらの計算の中で、分散的に行われるXやYの計算は当然本質的である。一方PXが行う統合的処理であるZ=X+Yについては、加算自身はもちろん、Yの値をPYから得る操作もやはり本質的である。そこでこれらの本質的な操作に要するコストを最小化するために、YをPXでの加算操作に可視であるようにする、すなわちYをPXのレジスタやメモリに置くようにすると、Yの正当性を知るためにPYでの計算完了を確認するために同期操作が必要となる。
この同期操作は、PXが加算を行おうとする時点でYが正当な値であれば不要であるということから、非本質的な操作であるといえる。この非本質的操作のコストを隠蔽するには、Yがどの時点で(望むらくはXの生成と同時に)正当な値となるかを予測し、その予測に基き加算を投機的に実行すればよい。
この予測は図1に示すように、Yが実際に正当な値となる時刻tvに行ったとしても、それが確認される時刻tcで判明する情報を予測していると考えられる。すなわち空間的に離れた場所に置ける計算状況の認識には、空間的距離を時間に変換したコストを要し、そのコスト隠蔽には本質的に不可知である未来の状況を予測する必要がある。したがって並列計算においては本質的計算コストの削減や、それに伴って生じる非本質的計算コストの隠蔽のために、並列計算がなされる場の空間的距離を時間に変換した未来の状況の予測が重要であるといえる。
また上記の例では、Xの計算が完了すると同時にYが正当な値となるのが最適である。そのためにはX、 Yの計算に要する時間TX、 TYと、YをPYからPXに伝達するための時間TCが、TX=TY+TCとなる必要がある。あるいはこのような通信時間を加味した微調整は省略するとしても、TX~ TYとすること、すなわち負荷の均衡が重要であることはいうまでもなく、不均衡によって生じるアイドル時間は非本質的計算コストとなる。
ここでXやYの計算が一定の独立性を持った部分計算に分解でき、個々の部分計算を任意にPXまたはPYに割付け可能であるとする。このような状況で最も望ましい負荷分散は、計算開始前に個々の部分計算に要する時間(厳密にはPXおよびPYおける計算時間)をプログラム解析などによって予測し、静的な割付を行って負荷を均衡させることである。一方、静的予測が困難であったり十分な予測精度が得られない場合など、部分計算の動的な割付を必要とする際には
などを予測する必要がある。逆にこれらの予測を省略する、精度を落す、実際の状況を知る、などの「手抜き」をしてしまうと、直ちにアイドル時間や前述の遠隔計算状況の認識による非本質的計算コストが増加する。したがって、予測自体に要する計算コストを予測精度の向上によって得られる利益でカバーできる範囲で、高精度の予測を静的/動的に行う必要がある。すなわち並列計算においては低コストで得られる情報に基づく一定の局所的計算コストを投資した上での、非本質的計算コストを削減するに足る高精度の予測が重要であるといえる。
ここではまず、予測技術を特徴付ける分類項目を挙げ、続いて現状の高性能計算に用いられている予測技術の代表例を示すとともに、項目ごとの分類を行う。
(1) 予測技術の分類項目
時間的予測と空間的予測 現状の予測技術では、将来に生じるであろう事象を予測する時間的予測が主なものである。一方並列計算においては、前述のように他のプロセッサの計算状況などの認識に高いコストを要する情報を予測する、空間的予測も用いられている。
静的予測と動的予測 コンパイル時などの計算開始以前に予測を行う静的予測と、実行時に予測を立てる動的予測とがある。また動的予測には、過去の履歴などに基づいて予測方法を修正する適応的なものと、そうではない単純なものとがある。
予測に関するコスト 予測に関するコストとして、以下の3項目が挙げられる。
また予測コストと成功コストには、計算時間の形で支払われる時間的コストと、ハードウェア投資やメモリ消費などの形で支払われる空間的コストがある。また、ここでの失敗コストは、予測が完璧である場合に比べた時間ロスという時間的コストとす
る。
予測精度 予測が正しい確率。実際に支払われる失敗コストは、予測精度に相関す
る。
(2) 予測技術の実例
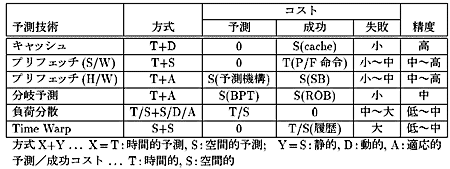
キャッシュ[1、2]
キャッシュ(あるいはTLBなどのキャッシュ的機構)は、あるアドレスに対するアクセスが近い将来に行われるであろうという時間的予測に基づく機構であり、予測による高速化技術の代表例ということができる。予測の方法は適応的ではない単純な動的予測であり、予測コストは時間的にも空間的にも0、また時間的成功コストも0である。空間的な成功コストはキャッシュメモリそのものであり、かなり大きなコストであるといえる。また失敗コストは、キャッシュライン中でアクセスされずにリプレースされる部分をキャッシュにロードするコストと、1度しかアクセスされないラインによってリプレースされるラインの再ロードコストであるが、予測精度(ヒット率)が高いことからも小さいといえる。
キャッシュに関連する予測技術としては、ハードウェア/ソフトウェアによるプリフェッチがある。ハードウェアプリフェッチについては、過去のアクセス履歴によるストライド予測といった、適応的予測を行うものもある。一方ソフトウェアプリフェッチは、通常静的予測を用いる。またキャッシュと比べて、全くアクセスされないラインのロードによる失敗コストが余分に生じ、予測精度も特にハードウェアプリフェッチでは必ずしも高くはない。
分岐予測 [3、4、5]
分岐予測とそれに基づく投機的実行も、時間的予測による高速化技術の代表例の一つである。予測方法には静的/動的の双方があるが、最近の主流は2ビットカウンタ方式のように一定の適応性を持った動的予測である。予測/成功に関する時間的コストは0であるが、空間的予測コストとして分岐予測テーブルが、また空間的成功コストとしてリオーダーバッファのような投機失敗に対処する機構が、それぞれ計上される。失敗コストは数クロック程度であるが、予測精度がさほど高くなく、50%程度の例もある。
また投機的実行の変形例として、分岐確率を静的に予測した上で、taken/not-takenの双方のパスに関する投機的実行を行うものもある。これは一種のリスクヘッジであり、他の予測技術には見られない方式である。
負荷分散 [6、7、8]
現状の並列計算における予測技術の代表例が(自動)負荷分散であり、様々な種類のものが提案/実装されている。負荷分散における予測は、負荷の大きさの予測とプロセッサの負荷状況の予測に大別される。
負荷の大きさの予測は多くの場合静的に行われ、forループのように比較的単純なものを対象とするものが多い。しかし最近では、たとえばプログラム解析によって負荷の大きさがリストの長さに比例することを求めておき、実際の予測は実行時にリストの長さを測定して行うといった、一定の予測コストを投資する例も現れている。
プロセッサの負荷状況については、拡散型の分散方式のように近傍の負荷状況から大域的な状況を類推する空間的予測、非均質分散計算でのプロセッサ性能をベンチマーク性能などから類推する静的な時間的予測、計算の途中までに要した時間によって以後の負荷状況を推定する適応的な時間的予測などが用いられている。これらに要する予測コストは負荷状況の測定や記録など比較的小さいが、システムの各部の動作状況を積極的にモニターして得た値を負荷モデルに適応して予測するといった、高い予測コストを投資するものもある。
負荷分散では予測の失敗が計算の誤りを導くことはないため、成功コストは通常0である。一方失敗コストは、負荷の不均衡によって生ずるアイドル時間として計上される。
Time Warp [9、10、11]
分散シミュレーションの代表的かつ原理的な手法の一つであるTime Warpは、対象モデルを構成する各プロセスの局所時刻がシステム全体で揃っているという空間的予測に基づく手法である。予測方法は、常に局所時刻と因果関係の不整合が生じないと予測するという意味で静的であり、予測コストも0である。成功コストは、予測失敗による因果関係の逆転に備えた、プロセスの状態遷移履歴の保存コストである。また失敗コストは履歴の巻き戻しと、その他プロセスへの波及であり、かなり大きな値となる。また予測精度はシミュレーション対象に依存するが、50%以下という例も報告されている。
Time Warpに関連する予測技術としては、局所時刻と因果関係の整合を仮定する範囲を限定し(すなわちある範囲の時刻のみを整合していると予測する)、その範囲を種々の方法で適応的に制御するものがある。このような方法では予測精度が向上するが、Time Warpにはない失敗コスト、すなわち不整合を予測することによる不要な待ちが生じる。
以上の実例を前節の分類項目にしたがってまとめると、表1に示すものとなる。
過去および現在の回路設計技術の動向に基づいて将来の並列計算を展望すると、局所的計算と大域的通信のコスト差がさらに拡大するものと予想される。したがって3.1.3.2で述べた並列計算を行う場の空間的距離が相対的に大きくなり、高精度の予測がますます重要になる。そこで、予測技術の適用範囲の拡大と、予測精度の向上の2項目について、プロセッサやシステムのアーキテクチャがどのような方向で変革すべきかを議論する。
適用範囲の拡大
3.1.3.3で述べた現状の予測技術の多くは、予測失敗が計算の誤りを引き起こさない安全なものであるか、あるいは分岐予測のように狭い範囲で巻き戻す程度に留まっている。例外はTime Warpであるが、巻き戻し自体に要する失敗コストだけではなく、その準備のための成功コストが大きいことから、その改良の多くは予測のaggressivenessを制限する方向で行われている。
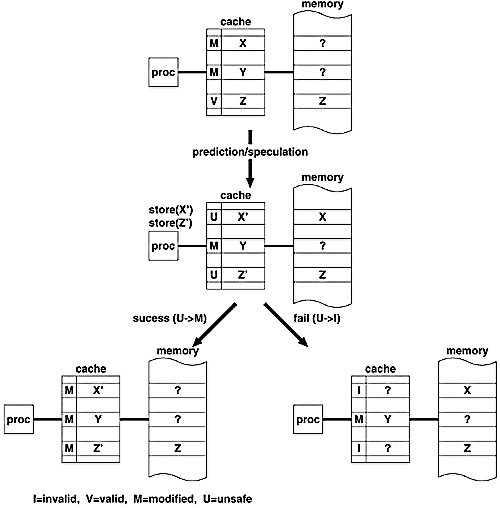
一方、将来の並列計算では時間的/空間的に広い範囲の予測、すなわち予測してからその結果が判明するまでに長い時間を要するような予測が要求されるため、投機的なメモリ更新のように非限定的な投機的操作を許容するアーキテクチャが求められる。たとえば我々は、同期操作に対するメモリアクセスを投機的実行を行うために、キャッシュを用いて予測点での状態を低コストで保存する機構を提案している(図2)。この機構では、投機の開始、成功、失敗に関する操作が全て定数時間で実施できるため、結果の判明に時間を要するような予測を積極的に行うことができる。
なお上記の機構は、投機的実行に関するほとんどの操作をハードウェア化することによって予測に関するコストを最小限にしているが、そのために予測から結果判明までの期間がオーバーラップできないなどの制約が存在する。より一般的な機構とする場合には、成功コストの最小化を目的としたハードウェア機構と、ある程度の失敗コストを許容しつつ一般性を確保するためのソフトウェア機構の組合せが重要である。
予測精度の向上
ハードウェアによる予測機構は、時間的な予測コストが小さい反面、テーブルなどを用いた比較的単純な予測を行うため、予測精度の面で問題が生じる。したがってソフトウェアによる静的または動的な予測と、必要に応じてそれを支援するハードウェアを組み合わせるのが適切である。
ここで問題となるのは、現状の命令セット、アーキテクチャが予測のような一種のメタレベル計算に対応していないこと、すなわち予測に関わるハードウェア機構に対してソフトウェアが介入するための一般的な枠組がないことである。もちろん、個々のハードウェアごとに異なるであろう予測機構とのインタフェースを統一するのは不可能であるが、たとえばコプロセッサのような枠組で一般的なインタフェースを提供する必要があろう。またこのような枠組をさらに進展させると、メタレベル計算に専念するコプロセッサの導入も考えられる。
参考文献
'80年代には性能がGigaflopsクラスのベクトルプロセッサ型スーパーコンピュータが商用化された。'90年代には性能がTeraflopsクラスの並列型スーパーコンピュータが商用化された。これに伴い多くの公的研究機関や民間企業がスーパーコンピュータを導入し、数値シミュレーションの技法を用いた計算機実験を通してさまざまな成果をあげてきた。
その一方で、スーパーコンピュータの開発費はその性能とともに膨大になり、多額の開発費を投入できるメーカのみがスーパーコンピュータ市場に残れる状況になった。また、スーパーコンピュータへの期待感ほどには市場規模が拡大せず、多数のメーカがビジネス判断としてこの分野から撤退し、結果として少数企業の寡占市場になった。
'90年代までの性能トレンドを単純に延長するなら、'00年代にはPetaflopsクラスのスーパーコンピュータの実現が期待されることになる。しかしこれまでのスーパーコンピュータの市場規模のトレンドを考慮すると、今後もビジネス判断としてスーパーコンピュータ市場からの撤退を決断する企業が出る可能性がある。その結果、企業間競争がなくなれば性能トレンドの維持は困難になる。さらに、当該市場に参入する企業が全くなくなるような事態が生ずれば、スーパーコンピュータそのものがなくなってしまう。
科学技術振興の観点から、このような状況を国策として是とはできまい。そのため、公的研究機関での実用化を意識した先行的研究活動や、複数企業の競争を通した実用化技術の発展を支えるための国家レベルでの施策が必要になる。国費投入も必要になる。
以下では、Petaflopsクラスをめざすスーパーコンピュータ市場の健全な発展に必要な国家レベルの施策について、報告者の私見を述べる。
最初に、Petaflopsクラスをめざすスーパーコンピュータ(以下、ペタフロップスマシンと呼ぶことにする)を開発していくために必要な技術開発の指針について述べる。
これまでのスーパーコンピュータ向きアーキテクチャ進展の経緯を見てわかる通り、ペタフロップスマシンが並列プロセッサであることは必然と考えられる。並列プロセッサのアーキテクチャには実にさまざまなタイプがあり、どのタイプが本命であるかは今後の研究によって究明されるべき事項である。しかし、どのタイプの並列プロセッサであっても、その実効性能は次式でモデル化できる。
ただし、
である。
PをPetaflopsクラスにまで向上するためには、r、nおよびpのそれぞれの向上が必要になる。そのための主な課題は次の通りである。
表1 ペタフロップスマシン実現のための主な技術課題
| 課題 | 応用ソフト | コンパイラ・OS | アーキテクチャ | ハードウェア |
| r向上 | 高並列算法 | 高効率並列 実行制御 |
高効率協調動作 データ参照局所化 |
高速データ転送 |
| n向上 | - | - | - | 高密度実装 |
| p向上 | 高速算法 | 高効率CPU制御 | 命令レベル並列 | 高周波数動作 |
r、n、pが互いに独立であるならば、それぞれの向上の目標を設定し、それに向かってそれぞれの分野が邁進すれば良い。実際、並列プロセッサ研究開発の黎明期には、r、n、pを独立とみなして研究を進めることができた。しかし、並列プロセッサの実用期になると、もはやr、n、pは独立とはみなせなくなった。並列プロセッサ研究者の間では、次のような依存関係が常識として認知されている。
(1) rはnおよびpに依存する。nが大きくなるほどrの向上が困難になる。
(2) nの向上とpの向上は背反の関係にある。なぜなら、nを大きくするためにはコンパクトな要素プロセッサが有利だが、pを大きくするためには命令レベル並列処理技術等のハードウェア量拡大が必要だからである。並列プロセッサとして見れば、結局はn×pを向上すればよいのは確かだが、そのために最適なn、pそれぞれの目標は見えていない。
このような場合、r、n、pの依存関係を明確にするために、よりベーシックな独立変数でr、n、pを定式化することが科学的なアプローチかもしれない。ただ、目標自体が「'00年代にペタフロップスマシンを実現」という工学的な目標であるため、本稿でも工学的な視点からの分析を進める。しかし上記のような科学的アプローチは極めて大切であり、別途、あるいはペタフロップスマシンの開発の一部として推進する必要があることを忘れてはならない。
現状の技術レベルとして、rの値はおおむね0.1以上、ときには1に近い値を達成していると考えられる。そのためテラフロップスマシンからペタフロップスマシンへの1,000倍の性能向上は、主としてn×pの向上に依存する。また上述のようにnが大きくなるほどrの向上が困難になることを考慮すると、n×pの向上においてはpの向上を優先する必要がある。以上を考慮し、ペタフロップスマシンを実現するための技術開発の指針を一言にまとめるならば、次のようになる。
[指針]
pの向上を最大限に考慮した上で、n×pの1,000倍の向上を図る。さらにこの過程でのnの増大がもたらす影響を克服し、rの維持あるいは向上を図る。
ここでr、n、pそれぞれの現状ならびに向上努力の動機について概観する。
rの向上は、並列プロセッサに特有な重要課題であるため、大規模並列処理技術の中心として世界的に研究されている。
pの向上には、大きな利潤をもたらすマイクロプロセッサ向き商用技術としてアメリカを中心に盛んに投資されている。マルチメディア応用等があるためMIPSのみならずFLOPSにも競争があり、商用マイクロプロセッサにも高性能な浮動小数点演算器が搭載された。そのため、商用マイクロプロセッサ技術はペタフロップスマシンのために極めて有用と考えられる。
nの向上の直接的な素地は高密度実装技術にある。高密度実装技術には、主としてバイポーラLSIを多数搭載することで高性能を実現するメインフレーム計算機向き技術として投資されてきた。メインフレーム計算機が大きな利潤をもらたしてきたのは周知の通りである。また、この分野では日本企業に一流の技術があるのも周知の通りである。そのため、ペタフロップスマシンの開発においては日本の貢献が重要である。
しかし、n×pの大幅な向上については、科学技術計算向き並列型スーパーコンピュータ実現のために必要とは考えられたが、その市場規模があまりに小さいため大規模並列プロセッサに特化したn×p向上のための技術開発への投資は積極的には進められなかった。そのため、n×p向上の究極の姿を考慮したr向上の研究も進んでいないと言える。思いつきの範囲を越えないのは承知で例示するが、例えば下記のような研究テーマが有り得ないと誰が言えようか。
(1) LSIの発熱量を抑制し実装密度を高めるためのプロセススケジューリング方法の研究
(2) LSI微細化を演算器幅拡大・演算精度向上に利用することで収束性を向上する算法の研究
ペタフロップスマシンのような高い目標を達成するためには、n×p向上のための技術にブレークスルーが必要である。ブレークスルーは日常の常識の外に存在するはずである。そのためには、上記のように一見すると日常の常識の範疇にないような、設計の階層を越えたコンピュータ技術のシステム的な総合最適化のためのアイデアが必要と考えられる。学術面と企業の連携も必要になる。アメリカのマイクロプロセッサの成功にしても、カスタムLSI設計の最適化ということで、コンパイラ技術やアーキテクチャ技術から回路技術までの設計階層を越えたシステム最適化の結果と見ることができる。
コンピュータ技術のシステム的な総合最適化というキーワードのレベルなら学術面でも企業でも共有できる。しかし、これを具体的に推進するための目的ならびに意図は、学術面と企業では一致しない。なぜなら具体的な推進には相応の投資が必要だが、学術面と企業では投資の回収に対する考え方が異なるからである。
しかし、推進するための目的ならびに意図が完全に一致はしないにしても、全く異なっているという訳でもない。そのため、共通点と相違点を浮き彫りにし、それぞれに対する育成計画を具体化することがペタフロップスマシン開発を遂行するための課題になる。
現在のコンピュータ企業はコンピュータ技術のシステム的な総合最適化というキーワードを、主として商用マルチプロセッサのための技術開発に関連すると受け取る。多くの企業の行動指針には社会貢献が含まれているだろうが、コンピュータ開発関連投資が膨大になった現在、企業の存在基盤確保なくしては、ペタフロップスマシンのような社会貢献的な事業は推進できない。
多くのコンピュータ関連企業は、目下その存在基盤確保のためビジネス用途向きの大型サーバに視点を置いている。その大きな理由は下記のような市場ニーズの変化にある。
近年の商用マイクロプロセッサ技術の急速な進展に伴い、ビジネス用途向きコンピュータの価格性能比が急激に向上した。そのためダウンサイジングということで商用マイクロプロセッサベースの情報機器による分散処理が進み、情報機器数が増大した。その結果、情報機器の管理コストが急激に増大し、これの削減が望まれている。
また、ビジネス用途向きコンピュータ開発への参入が容易になり多数のコンピュータ企業がさまざまな製品を投入する中で、ソフトウェアのポータビリティを確保していくためOSの業界標準化が進んだ。その結果、新しく開発される魅力的なソフトウェア製品も業界標準OSをターゲットにするようになり、業界標準OSの搭載を無視したコンピュータ製品の商品価値は著しく低下した。
また、商用マイクロプロセッサベース情報機器の価格性能比の急激な向上に伴い、従来型のメインフレーム計算機の割高感が著しく増加した。そのため、従来型メインフレームを置き換えられるような商用マイクロプロセッサベースのコンピュータが求められている。
これらのニーズを解決するために、商用マイクロプロセッサを利用し業界標準OSを搭載したビジネス用途向きの大型サーバが注目されている。大型サーバには従来ソフトウェアの継続使用等のニーズもあるため、共有メモリ型マルチプロセッサ方式が主流になっている。これらの大型サーバ製品は性能面・信頼性機能面双方での多数企業間の競争が激しく、著しい進歩を遂げてきたし、この進歩は当面続くと考えられる。
ところで、大型サーバと言っても、並列プロセッサの一種であるため、その性能は、
でモデル化できる。r向上のための課題や方法論はペタフロップスマシンとは異なるが、ペタフロップスマシンの要素プロセッサにマイクロプロセッサが有望であることも考慮すれば、n×pの向上という観点からは共通点がある。
また、大型サーバは共有メモリ型を基調にする一方、ペタフロップスマシンは分散メモリ型が基調と考えられている点が異なるように見えるが、もしペタフロップスマシンを共有メモリ型マルチプロセッサ構造を内包するクラスタ型で検討するなら、n×p向上の共通点はますます高まる。
信頼性機能については大型サーバとペタフロップスマシンと概ね共通と考えられる。
つまり、個々の要素技術開発という面からは、大型サーバとペタフロップスマシンとの間に多くの共通点を見い出せるはずである。
ペタフロップスマシンは、個別要素技術の進展のみならず要素技術相互間の総合的な最適化なくしては実現しえないことは既に述べた。そのためには、いわゆる並列処理技術の範疇にとどまらず半導体技術を含めたハードウェア技術開発のための活動も必要になる。マイクロプロセッサ技術などはアメリカに一日の長があるため、この活動には当然国際的な協力が含まれる。
その一方、ペタフロップスマシンそのものの市場規模は小さく、これ自体を目的にした技術開発活動は企業には困難である。特に企業の貢献が期待されるハードウェア技術の開発には多額の投資が必要なためである。
こういう環境の中で、ペタフロップスマシン実現に利用できるハードウェア技術開発を推進するためには、企業が注目している商用マルチプロセッサとペタフロップスマシンの共通点と相違点を明確にし、それぞれに対する国家レベルの育成計画を立案していくことが必要になる。
共通点については、企業の独創性や自主性を重視し激烈な企業間競争を通じた発展を促すことが効率的と考えられる。そのため国家としては、企業間競争を加速させるための規制緩和ならびに、ペタフロップスマシンとの共通技術の開発加速を誘導するための税制面での優遇措置を通じた制度支援を中心にして育成計画を立案すべきと考える。
相違点については、企業には積極的に取り組みにくい項目であるため、国家がリーダシップを発揮して推進していく必要があろう。具体的には国家プロジェクト体制での推進になるだろう。ただ前述の通りペタフロップスマシンの実現には国際協力が欠かせないので、国外企業を含めた体制の確立が必要になる。しかし国家の指導という形では国外企業が参加できる筈もない。それゆえ参加する企業にとってのメリットを熟慮し、積極的に参加できるような魅力あるプロジェクトを世界に提示しなければならない。もちろん、多額の国家経費の投入が必要になる。ただ多額の国家経費の投入にあたっては、その根拠や効能を納税者たる国民にわかりやすく説明する必要があることは言うまでもない。それは誰もが納得する基本コンセプトの提示であり、目標とする夢の提示でもある。つまり、国民にとっても魅力あるプロジェクトを立案する必要がある。
また、共通点の技術開発を推進するための制度支援と、相違点の技術開発を推進するための国家プロジェクトは表裏一体なことを忘れてはならない。そのため両者が互いに良い影響を及ぼしあうようにコントロールするための機構、言わば「メタ国家プロジェクト」の確立と維持も必要である。この機構が「ペタフロップスマシン開発」を手段と認識し、その目的を国民から見てクリアに定義すること、そして時代の趨勢とともに目的を随時更新していき、目的が色褪せてしまわないように機能していくことが、開発を成功させるための最重要課題と考える。
1チップ内集積度の向上ならびにDRAM混載チップの出現により、家電、オーディオ、車載用コンピュータ、PDA、プラント制御、ポケットゲーム等あらゆる電子製品の分野で、さらなる高度情報処理を可能とするシステムが1チップで実現可能となってきた。1チップでシステムの持つ機能を全て実現できるので、このようなシステムはSystem on a Chip(以降SOCと略する)と呼ばれている。SOCの台頭は、さらなる付加価値の高い電子製品が実現できるだけでなく、従来組み込むことが出来なかった製品にも組み込まれることが可能となってきた。このような背景の下、製品開発競争の激化により、短期間に限られたハードウェア資源上で、付加価値の高い電子製品開発を可能とする環境が必要とされている。例えば、MPEGエンコーダを搭載したマルチメディア対応チップの製品開発には、3年間で60名規模の人材が必要とされる。延べ180人年のマンパワーを要しているが、180人いれば1年間で開発が完了できるというものではない。設計試作の短縮化のための開発環境の整備、すなわち、CAD、コンパイラ、組込み型実時間オペレーティングシステムの整備が必要である。
SOCは、組み込み用計算機としての用途だけでなく、SMP型並列計算機や次世代超並列計算機[3]高速ネットワークルータの要素技術として使われる重要な電子産業基盤でもある。このような観点において、SOCは21世紀の産業基盤となる重要な領域と位置づけられる。
SOC関係では、ハードウェアあるいはアーキテクチャの観点から研究開発支援の必要性が言われてきている[1]。ここではSOC開発ための支援ツールおよびSOCを使ったシステムを開発するときのシステムソフトウェア技術およびその研究開発支援について筆者の思うところを述べてみる。
従来より、ハードウェア記述言語で記述されたシステムのシミュレータ、論理合成ツール、論理レベルのシミュレータ、レイアウトツール等がCADとして提供されてきている。これらツールの中には数日から月単位の処理時間を必要としていて、短期間の設計を可能とするためには高速計算機を必要としている。
限られた開発期間内にシステムを開発するためには、チップやボードの試作品を作成する前に、チップ内部のシミュレーションだけでなく、チップを含むシステム全体をシミュレーションし、動作検査できる環境が必須である。このようなシミュレーション環境は製品毎に構成が異なるので、システムを検査するためのツールを構築するためのツールが必要となる。このようなツールは、単にハードウェアの機能検証だけの目的だけでなく、ファームウェアあるいはソフトウェアの開発、改良のために使われ、ハードウェアの開発と並行してソフトウェアの開発も可能となり、開発の短縮化に貢献する。より複雑なシステムチップを短い設計サイクルで実現するために、Virtual Socket Interface(VSI)とよばれる業界標準化の動きがある[2]。VSIでは、チップ内で使用される機能ブロックのIP (Intellectual Property)を保護し、ユーザがIPプロバイダの提供するVirtual Component(VC)を利用するために必要なインタフェースを規定しようとしている。設計支援ツールはこのようなインタフェースを含む形で構築される必要があるであろう。
現在のオペレーティングシステムは、組込み型オペレーティングシステムとPCやワークステーション用のオペレーティングシステムとで異なっている。今後重要となるのは、オペレーティングシステムの部品化である。組込み型計算機の上でのプロセス管理は、ワークステーション用のプロセス管理とは異なる。プロセス間交信も異なる。システムコールレベルあるいはライブラリレベルでAPIを統一し、プログラマの学習時間の軽減をはかることによって、開発コストを軽減することが可能となる。
従来の組込み型OSは、多くの場合既存のMPUを持ったシステムを想定している。従来自前でランタイムを用いていた製品にもオペレーティングシステムの必要性が増大するだろう。
実時間処理用OSと言う観点からは、組込み用途を主としたITRON[4]、Unixの拡張としてのPOSIX Real-Time Extension、Free OSとしてもっとも多くのプラットフォーム上で稼動するLinuxを拡張したReal-Time Linux[5]等がある。また、組込み型プロセッサ上でのOSとしてuITRON、Embedded OS-9、pSOS、Embedded OS/2 Warp等も存在する。これらオペレーティングシステムは、プロセッサとしては汎用マイクロプロセッサあるいはマイクロコントローラを想定している。今後、SOC向けの機能が限定されたオペレーティングシステムが必要とされるであろう。
組込み型計算機用プログラミング言語に求められているのは、実時間処理記述と適応可能性である。実時間処理記述においては、タスクの実時間制約記述により静的にデッドラインが満たされるかを検証できるような処理系が望まれる。今までの実時間処理記述言語は、時間制約記述は存在する[6]。時間制約記述により制約のあるタスク間でのスケジューリングが可能かどうかの検査は可能であっても、記述された制約自体が与えられた計算機上で制約が満たされるかどうかを静的に検査する処理系は存在しなかった。今後、ソフトウェアの設計およびプログラミング時に時間制約が満たされるか、必要とされるメモリ容量がどのくらいかを予測できる処理系が必要である。
特殊ハードウェアによる製品開発を短期間で成し遂げるためには、特殊ハードウェアを容易に制御できるプログラミング機能が提供されなければならない。新しいハードウェア毎にそのためのプログラミング言語を開発する時間はない。そこで、プログラミング言語自体が新しいハードウェアに応じたプログラミング構文や最適化が提供できる枠組みが望まれる。これを実現する要素技術としてはコンパイル時リフレクションと言う概念がある。
(1) SOC
家電製品、PDA用組込みチップSOCを用いた製品における大きな市場の一つは、言わずと知れたコンシューマ向け製品である。マルチメディアのためのデータ圧縮機能とネットワーク機能を搭載したSOCは大きな市場となる。
(2) 次世代並列計算機用チップおよび用途
DRAM混載型チップにより1チップで4から8個のプロセッサとメモリを搭載することが可能となると、現在のTeraflops級計算機が一つの筐体で実現できるようになる。次世代並列計算機と言ったときに、Petaflops級計算機ではなく、現在のサーバ計算機のような一つの筐体に納まった計算機がTeraflops級の処理能力を持つ計算機のことを指すべきである。Teraflops級計算機は、CADソフトウェアや自然環境シミュレーション等の計算科学に使われるであろう。SOC設計支援環境としてのCADソフトウェアがこのような計算機上で実現されることにより、論理合成、論理レベルシミュレーション、レイアウト、回路シミュレーション等が短時間で終了することが可能となる。これにより設計のサイクルが早まる。
自然環境に関するシミュレーションでは、地震が起こってからの津波予報、都市火災や山火事における効果的消火活動を支援するためのシミュレーション等では、リアルタイム処理以上の処理による高速シミュレーションを必要とする。
Teraflopsの次にくるPetaflops級計算機の用途の一つは、分子動力学シミュレーションによる計算科学である。例えば計算分子生物学の世界では、タンパク質立体構造予測がある。タンパク質立体構造が予測できると新薬の開発に利用でき、その市場は計り知れないものがある。分子動力学シミュレーションによるタンパク質立体構造予測では、現在の数十Gigaflops級高並列計算機において1ナノ秒のシミュレーションに1日強かかるといわれている。現実的に使用可能なのは1ミリ秒のシミュレーションであり、現在の6桁速い計算機すなわちPetaflops級計算機を必要としている[7]。
新情報処理開発機構における64bitsプロセッサ開発経験を聞くと、論理部分で200Kゲートレベルの論理合成に1週間、論理レベルシミュレーションは1秒間に数クロック程度、レイアウトには1ヶ月程かかっていたようである。論理レベルシミュレーションの高速化は、テストパターンを豊富にすることが可能となり早期バグ出しが可能となる。強いては開発サイクルを短くすることに貢献する。
(3)次世代ルータチップ
2から3年のレンジでは、High End Gigabit Ethernet SwitchのためのSOCが重要となる。現在、ハイエンドルータは米国企業の独占状態になりつつある。GigabitEthernetおよび将来のさらなる高速ネットワークに対応したネットワークルータの市場は、今後ますます増大するだろう。
SOC技術の重要性は企業においては既に認識されている。SOC開発のための基盤技術について、企業は既存のCAD製品を利用し、コンパイラはフリーソフトウェアのgnuを利用していたりする。21世紀における我が国の産業基盤である電子製品の国際競争力を維持するためには、CADソフトウェア、コンパイラ、オペレーティングシステムを育成していく仕組みを必要としている。このためには、企業毎にローカルにノウハウを蓄積するのではなく、中立的組織を中心として、産・官・学が協力して基盤ソフトウェアを育成していく必要がある。もし、CADソフトウェア、コンパイラ、オペレーティングシステムが共有されれば、大学、研究機関からの最適化のアルゴリズムやその他新しいアイディアを実際的システムソフトウェアに組み込むことが可能となり、最先端の技術をメーカが享受できるようになるのではないだろうか。情報産業はハードウェア技術のノウハウ蓄積からソフトウェア技術のノウハウ蓄積に比重が変わってきている。ソフトウェア技術の蓄積には、共通基盤としてのソフトウェアが恒常的に保守され、新しい技術を吸収していく枠組みが必要である。
夢のあるプロジェクトという意味では、パーソナルテラフロップス計算機、すなわち、現在、米国の国防関係の研究所でしか利用することが出来ない高性能計算機を個人が持てるようにするための技術開発があげられる。これを遂行するためには、SOC素子技術、SOCのためのシステムソフトウェア基盤技術の整備が必要であり、それを利用したプロセッサアーキテクチャ、通信アーキテクチャ、システムソフトウェアを開発する必要がある。このような総合システム開発を国が主導することは、国内の産業を育成し国力をあげるものであると確信する。
参考文献