高性能コンピューティングを行う最も簡単かつ現実的な方法は、現状では、高性能マイクロプロセッサを多数用いた並列計算方式であろう。この分野は、一部の日本企業、研究者が健闘しており、米国独占が強まる計算機科学の他の分野に比べて、まだしも希望を持つ事ができる。したがって本報告書も中心はこのタイプのアーキテクチャということになるであろう。そこで、この辺の記述は、他の章に譲ることにして、本節ではより将来、7~10年後に、高性能コンピューティングの主流となり得る新しいアーキテクチャである直接解法マシン(Custom Computing Machines)を紹介し、そ
の技術課題、開発状況等をまとめる。
PLD(Programmable Logic Device)は、ユーザが手元でプログラミングすることのでき
るデバイスであり、1970年代から小規模の書き換え不能なものが一部の組合せ回路に用いられていた。80年代にCMOS技術の導入により、再書き込み可能で、順序回路も含む広い範囲の回路を実装することができるようになり、デジタル回路の実装用デバイスとしての地位を確立した。さらに、90年代に入って、大規模なFPGA(Field Programmable Gate Array)あるいはCPLD(Complex Programmable Logic Device)が登場するに至って、システムをまるごと実装可能なデバイスとして進化を遂げた。最近は、100MHz近い周波数で動作する高速なデバイスや、数10万ゲートの実装密度や内蔵RAMを持つものものも出現し、ASICに代わってシステムインテグレーションの主役になりつつある。このうち、内部の配線データ(Configuration Data)をSRAMに格納するタイプは、配線データを入れ換えることにより、電源を入れたままで、ハードウェア構成を変えることができる。この性質を利用し、状況に応じてハードウェア構成を変化させたり、解法アルゴリズムを直接ハードウェア化させることのできるシステムを可変構造システム(Reconfigurable Machine)あるいは直接解法マシン(Custom Computing Machine:CCM)と呼ぶ。
CCMが実現可能になったのは、数千ゲート以上の規模で10MHz以上の動作が可能なSRAM型FPGAが安価に利用可能になった1990年代に入ってからである。実装例の多くは、専用システムの構造に柔軟性を持たせるタイプであるが、このうちのいくつかは、広い範囲に利用することができる汎用システムを目指している。
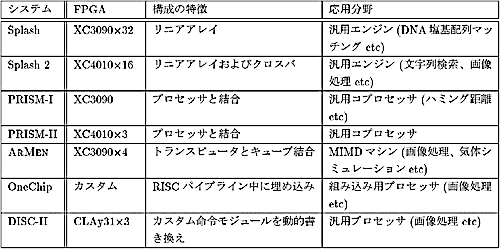
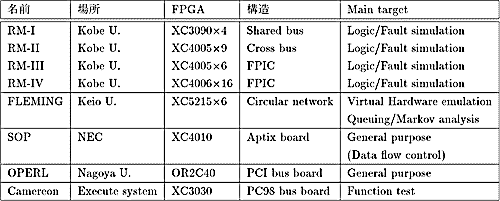
海外の代表的なシステムを表1に、国内のシステムを表2にまとめる。ここでは、代表として、米国の計算機科学センター(旧SRC)のSplashプロジェクト[1][2]のみを紹介する。他のCCMについては、最新のサーベイが[3][4]に掲載されているので、参照されたい。
SplashプロジェクトではFPGAとメモリからなる計算セルを直線状に並べることにより、汎用計算機と専用計算機の中間的な特徴を持つ可変構造システムの研究開発に取り組んでいる。図1にSplash 2の構成を示す。この図は3ボードからなるシステムを示しているが、各ボード上ではXilinx社のFPGAであるXC4010が計算用に16個(X1~X16)、制御用に1個(X0)使用され、これらがクロスバを介して結合されている。また、各FPGAは256K×16ビットのローカルメモリを持っている。計算用の16個のFPGAはリニアシストリックアレイを構成しており、その結合の幅は36ビットである。X0のFPGAはクロスバの制御にも用いられる。
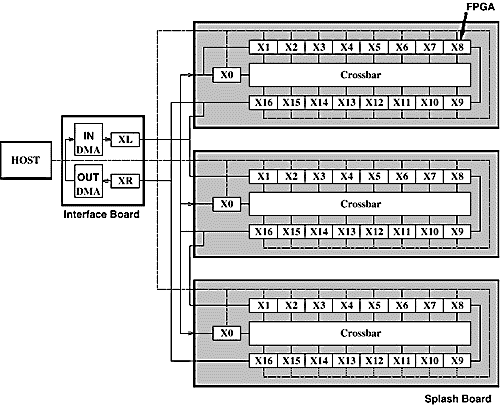
Splashボードは、インタフェースボード上のそれぞれ2つの入力FIFO(First-In First-Out)と出力FIFOを介して、ホストのSUN Sparc Station IIと通信することができる。入力FIFOは36ビットのデータをX1に送り、出力FIFOは32ビットのデータをX16から受け取る。図1からも明らかなように、入力FIFOの内容をX0に与えることにより、入力FIFOからのバスはSIMD (Single Instruction stream and Multiple Data stream)バスとしても機能するようになっている。その場合、クロスバは命令をブロードキャストする一方で、データをX1からX16に分配する。このようなクロスバの制御はX0が行う。また、各チップからは1本の割り込み制御線が、それぞれホストと接続されている。
Splash 2のプログラムはハードウェア記述言語であるVHDLで記述される。その際、VHDLの動作レベル記述と構造レベル記述を混在させることができる。VHDLでプログラムを記述した後は、Splash 2シミュレータを用いて機能検証とデバッグを容易に行うことができる。したがって、記述したアルゴリズムが機能的に正しいことを確認するまでは、論理合成などの比較的時間のかかる処理を行う必要がない。
また、論理合成された回路を実際にシステム上で動作させる段階でのデバッグ機能も充実しており、シングルステップ実行機能や各FPGA内部のフリップフロップを読み出すリードバック機能などを備えている。特に、リードバック機能は、デバッグ時だけでなく内部レジスタに格納された計算結果の読み出しにも利用することが可能である。
Splashプロジェクトでは、幅広い分野のアプリケーションが実装され、多くの成果を挙げている。Splash 2の前身であるSplash 1ではDNAの塩基配列間の距離を求める計算で、スーパーコンピュータCRAY-2の330倍の性能を得て大きな注目を集めた。また、Splash 2でも文字列検索や画像処理などのアプリケーションが実装されている。このようにSplashでは、そのリニアアレイ構造を活かせるパターンマッチングや画像処理など、常に入力されてくるデータをパイプライン的に処理するようなアプリケーションでは大幅な性能向上を示している。一方で、FPGA間の結合の自由度が低い点や任意のメモリへのアクセスが困難な点などから、有効性のある適用分野もある程度限定されている。
CCMの問題点としては以下の2点が従来から指摘されている。
この問題点の解決については、筆者らの提案する方法を含め、様々な方法が提案されており、見通しはある程度ついている。前者の問題については問題をデータフロー言語や拡張C言語で記述し、データフローグラフを経てハードウェアに変換する方法は既に確立している。後者の問題についてはマルチファンクションあるいはマルチコンテキスト機能を持つFPGAやDRAM混載型FPGAによる仮想ハードウェアの実現方法が検討されている。いずれも困難な点は残されているが、道筋はついていると思う。論文[5][6]などを参照されたい。
ここでは、対象をスーパーコンピューティングに絞って、より本質的な問題点について議論する。CCMは確かに特定の分野では、ワークステーションや時にはスーパーコンピュータを上回る性能を実現する。前述のSplashは、DNAの塩基配列間の距離を求める問題、神戸大学のRM-Xでは、論理シミュレーション、故障シミュレーション、我々の開発したFLEMINGでは、マルコフ解析、待ち行列解析で、ワークステーションやスーパーコンピュータの数倍から100倍近い性能を発揮している[3][4]。しかし、これらの問題は、以下の二つの性質のいずれをも持っていないものに限られている。
(1) 10倍×10倍のハンデ
IEEE標準の浮動小数点演算を行う場合、FPGAと、高性能プロセッサに用いられる専用の浮動小数点演算用LSIでは、動作速度で10倍、実装面積で10倍の差があるといわれている。これは以下の原因に基づいている。
このうち、(a)に関しては、ごく最近になってようやくFPGAに最新のプロセスが用いられるようになり、改善されつつある。しかし(b)の問題点はFPGAが柔軟性と引き替えにした本質的なものである。したがって、将来にわたってもFPGAによる浮動小数点演算器は専用LSIに比べ速度、面積の両面で5倍以上のハンデを背負うことになるだろう。このハンデを克服するためには以下の方法が考えられる。
(a) アプリケーションにあったデータ幅を用いる。
現在のIEEE標準の32bit/64bit浮動小数点データ型は多くのアプリケーションをカバーするが、アプリケーションによっては、長すぎたり、短すぎたりする。対象アプリケーションに適合するデータ幅が標準と大きく異なる場合、CCMはこれに合わせたデータ幅を利用することにより、ハンデを大きく縮めることができる。場合によっては、1回の演算速度で優位に立つことができる。ニューラルネットワークシミュレータや、一部の信号処理で、このような利点を生かして高速化した例が報告されている。ただし、この方法を用いるためには、様々なデータ幅で高い効率を実現する演算器のマクロが整備されていることが必要である。
(b) 並列演算、他の演算との組み合わせ、データの流れの最適化を図る。
通常の浮動小数点演算器も多数接続して並列処理を行うことができるが、CCMの場合は、接続を柔軟に変化させ、データのやり取りを含めて最適化することができる。また、アプリケーションによっては、ビット演算やパタンマッチング等FPGAの得意な演算と組み合わせることも可能である。ただし、この利点を発揮させるためには1チップ上に複数の演算器を実装できるようになることが前提である。
この両者の組み合わせがうまく行けば、CCMは同一コストで構成された高性能演算プロセッサによる並列計算機と比べても高い性能を実現できるだろう。まともにIEEE標準データで戦っては将来に渡っても勝ち目がないことを認識すべきである。
(2) メモリとの接続はチップ内部で。
CCMがメモリを大量に用いる処理に弱いのは、メモリとの接続が通常の計算機に比べ貧弱なためである。なにしろ通常のプログラム格納型計算機はCPUとメモリを結ぶラインが命であるため、最大限に高速化してある上、キャッシュもついているし、容量に関しては仮想記憶によってディスクを借りることだって可能である。CCMもそれぞれの構成要素のFPGAにメモリを接続した構成を取る場合が多いが、容量、速度共にプログラム格納型計算機には遠く及ばない。
この点を解決するためには、DRAM混載型FPGAが不可欠である。DRAM混載型FPGAは、チップ内に複数の回路を持つ方式(マルチコンテキスト)への利用も期待されるが、単純にデータの記憶という点でも重要である。内部に複数のDRAMモジュールが装備され、演算器と柔軟に接続することができれば、メモリと演算器の接続に柔軟性を欠くプログラム格納型計算機に比べてDRAMの転送容量をうまく利用することができる可能性もある。
以上、CCM型のスーパーコンピューティングシステムが現実となるのは、
もちろん、CCM全体の問題であるプログラミングの問題と仮想ハードウェアの問題もクリアされていることが望ましい。これらの条件のうち、(a)は放っておいても2,3年後にはクリアされるだろう。他の条件も努力次第で5年以内に整備することが可能であり、3年後くらいにこれを見越して大型プロジェクトをスタートさせるのがよいと思う。日本が大型プロジェクトとして主にやるべきことは(b)である。DRAM混載型FPGAは既にNECにより提案されており[7]、このチップの性能はMITで開発中のDISC-II[8]をはるかに上回っている。しかし、現状では商業ベースで採算が取れる見込みがないため、実際に製造することができないでいる。FPGAの実装技術は日本は遅れているが、DRAM混載チップについては世界に先んじているので、この周辺の技術開発については政府のプロジェクトでもっと後押ししてもよいと思う。(c)については大学の共同プロジェクトで整備する計画があり、数年後には実現する予定である。
さらに、日本企業は、日本で生まれた技術をもう少し積極的に利用してもいいのではないか。例えばXilinx社が昨年提案し、特許を取得したTime Multiplexed FPGA[9]は、SRAMモジュールをFPGA内部に複数持つことにより、高速に内部回路を切り替える方式であるが、1990年に富士通が特許を取得したMPLD[10](Multi-functional Programmable Logic Device)とまったく同じアイディアである。この方式に関しては10年近く先んじていたのである。MPLDの特許は国内のものだが、この方式は我々がWASMIIプロジェクトで利用していることから、特許の存在を明記した英語の論文を多数書いており(例えば[5])、Xilinx社も当然認識していたと思う。
とはいえ何より問題なのは、特許を取ってもまったくチップを実現できず、結局Xilinx社による商品化を待つしかなかったことで、大変に残念である。今後も、仮想ハードウェアや適応型ハードウェア等の分野で、日本ではるかに先んじて提案されている技術を、米国の企業が(多分無断で)実現していく状況が生じてくることが予想される。もったいない話である。
参考文献
ペタフロップスマシンを検討する際に、とかくpeakパフォーマンスに目を奪われがちになる。しかし、単純にプロセッサの性能と数を掛け合わせた値には意味がなく、必要とされる性能はアプリケーションプログラムを実行した場合の実効flopsである。ペタフロップスマシンは大規模な並列計算機で構成せざるを得ず、peakパフォーマンスと実効パフォーマンスの乖離が顕著になると考えられる。本報告ではこのような性能の乖離を引き起こす要因となる、ネットワークに関して検討を行う。
ペタフロップスマシンの実現性の検討を行う場合、単純にプロセッサの性能とプロセッサ数を掛け合わせた値は意味がない。当然、目的とするアプリケーションを実行した場合の実効flopsをどのように向上させるかが重要である。数値計算向けのシステムを構成する要素の中の主だったものとして、
がある。このうち、peak flops性能に影響を及ぼすのはCPUとメモリのみで、他はflops性能には直接反映されない。CPUとメモリに対して既存のハードウェアがどのようなバランスを持っているのかを見るため、1CPUあたり、ほぼ2Gflopsの演算性能を持つ富士通のVPP700と、日本電気のSX-4の諸元を以下に示す。スループットは1W = 8 Byte = 1 floating word として表した。

このように、ベクトルプロセッサのベクトル性能とメモリスループットはほぼ1対1に設計される。それに対して、疎結合部分を持つVPP700のノード間スループットは0.14 GW/sとなっておりCPU間結合網のバンド幅は1桁以上小さいことになる。
プロセッサ数が十分に少ない場合には各プロセッサが各自のメモリとの間で処理を行い、別プロセッサとの間でデータの交換頻度が少ない計算方式を取る場合にはこのようなスループット配分で構成が出来る。
しかし、ペタフロップスマシンを構成するために必要なプロセッサ数は、次の表のように10万プロセッサ程度に達すると考えられる。プロセッサ数が極端に多くなると、メモリバンド幅にくらべ、プロセッサ間の通信を大幅に減らすことは困難であろう。そのため、メモリ対CPU間スループットの比率は、より1対1に近付けなければならない。

このことを、比較的素性が良いと思われるFFT演算で考えてみる。FFT演算を1プロセッサで実行する場合、一般に2n点のFFT演算はオーダとしてn(2n)回のバタフライ演算が必要で、メモリへのアクセスも同じオーダ必要となる。一方、2プロセッサで実現する場合には、1プロセッサあたりn(2n)/2回のバタフライ演算と、同数のメモリアクセス、2n回のプロセッサ間通信が必要になる。これを表にまとめると次のようになり、通信量はメモリアクセスとオーダ的には同程度必要になることが分かる。
| CPU台数 | 演算回数 | メモリアクセス回数 | 通信回数 | 通信/メモリ比 |
| 1 | n(2n) | n2n | 0 | 0 |
| 2 | n2n-1 | n2n-1 | 2n | 2/n |
| 2m | n2n-m | n2n-m | 2m・2n-m | 2m/n |
このように、分割数を多くすると通信量が増加することは、全体の計算をメッシュ上に切られたプロセッサに割り当てた時、メッシュの1目の体積が計算量に、1目の表面積が通信量に比例すると考えても説明がつく。
従来のベクトルプロセッサでは、接続ビット幅をかなり広くとることによりCPUメモリ間のバンド幅を広げて来たが、大規模な並列計算機のCPU間接続網をビット幅が広いネットワークで作成することは物理的に不可能である。したがって、高いスループットを達成するために、伝送路1本あたりの転送bit rateを高くすることが必要となる。
現在商品化あるいは商品に近い形で実現されている相互接続網技術でもっとも高速なものは10Gbit/s程度のものである。これは、ワード換算で0.2GW/sの転送レートをもつ相互接続網と言うことができ、線あたり400Mbit/sのデータ転送レートで4B 並列伝送することにより実現されている[3]。
ネットワークバンド幅をメモリバンド幅と同程度すなわち、flops値と同程度にするためには、10Gflopsのマシンには、10GW/sのメモリバンド幅と10GW/sのスループットを持つ相互結合網が必要になる。このためには、現在のネットワークスループットを更に1桁以上向上させる必要がある。現時点では、電気伝送で数メートルの距離を信号あたり4-10Gbpsぐらいの転送レートで伝送することは実現可能な範囲であると考えられている[1][2]。
このように、ネットワークスループットを向上させた場合でも、ネットワークのレイテンシを減らすことは出来ない。10万プロセッサを3次元に構成すると考え、50×50×50の3次元メッシュ構造に並べると考える。
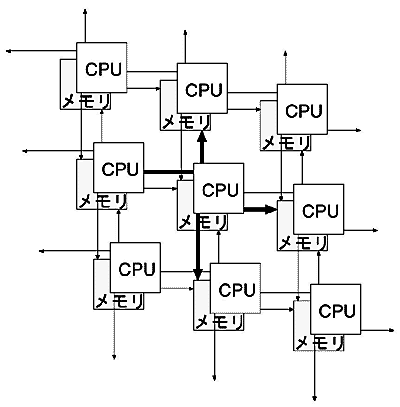
単体のプロセッサの大きさを冷却のための装置、空間を含めて20cm立方とすると、縦横高さ10mの大きさになる。この場合最も遠い対角線の距離は 直線距離で17mになる。ここを20cm/nsのケーブルで直線で配線すると85nsの遅延が電線上の伝送遅延として必要である。想定されるシステムの要素プロセッサの速度を10Gflopsと仮定すると、最大遅延時間は電線のみで1,000 flop程度の演算に相当する時間である。物理的に近接しているノードでは、必要な遅延時間はもっと小さくすることが出来る。ノード毎に考慮すべき点を少なくするために、すべてのノード間の通信を最大遅延まで遅くすることも出来る。しかし、全体が遅くなってしまうのでノード間通信は不均等にせざるを得ないだろう。例えば、図1に示すように、ネットワークとしてはメッシュネットワークが物理的実装に一致するため、隣接ノードを高速に結べ実現が容易である。
高速伝送路の技術として、光結合が検討されることが多いが、光通信は短距離伝送においては必ずしも適切な通信方式とは言えない。これは、現状の光通信における一般的技術では、電気的処理を施す際に直並列変換を施してデータ幅を増加させbit rateを下げている。低速クロックの部分で多くのバッファリングが行われる結果、point to pointの遅延時間が大きくなってしまう。また、次に述べるようにLSIの内部速度に比べてLSIのIO速度が小さいと言う点は、光結合を持ってきても解決できない。
名目上のペタフロップスマシンを作成する場合はともかく、実質的に意味を持つマシン開発のために、最も重要なのは、要素プロセッサよりも結合網と並列計算に適応したアプリケーションプログラムである。ベクトル用要素プロセッサとしては、2Gflopsの要素プロセッサが構成されている(1997年の時点で)が、これを10Gflopsにスケールアップすることは簡単ではない。
表4にSIAの予測とそれから計算されるチップ内のTr数とチップ内クロック積、及びIOピン数とチップ外に出せるクロック積を示した[4]。
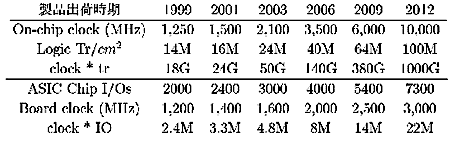
この表から明らかなように、Clock・Tr積は1999年から2012年に掛けて50倍以上に増加するのに対して、Clock・IO積は9.2倍にしか増加しないと予想されている。チップ面積の増加を考慮すると、Clock・Tr積は1999年からの13年間に100倍に増加すると言うことになる。
結局、演算器数は、チップ内のトランジスタの増加により増やすことが出来るが、CPUに供給するデータの出入口であるピン数はそれほど増加しないことを示している。更に、DRAMのランダムアクセススループット、すなわちアクセス速度がチップ内速度ほどは向上しないことを合わせると、メモリからのバンド幅はチップ内の論理回路の速度向上ほどは増えないと言うことも分かる。
これらを多少とも改善するアーキテクチャ面での工夫はあると思うが、実アプリケーションでの性能を左右するマシンの基礎体力は、高速ロジック、高速伝送技術などのベースとなる技術の性能に強く依存する。特に、通信分野ではあまり重要視されてこなかったCMOSでの電気伝送による高速通信技術は、短レイテンシを要求するシステム内接続網に最も重要な技術である。この技術の開発は、高並列システムには必須の技術であるが、学会発表を見る限り米国の方が進んでいるため、この方面の開発促進は重要な課題となる。
現状では産業界が独自にペタフロップスマシンを開発することは考えにくいので、ペタフロップスマシンの実現のためには、国が産業界を牽引する形で実現する必要がある。現時点でペタフロップスマシンの意義は、巨大加速器と同じように科学技術の進展のためと言う側面が大きいが、ペタフロップスマシンを構成するいくつかの技術の中で、他への波及効果が期待できる基礎技術が含まれている。ペタフロップスマシンはこのような様々な技術への影響を及ぼす基礎的技術開発を推進すると言う意味の指標として取り組むことが良いと考える。
参考文献