
戞3復丂僴僀僄儞僪僐儞僺儏乕僥傿儞僌尋媶奐敪偺摦岦
4.丂SCIMA偵偍偗傞掅徚旓揹椡壔
4.1丂儊儌儕僩儔僼傿僢僋嶍尭偵傛傞掅徚旓揹椡壔
丂SCIMA偼丄SCM丒庡婰壇娫偺僨乕僞揮憲傪丄page-load/page-store柦椷偵傛傝柧帵揑偵峴偆偙偲偱丄SCM偺僨乕僞傾儘働乕僔儑儞丒儕僾儗乕僗儊儞僩傪儐乕僓偐傜惂屼壜擻偱偁傞丅偦偺偨傔丄昁梫側僨乕僞偺傒傪昁梫側僞僀儈儞僌偱揮憲偡傞偙偲偑偱偒傞丅堦曽丄僉儍僢僔儏偼僴乕僪僂僃傾惂屼偵傛傝寛傔傜傟偨傾儖僑儕僘儉偱偦傟傜偺惂屼偑峴側傢傟傞偨傔丄屄乆偺僾儘僌儔儉偵嵟揔側僨乕僞傾儘働乕僔儑儞丄儕僾儗乕僗儊儞僩傪峴傢偣傞偙偲偼擄偟偄丅椺偊偽丄僜僼僩僂僃傾揑側庤朄偱僨乕僞偺嵞棙梡惈傪岦忋偝偣傞僉儍僢僔儏僽儘僢僉儞僌乮僞僀儕儞僌乯[4]傪揔梡偡傞応崌丄僉儍僢僔儏偱偼儔僀儞僐儞僼儕僋僩偵傛傞摨堦攝楍偺僽儘僢僋撪僨乕僞偺姳徛乮self
interference乯傗丄堎側傞攝楍娫偺僨乕僞偺姳徛乮cross interference乯偵傛傝丄僆僼僠僢僾儊儌儕僩儔僼傿僢僋偑憹壛偟偰偟傑偆丅SCM傪棙梡偡傞偙偲偱丄SCIMA偱偼僉儍僢僔儏偵斾傋埲壓偺揰偱僩儔僼傿僢僋偑嶍尭偱偒傞丅
乮1乯 僐儞僼儕僋僩儈僗偑惗偠側偄偨傔丄嵞棙梡惈偺偁傞僨乕僞偑嬼慠偵嵞棙梡惈偺側偄僨乕僞偵傛傝捛偄弌偝傟傞偙偲偑側偔丄廬偭偰僨乕僞偺嵞棙梡惈傪嵟戝尷偵妶梡偱偒傞丅
乮2乯 揮憲僒僀僘偑壜曄偱偁傞偨傔丄僗僩儔僀僪揮憲偲側傞応崌偵丄昁梫側偄僨乕僞偺揮憲偑梷惂偱偒傞丅
僾儘僙僢僒丒庡婰壇娫偺僨乕僞揮憲偱偼丄晧壸梕検偺崅偄奜晹偺儊儌儕僶僗傗I/O僷僢僪傪嬱摦偡傞偨傔丄徚旓偝傟傞揹椡偑懡偄丅僉儍僢僔儏偵斾傋僆僼僠僢僾儊儌儕僩儔僼傿僢僋偺嶍尭偑婜懸偱偒傞SCIMA偱偼丄掅徚旓揹椡壔傪恾傞偙偲偑偱偒傞偲婜懸偝傟傞丅
4.2丂慖戰揑僂僃僀傾僋僙僗偵傛傞掅徚旓揹椡壔
丂廬棃偺N僂僃僀楢憐僉儍僢僔儏偱偼丄僉儍僢僔儏傾僋僙僗偑敪惗偡傞偲丄傾僋僙僗偝傟偨傾僪儗僗偺Index晹傪僨僐乕僪偡傞偙偲偱丄奩摉偡傞僉儍僢僔儏撪偺僙僢僩傪寛掕偡傞丅師偵丄奩摉僙僢僩偺僞僌丄偍傛傃僨乕僞傾儗僀偺慡偰偺僂僃僀傪暲楍偵傾僋僙僗偟丄偦傟偧傟偺僨乕僞傪撉傒弌偡丅偦偟偰丄撉傒弌偝傟偨僞僌偲傾僋僙僗偝傟偨傾僪儗僗偺Tag晹暘傪斾妑偟丄堦抳偡傞傕偺偑偁傟偽僉儍僢僔儏僸僢僩偲側傝丄奩摉僂僃僀偺僨乕僞偑慖戰偝傟傞丅偙偺傛偆偵丄慖戰偡傋偒僨乕僞偑僞僌傾儗僀偺撪梕偵埶懚偡傞偨傔丄崅懍壔偺偨傔偵偼慡偰偺僂僃僀傪暲楍偵撉傒弌偡昁梫偑偁傞丅
丂SCIMA偺僉儍僢僔儏丒SCM摑崌婡峔傪恾3偵帵偡丅廬棃偺僉儍僢僔儏偺婡峔偵懳偟丄SCIMA偱偼傾僋僙僗偝傟偨傾僪儗僗偑SCM椞堟偵懳偡傞傕偺偐偳偆偐偺敾掕乮SCM-test乯偲丄偦偺嵺偵偳偺僂僃僀偺僨乕僞傪傾僋僙僗偡傋偒偐偺慖戰乮way-select乯傪峴側偆夞楬偑捛壛偝傟傞丅杮婡峔偵偍偄偰丄SCM-test夞楬偱僉儍僢僔儏傾僋僙僗偲敾掕偝傟偨応崌偼丄廬棃偺僉儍僢僔儏傾僋僙僗偲摨條偺摦嶌偲側傞丅堦曽丄SCM傾僋僙僗偲敾掕偝傟偨応崌偼丄way-select夞楬偵傛傝寛掕偝傟傞僂僃僀撪偺僨乕僞偑慖戰偝傟傞丅偙偺帪丄傾僋僙僗偡傋偒僙僢僩偼丄SCM-test偺敾掕寢壥偵傛傜偢丄傾僪儗僗偺Index晹偺傒偱寛掕偝傟傞丅廬偭偰丄慖戰偡傋偒僨乕僞偺僂僃僀傪僉儍僢僔儏傾僋僙僗帪傛傝憗偄抜奒偱寛掕偡傞偙偲偑偱偒丄SCM傾僋僙僗帪偵偼1偮偺僂僃僀偺傒傪慖戰揑偵傾僋僙僗偡傞偙偲偑偱偒傞偨傔丄徚旓揹椡偺嶍尭偵偮側偑傞丅偝傜偵丄慖戰偡傋偒僨乕僞偑僞僌偺撪梕偵埶懚偟側偄偨傔丄僞僌傾儗僀傊偺傾僋僙僗傪梷惂偡傞偙偲偵傛傞徚旓揹椡偺嶍尭傕婜懸偝傟傞丅
恾3丂SCIMA偺SCM傾僋僙僗
5.丂徚旓僄僱儖僊乕昡壙
5.1丂昡壙儌僨儖
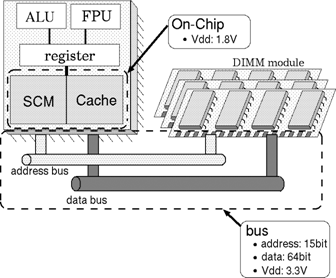
丂SCIMA偺掅徚旓揹椡壔偺岠壥偵偮偄偰挷傋傞偨傔丄僆僼僠僢僾儊儌儕僶僗丄偍傛傃僉儍僢僔儏/SCM傾僋僙僗偵偍偗傞徚旓僄僱儖僊乕傪昡壙偡傞丅側偍丄杮峞偱埲崀僶僗偺徚旓僄僱儖僊乕偲昞婰偟偨応崌偵偼丄僾儘僙僢僒傗DIMM偺I/O僷僢僪偱徚旓偝傟傞僄僱儖僊乕傕娷傑傟傞傕偺偲偡傞丅
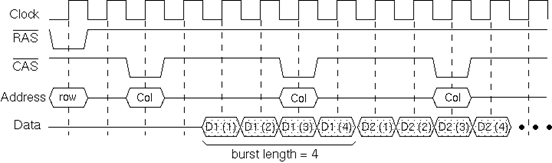
丂杮昡壙偱偼丄庡婰壇偲偟偰SDRAM[5]傪憐掕偡傞丅恾4偼昡壙偵偍偗傞僾儘僙僢僒偲庡婰壇偺儌僨儖傪昞偟偰偄傞丅偙偙偱偼丄64Mx4 SDRAM僨僶僀僗乮4bit暆乯傪16屄暲傋丄64bit暆偺儊儌儕儌僕儏乕儖乮DIMM乯傪峔惉偡傞応崌偵偮偄偰峫偊傞丅偙偺応崌丄傾僪儗僗僶僗偺價僢僩暆偼15價僢僩偱偁傞丅杮峞偱儌僨儖偲偡傞SDRAM偺傾僋僙僗僞僀儈儞僌傪恾5偵帵偡丅SDRAM偱偼row傾僪儗僗偵懕偄偰column傾僪儗僗傪敪峴偡傞偙偲偱丄僋儘僢僋偵摨婜偟偰楢懕側悢僨乕僞乮burst
length暘偺僨乕僞乯偑揮憲偝傟傞丅傑偨丄burst length埲忋偺楢懕僨乕僞傪揮憲偡傞嵺丄row傾僪儗僗偵曄峏偑側偗傟偽丄column傾僪儗僗偺傒傪敪峴偡傞偙偲偱楢懕僨偡傞乕僞偺揮憲偑壜擻偲壖掕偡傞丅側偍丄杮峞偱偼burst
length傪4偲偟偰昡壙傪峴側偆丅
恾4丂昡壙儌僨儖
恾5丂SDRAM偺傾僋僙僗僞僀儈儞僌
5.2丂昡壙曽朄
丂昡壙偵偍偗傞儀儞僠儅乕僋僾儘僌儔儉偲偟偰丄NAS Parallel Benchmarks偺拞偐傜CG丄FT偺2偮偺僇乕僱儖丄偍傛傃拀攇戝妛偺寁嶼暔棟妛尋媶僙儞僞乕偱峴傢傟偰偄傞QCD乮検巕怓椡妛乯寁嶼[6]傪梡偄傞丅昡壙偱偼丄儘乕僪/僗僩傾夞悢丄儊儌儕僩儔僼傿僢僋丄價僢僩慗堏夞悢側偳偺忣曬傪僔儈儏儗乕僞偱嵦庢偟丄徚旓僄僱儖僊乕傪媮傔傞丅偙偙偱丄傾僪儗僗僶僗偵偮偄偰偼丄幚嵺偵價僢僩慗堏夞悢傪僔儈儏儗乕僔儑儞偵傛傝媮傔傞丅僨乕僞僶僗傗僉儍僢僔儏/SCM傾僋僙僗帪偺價僢僩慗堏偵偍偄偰偼丄慗堏妋棪傪0.5偲壖掕偟偰價僢僩慗堏夞悢傪嶼弌偟偨丅徚旓僄僱儖僊乕偼丄暥專[7]偱採埬偝傟偨僉儍僢僔儏徚旓僄僱儖僊乕儌僨儖傪嶲峫偵偟偰媮傔偨丅偦偺嵺丄僠僢僾撪偵偍偗傞僉儍僢僔儏乛SCM傾僋僙僗帪偺晧壸梕検偺僷儔儊乕僞偼暥專[8]偺傕偺傪丄傑偨僶僗偺晧壸梕検偵偮偄偰偼[5]偺傕偺傪嵦梡偟偨丅
丂傑偨杮昡壙偱偼丄僠僢僾撪偍傛傃僶僗偺嬱摦揹埑傪偦傟偧傟1.8V丄3.3V偲壖掕偟偰昡壙傪峴偭偨丅側偍丄傾僪儗僗偺僨僐乕僪偵昁梫側徚旓僄僱儖僊乕傗僞僌斾妑夞楬偺徚旓僄僱儖僊乕偼昡壙偵偼娷傔側偄傕偺偲偡傞丅偙傟偼丄彫婯柾側慻崌傢偣夞楬偵偍偗傞徚旓揹椡偼丄SRAM傾儗僀傾僋僙僗傗僆僼僠僢僾儊儌儕傊偺傾僋僙僗偵昁梫側徚旓揹椡偵斾傋偰旕忢偵彫偝偄偲尵傢傟偰偍傝[7]丄懨摉側壖掕偲巚傢傟傞丅
丂昞2偵昡壙偵偍偗傞儊儌儕峔惉偺壖掕傪帵偡丅僉儍僢僔儏丄偍傛傃SCM偺峔惉偼丄崌寁64KB丄4-way偺僉儍僢僔儏傪丄僉儍僢僔儏丒SCM摑崌婡峔偵傛傝丄梕検斾傪嵞峔惉偟偨応崌傪憐掕偡傞丅傑偨丄僨乕僞傾儗僀偺奺僂僃僀偼丄撪晹偱僒僽傾儗僀偵暘妱偝傟傞偑丄杮峞偺昡壙偱偼CACIT\cite[10]偵傛傝摼傜傟偨嵟揔側暘妱悢傪梡偄傞丅

丂偙偺傛偆側忦審偺傕偲丄僉儍僢僔儏傾乕僉僥僋僠儍乮Cache偲昞婰乯偲SCIMA偺徚旓僄僱儖僊乕偵偮偄偰斾妑昡壙傪峴側偆丅傑偢SCIMA偺僩儔僼傿僢僋偺嶍尭偵傛傞徚旓揹椡嶍尭偺岠壥傪挷傋傞偨傔丄僶僗偺徚旓僄僱儖僊乕偺傒傪昡壙偡傞丅師偵丄僉儍僢僔儏/SCM傾僋僙僗偺徚旓僄僱儖僊乕傕娷傔丄儊儌儕僔僗僥儉慡懱偺徚旓僄僱儖僊乕偵偮偄偰斾妑傪峴偆丅偦偺嵺丄SCIMA偱偼4.2愡偱弎傋偨慖戰揑僂僃僀傾僋僙僗傪峴偭偨応崌偵偮偄偰丄傑偨僉儍僢僔儏偵偍偄偰偼丄MRU傾儖僑儕僘儉偵傛傞僂僃僀梊應[9]傪峴偭偨応崌偵偮偄偰昡壙傪峴偆丅
6.丂昡壙寢壥
6.1丂僶僗偺徚旓僄僱儖僊乕
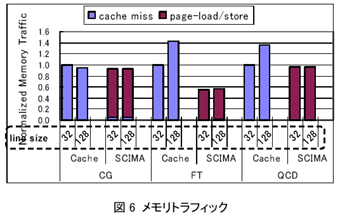
丂傑偢丄SCIMA偵傛傞儊儌儕僩儔僼傿僢僋嶍尭偺岠壥傪尒傞偨傔丄恾6偵Cache偲SCIMA偺儊儌儕僩儔僼傿僢僋傪帵偡丅恾6偼丄奺儀儞僠儅乕僋僾儘僌儔儉偵偍偄偰丄儔僀儞僒僀僘32B偺応崌傪婎弨偲偟偨憡懳揑側儊儌儕僩儔僼傿僢僋偱偁傞丅側偍奺朹僌儔僼偼丄僉儍僢僔儏儈僗偵傛傞僩儔僼傿僢僋乮cache
miss乯偲丄page-load/page-store偵傛傞僩儔僼傿僢僋乮page-load/store乯偺撪栿傕帵偟偰偄傞丅偙偺恾偐傜丄偡傋偰偺僾儘僌儔儉偵偍偄偰SCIMA偼僉儍僢僔儏偵斾傋僆僼僠僢僾儊儌儕儊儌儕僩儔僼傿僢僋偑嶍尭偝傟偰偄傞偙偲偑傢偐傞丅偙傟偼丄SCM傪梡偄傞偙偲偱丄昁梫側僨乕僞偑僐儞僼儕僋僩側偳偵傛傝捛偄弌偝傟傞偙偲側偔丄嵞棙梡惈傪嵟戝尷偵妶梡偱偒偨寢壥偱偁傞丅
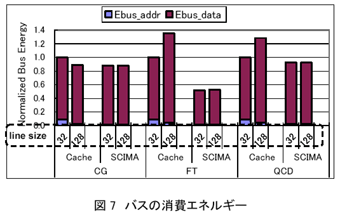
丂師偵丄恾7偵奺僾儘僌儔儉偵偍偗傞僶僗偺憡懳徚旓僄僱儖僊乕傪帵偡丅恾拞丄Ebus_addr偼傾僪儗僗僶僗偺徚旓僄僱儖僊乕傪丄傑偨Ebus_data偼僨乕僞僶僗偺徚旓僄僱儖僊乕傪帵偟偰偄傞丅恾7偐傜丄SCIMA偱偼Cache偵斾傋1%偐傜61%傕偺徚旓僄僱儖僊乕偑尭彮偟偰偄傞偙偲偑傢偐傞丅偙傟偼丄僩儔僼傿僢僋偺嶍尭偵斾椺偟偰丄僨乕僞僶僗乮Ebus\_data乯偺徚旓僄僱儖僊乕偑尭彮偟偰偄傞偨傔偱偁傞丅偝傜偵丄傾僪儗僗僶僗偺徚旓僄僱儖僊乕偑尭彮偟偰偄傞偙偲傕棟桼偺1偮偱偁傞丅
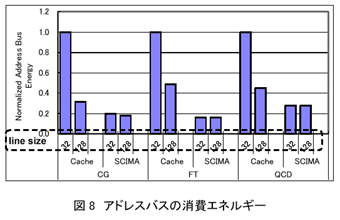
丂傾僪儗僗僶僗偺傒偺徚旓僄僱儖僊乕傪斾妑偟偨傕偺傪恾8偵帵偡丅SCIMA偱偼傾僪儗僗僶僗偺徚旓僄僱儖僊乕傕戝偒偔嶍尭偝傟偰偄傞偑丄偙傟偵偼師偺棟桼偑偁傞丅傑偢丄僩儔僼傿僢僋偑嶍尭偝傟偨偙偲偵傛傝丄偦傕偦傕傾僪儗僗敪峴偺夞悢偑嶍尭偝傟偨偨傔偱偁傞丅傑偨丄SCIMA偱偼戝偒側楢懕椞堟傪堦搙偵揮憲偱偒傞偨傔丄row傾僪儗僗傪1夞敪峴偟偨屻丄column傾僪儗僗偺傒偱楢懕椞堟偺揮憲偑偱偒丄row傾僪儗僗偺敪峴偑梷惂偝傟偨偙偲傕嫇偘傜傟傞丅偝傜偵丄楢懕側column傾僪儗僗偺僔乕働儞僗偑敪峴偝傟偨応崌丄價僢僩偺慗堏夞悢偑彮側偔側傞偙偲傕棟桼偺1偮偱偁傞丅
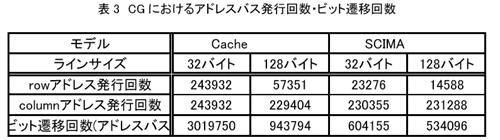
丂昞3偵丄CG偵偍偗傞row傾僪儗僗/column傾僪儗僗偺敪峴夞悢丄偍傛傃傾僪儗僗僶僗偵偍偗傞價僢僩慗堏夞悢傪帵偡丅CG偱偼Cache偲SCIMA偱儊儌儕僩儔僼傿僢僋偵戝偒側堘偄偼側偄偵傕娭傢傜偢丄row傾僪儗僗偺敪峴夞悢偑戝偒偔嶍尭偝傟偰偍傝丄傑偨價僢僩慗堏夞悢傕Cache偺敿暘掱搙偲側偭偰偄傞丅
丂埲忋偺偙偲偐傜丄SCIMA偱偼僩儔僼傿僢僋嶍尭偵傛傝丄幚嵺偵僨乕僞僶僗丄傾僪儗僗僶僗嫟偵徚旓僄僱儖僊乕傪嶍尭偡傞偙偲偑偱偒傞偲尵偊傞丅
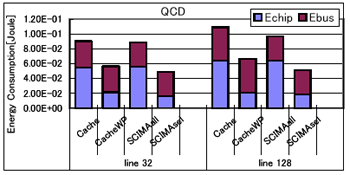
恾9丂儊儌儕僔僗僥儉慡懱偺徚旓僄僱儖僊乕
6.2丂儊儌儕僔僗僥儉慡懱偺徚旓僄僱儖僊乕
丂杮愡偱偼丄僶僗偺徚旓僄僱儖僊乕偵壛偊丄僉儍僢僔儏/SCM傾僋僙僗偺嵺偺徚旓僄僱儖僊乕傪昡壙偟丄儊儌儕僔僗僥儉慡懱偺徚旓僄僱儖僊乕偵偮偄偰専摙偡傞丅
丂恾9偵丄奺儀儞僠儅乕僋僾儘僌儔儉偵偍偗傞丄僉儍僢僔儏/SCM傾僋僙僗偵偍偗傞徚旓僄僱儖僊乕乮Echip乯偲丄僶僗偵偍偗傞徚旓僄僱儖僊乕乮Ebus乯偺崌寁傪帵偡丅Cache儌僨儖偵偍偄偰丄Cache偲CacheWP偼偦傟偧傟僂僃僀梊應傪峴側傢側偐偭偨応崌偲峴側偭偨応崌傪昞偟偰偄傞丅傑偨丄SCIMAall,
SCIMAsel偼丄SCIMA儌僨儖偵偍偄偰SCM傾僋僙僗帪偵傕慡僂僃僀傪暲楍偵傾僋僙僗偟偨応崌偲丄慖戰揑偵僂僃僀傪傾僋僙僗偟偨応崌偺堘偄偱偁傞丅SCIMA偱偼丄傾僪儗僗偐傜傾僋僙僗偡傋偒僂僃僀傪堦堄偵寛掕偱偒傞偨傔丄忢偵慖戰揑僂僃僀傾僋僙僗偑壜擻偱偁傞偑丄斾妑偺偨傔偵SCIMAall傕昡壙偟偨丅
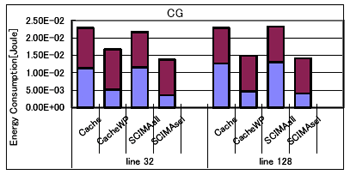
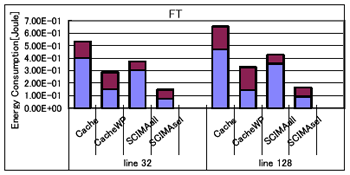
丂傑偨丄昞4偵丄32B偺僉儍僢僔儏儔僀儞偵偍偗傞椉儌僨儖偺僉儍僢僔儏/SCM傾僋僙僗夞悢傪帵偡丅昞4偵偼丄CacheWP儌僨儖偱偺僂僃僀梊應偺嵺偺僸僢僩棪乮WP僸僢僩棪乯偲丄SCIMA儌僨儖偺僉儍僢僔儏/SCM傾僋僙僗夞悢拞偵SCM傾僋僙僗偑愯傔傞妱崌乮SCM傾僋僙僗偺妱崌乯傕帵偟偰偄傞丅

丂傑偢丄慖戰揑僂僃僀傾僋僙僗傪峴側傢側偄Cache偲SCIMAall傪斾妑偡傞丅FT傪彍偒丄僉儍僢僔儏/SCM傾僋僙僗夞悢偼傎偲傫偳曄傢傜側偄偨傔乮昞4嶲徠乯丄僠僢僾撪偺徚旓僄僱儖僊乕乮Echip乯偵嵎偼側偄丅偟偐偟丄SCIMA偱偼僶僗偺徚旓僄僱儖僊乕偑嶍尭偝傟偰偄傞偨傔丄崌寁偺徚旓僄僱儖僊乕偼SCIMA偺曽偑彮側偔側偭偰偄傞丅側偍丄FT偵偍偄偰僠僢僾撪偺徚旓僄僱儖僊乕偑SCIMA偱彮側偄偺偼丄Cache儌僨儖偺応崌偵僐儞僼儕僋僩儈僗昿敪偵傛傞惈擻掅壓傪杊偖栚揑偱丄寁嶼椞堟傪堦帪揑側scratch攝楍偵僐僺乕偡傞偨傔丄僉儍僢僔儏傾僋僙僗夞悢偑SCIMA傛傝傕懡偔側傞偨傔偱偁傞丅
丂師偵丄慡僂僃僀傪暲楍偵傾僋僙僗偣偢偵丄僨乕僞偺懚嵼偡傞僂僃僀傪偺傒慖戰揑偵傾僋僙僗偡傞偙偲偱丄僉儍僢僔儏/SCM傾僋僙僗帪偺徚旓僄僱儖僊乕傪嶍尭偟偨CacheWP偲SCIMAsel偵偮偄偰斾妑偡傞丅
丂CacheWP偱偼丄僂僃僀梊應偑惉岟偟偨応崌丄崱夞壖掕偟偨楢憐搙4偺僉儍僢僔儏偱偼僞僌傾儗僀傾僋僙僗偺徚旓僄僱儖僊乕偼曄傢傜側偄傕偺偺丄僨乕僞傾儗僀傾僋僙僗偺徚旓僄僱儖僊乕偑4暘偺1偵側傞丅崱夞昡壙偟偨儀儞僠儅乕僋僾儘僌儔儉偱偼丄僂僃僀梊應偺僸僢僩棪偑崅偄偨傔乮昞4嶲徠乯丄僠僢僾撪偺徚旓僄僱儖僊乕偑60%乣72%傎偳傕嶍尭偝傟偰偄傞丅
丂傑偨丄SCIMAsel偱偼丄SCM傾僋僙僗偺応崌偵僨乕僞傾儗僀傾僋僙僗偺徚旓僄僱儖僊乕偑栺4暘偺1偵側傞偑丄偦偺懠偵僞僌傾儗僀傾僋僙僗偺徚旓僄僱儖僊乕傕嶍尭偱偒傞丅昞4傛傝丄SCIMA偱偼儘乕僪/僗僩傾柦椷偺戝晹暘偑SCM傊偺傾僋僙僗偱偁傞偨傔丄僠僢僾撪偺徚旓僄僱儖僊乕嶍尭棪偼75%乣77%偲CacheWP偺応崌偵斾傋丄傛傝崅偔側偭偰偄傞丅
丂崌寁偺徚旓僄僱儖僊乕偵偮偄偰斾妑偡傞偲丄SCIMAsel偱偼僠僢僾撪晹丄偍傛傃僶僗偺徚旓僄僱儖僊乕偺椉曽偑CacheWP偵斾傋嶍尭偝傟傞偨傔丄椉儌僨儖娫偺徚旓僄僱儖僊乕偺嵎偼偝傜偵戝偒偔側傞丅椺偊偽FT偱偼丄栺50%傕偺徚旓僄僱儖僊乕偑丄傑偨嵟傕掅偄CG偺128B儔僀儞僒僀僘偺応崌偱偝偊5%偺徚旓僄僱儖僊乕偑CacheWP偵斾傋嶍尭偝傟偰偄傞丅廬偭偰丄SCIMA偼儊儌儕僔僗僥儉慡懱偲偟偰尒偨応崌丄僉儍僢僔儏傾乕僉僥僋僠儍偵斾傋掅徚旓僄僱儖僊乕壔傪払惉偱偒傞傾乕僉僥僋僠儍偱偁傞偲寢榑晅偗傞偙偲偑偱偒傞丅
6.3丂惈擻偲徚旓僄僱儖僊乕偺娭學
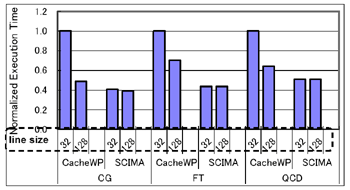
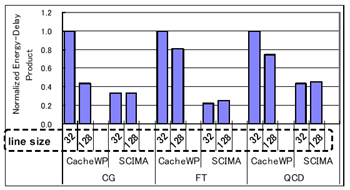
丂師偵丄僋儘僢僋儗儀儖偺惈擻昡壙傪梡偄偨Cache儌僨儖偲SCIMA儌僨儖偺惈擻昡壙寢壥傪恾10偵帵偡丅偙偺恾偐傜傢偐傞傛偆偵丄SCIMA偼僉儍僢僔儏傾乕僉僥僋僠儍偵斾傋崅惈擻偑払惉偱偒傞丅廬偭偰丄SCIMA偼SCM傪梡偄傞偙偲偱丄崅惈擻偐偮掅徚旓揹椡傪幚尰偱偒傞傾乕僉僥僋僠儍偱偁傞丅偙偺惈擻偲徚旓僄僱儖僊乕偺娭學偵偮偄偰媍榑偡傞偨傔丄恾11偵Cache儌僨儖偲SCIMA儌僨儖偺ED愊乮Energy-Delay
Product乯傪帵偡丅椉儌僨儖偲傕丄徚旓僄僱儖僊乕偼慖戰揑僂僃僀傾僋僙僗傪峴側偭偨応崌傪憐掕偟偰偄傞丅
丂恾11傛傝丄SCIMA偼Cache偵斾傋ED愊傪戝偒偔夵慞偱偒傞偙偲偑傢偐傞丅偙偺寢壥偐傜丄惈擻偲徚旓僄僱儖僊乕偺椉曽傪峫偊偨応崌丄僉儍僢僔儏傾乕僉僥僋僠儍偵懳偡傞SCIMA偺桪埵惈偼偝傜偵憹偡偲峫偊傜傟傞丅
恾10丂惈擻昡壙寢壥乮COLPFig12乯
恾11丂ED愊 乮fig9, SWoPP02乯
7.丂傑偲傔偲崱屻偺壽戣
丂杮峞偱偼丄僜僼僩僂僃傾惂屼偺僆儞僠僢僾儊儌儕傪梡偄傞SCIMA偺傾乕僉僥僋僠儍偺奣梫丄僆儞僠僢僾儊儌儕傪梡偄偨惈擻岦忋庤朄丄側傜傃偵丄僆儞僠僢僾儊儌儕棙梡偵傛傞掅徚旓揹椡壔偵偮偄偰昡壙傪峴側偭偨丅傑偨丄僉儍僢僔儏/SCM傾僋僙僗偵偍偗傞徚旓揹椡傪娷傔偰昡壙偟丄儊儌儕僔僗僥儉慡懱偺掅徚旓揹椡壔偺岠壥偵偮偄偰傕専摙偟偨丅
丂昡壙寢壥傛傝丄SCIMA偱偼僩儔僼傿僢僋嶍尭偵傛傝丄僉儍僢僔儏偵斾傋幚嵺偵僨乕僞僶僗丄傾僪儗僗僶僗偺徚旓僄僱儖僊乕傪嶍尭偱偒傞偙偲偑傢偐偭偨丅傑偨丄SCIMA偱偼僉儍僢僔儏/SCM傾僋僙僗偵旓傗偝傟傞徚旓僄僱儖僊乕傕戝偒偔嶍尭偱偒傞偙偲偐傜丄儊儌儕僔僗僥儉慡懱偲偟偰尒偨応崌丄僉儍僢僔儏傾乕僉僥僋僠儍偵斾傋戝暆側徚旓僄僱儖僊乕嶍尭岠壥偑摼傜傟傞偙偲偑傢偐偭偨丅崱屻偼丄偝傜偵徻嵶側儌僨儖偱昡壙傪峴側偆梊掕偱偁傞丅
嶲峫暥專
[1] 拞懞 岹丄嬤摗 惓復丄戝壨尨 塸婌丄杙 懽桽, 乬僴僀僷僼僅乕儅儞僗僐儞僺儏乕僥僥傿儞僌岦偗傾乕僉僥僋僠儍SCIMA乭丄忣曬張棟妛夛榑暥帍丄Vol. 41丄No. SIG 5乮HPS 1乯丄 pp.15-27,2000擭8寧
[2] 嬤摗 惓復丄拞懞 岹丄杙 懽桽, 乬SCIMA偵偍偗傞惈擻嵟揔壔庤朄偺専摙乭丄 忣曬張棟妛夛榑暥帍丄 Vol. 42丄 No. SIG 12乮HPS 4乯丄 pp.37-48丄 2001擭11寧
[3] 嬤摗 惓復丄 戝崻揷 戱丄 揷拞 怲堦丄 拞懞 岹丄 乬僜僼僩僂僃傾壜惂屼僆儞僠僢僾儊儌儕傪梡偄偨掅徚旓揹椡壔偺専摙乭丄 暲楍張棟僔儞億僕僂儉 JSPP2002丄 pp.285-288丄2002擭5寧
[4] M.Lam, E.Rothberg and M.Wolf, 乬The cache performance and optimizations of Blocked Algorithms乭, Proc. ASPLOS-IV, pp.63-74, 1991
[5] PC SDRAM Specification丄 Revision 1.7, Intel Corporation, Nov. 1999
[6] S.Aoki, et al. 乬Performance of lattice QCD programs on CP-PACS乭, Parallel Computing 25丄 pp.1243-1255, 1999丅
[7] M.B.Kamble, and K.Ghose, 乬Analytical Energy Dissipation Models For Low Power Caches乭, Proc. of 1998 Internatilnal Symposium on Low Power Electronics and Design, pp.143-148, Aug. 1998
[8] M.B.Kamble, and K.Ghose, 乬Energy-Efficiency of VLSI Caches: A comparative Study乭, Proc. of the IEEE 10th Int'l. Conf. on VLSI Design, pp.261-267, Jan. 1997
[9] K.Inoue, T.Ishihara, and K. Murakami, 乬Way-Predicting Set-Associative Cache for High Performance and Low Energy Consumption乭, Proc. of the Int'l. Symp. on Low Power Electronics and Design, pp. 273-275, Aug. 1999.
[10] S. Wilton and N. Jouppi, 乬CACTI: An Enhanced Access and Cycle Time Model for On-Chip Caches乭, WRL Research Report 93/5, July 1994.
丂