第3章 ハイエンドコンピューティング研究開発の動向
中村 宏 講師
1. はじめに
近年、計算機システムの消費電力、あるいは消費エネルギー削減の要求が高まっている。例えば、モバイル計算機におけるバッテリ駆動時間延長の要求はもちろんのこと、ハイパフォーマンスコンピューティング(HPC)分野においても、大規模な並列計算機を構成する上で、放熱や設置面積などの面から消費電力を可能な限り小さく抑えることが重要となっている。今後、消費電力が全体の性能を制限する要素の1つになると考えるため、低消費電力化・低消費エネルギー化は今日の計算機システムにとって非常に重要な課題である。
著者らはこれまで、HPC分野やメディア系のアプリケーションなどをターゲットとしたプロセッサアーキテクチャSCIMA(Software Controlled Integrated Memory Architecture)を提案してきた[1]。SCIMAはチップ上に実装するメモリとして、従来のキャッシュに加えてアドレス指定可能な主記憶の一部(以降では、そのメモリをSCM(Software Controlled Memoryと呼ぶ)をSRAMとして搭載するアーキテクチャである。さらに、キャッシュとSCMでハードウェアを共有し、アプリケーションの性質に応じてそれらの容量比を動的に変更可変な実装(キャッシュ・SCM統合機構と呼ぶ)についても提案している。
SCMは、ISA(命令セットアーキテクチャ)上に定義された命令により主記憶との間でデータ転送が行われる。従って、ユーザ(コンパイラ)による明示的なデータのアロケーション、およびリプレースメントが可能となる。キャッシュではこれらの制御がハードウェアによって決められたアルゴリズムで自動的に行われるため、個々のプログラムにとって最適なデータアロケーション、リプレースメントを行わせることは難しい。そのため、コンフリクトミスによりプロセッサと主記憶間のデータ転送(メモリトラフィック)が増加し、性能が大きく低下することがある。一方、SCIMAではソフトウェア制御のSCMを用いることで、メモリトラフィックを最小限に抑えることが可能となる。この特徴により、SCIMAでは高性能を達成できることがわかっている[1][2]。一方、消費電力の面においても、オフチップメモリトラフィックの削減は効果が大きいと考えられる。負荷容量の高い外部のメモリバスやI/Oパッドを駆動するために、多くの電力が消費されるからである。SCIMAではまた、ロード/ストア命令、すなわちレジスタ・SCM間データ転送のためのSCMアクセスの際にも、従来のキャッシュアクセスに比べ消費電力を削減できる[3]。従来の連想キャッシュでは、アクセスすべきデータは高々1つのウェイにしか存在しないにも関わらず、キャッシュアクセス時間の増加を防ぐために、タグの検索と同時に全てのウェイを並列にアクセスする。このため、該当するデータが存在しないウェイでは無駄に電力が消費されている。しかし、SCMでは、キャッシュとは異なりアクセスすべき位置がアドレスから一意に決定されるため、アクセスすべきデータが存在するウェイのみを選択的にアクセスすることができる。
本稿では、ソフトウェア制御のオンチップメモリを用いるSCIMAのアーキテクチャの概要、オンチップメモリを用いた性能向上手法を述べ、その後で、オフチップメモリトラフィック削減による低消費電力化に加え、選択的ウェイアクセスによる低消費電力化についても評価を行ない、NAS Parallel Benchmarks、および計算物理学の実アプリケーションを用いて、従来のメモリ階層を持つプロセッサに対する、性能と消費電力面でのSCIMAの優位性を評価・報告する。
2. SCIMA
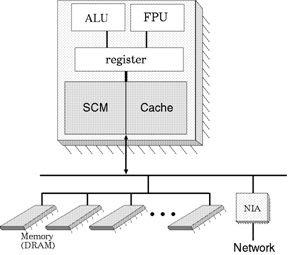
SCIMAの構成を図1に示す。SCIMAはプロセッサ上にキャッシュだけでなく、アドレス指定可能なSCM (Software Controlled Memory)を搭載する。従来のキャッシュでは、データのアロケーションやリプレースメントがハードウェアで暗黙的に制御されるのに対し、SCMはそれらの制御をソフトウェアで明示的に行う。
図1 SCIMAの構成図
SCIMA では論理アドレス空間上にSCM領域をマッピングする。SCM領域は1つの大きな連続領域であるため、この管理をTLBではなく専用レジスタで行い、TLB ミスの頻発を防ぐ。導入するレジスタは、SCM領域の先頭アドレスを保持するASR (On-Chip Address Start Register)とオンチップメモリの容量を表すAMR (On-Chip Address Mask Register)である。
SCMへのデータ転送を制御するため、page-load/page-storeと呼ぶ主記憶・SCM間のデータ転送命令を追加する。本命令によるデータ転送は大きな粒度で行ない、オフチップメモリレーテンシの影響を抑えることを狙う。また、この命令にはブロックストライド転送の機能を付け加える。この機能によりオフチップメモリ上の不連続領域のデータをパッキングしてオンチップメモリに持ってくることが可能となり、プロセッサ・主記憶間のバンド幅の有効利用につながる。また、これらのデータを再利用する場合、オンチップメモリ上では連続するデータとなるため処理効率が向上する。HPCアプリケーションでは多次元配列要素に対するアクセスなどが多いために有用な機能であると考えられる。
レジスタ・SCM間のデータ転送は従来のload/store命令により行う。前節で述べたアドレスマッピング機構により、load/storeの対象アドレスがSCM領域か否かを判定し、SCM領域であればSCMへのアクセスを、そうでない場合は通常のキャッシュアクセスを行なう。
キャッシュとSCMに割り振られる容量をアプリケーションの性質に応じて変えるべく、総容量一定のもとSCMとキャッシュの容量比を実行時に再構成できる機構を提案している[2]。具体的には、n-way連想キャッシュの連続する一部のwayをSCMに割り当てる。
3. ソフトウェア可制御メモリを用いた性能最適化
本章ではまず、SCIMAの性能向上要因について整理する。また、それに基づきSCIMAの性能を最適にするためにユーザ、あるいはコンパイラがSCMをどのように用いるべきかの指針を整理・検討する。
3.1 SCIMAの性能向上要因の分析
プロセッサと主記憶の性能格差により、プロセッサは実行時間の多くを本来の計算処理にではなく主記憶からのデータ待ち、すなわち無駄なストール時間として費やしている。この実行時間を解析するために、本論文ではプロセッサの実行時間をCPU-busy time (Tb)、latency-stall (Tl)、throughput-stall (Tt)の3つに分類する。CPU-busy timeとはプロセッサが実際に計算処理を行っている時間であり、latency-stallは主記憶のアクセスレーテンシがもたらすストール時間を、またthroughput-stallはオフチップメモリのスループット不足に起因するストール時間を指す。
ここで、プロセッサの総実行時間をT、オフチップメモリスループットが無限大と仮定した場合の実行時間をT∞、オフチップメモリスループットが無限大かつオフチップメモリレーテンシが0であると仮定した場合の実行時間をTpとする。このT、T∞、Tpを用い、Tb、Tl、Ttを以下のようにここでは定義する。
表1は、SCIMAのソフトウェア可制御メモリ(SCM)の特徴が上記で分類した実行時間のそれぞれに対しどのように影響するのかを示したものである。また、キャッシュアーキテクチャにおける代表的なレーテンシ隠蔽技術についても同様に示している。表中の「p-load/p-store (大粒度転送)」、及び「p-load/p-store (ストライド転送)」はそれぞれ2章で述べたpage-load/page-store命令の大粒度転送、及びストライド転送の機能を表す。
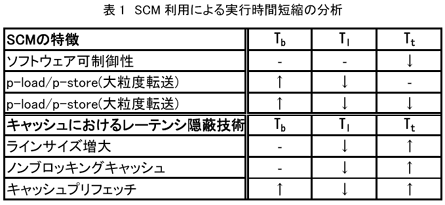
まず、ソフトウェア制御が可能なため、データの再利用性を最大限に活用することで、オフチップメモリトラフィックを最小限に抑えられる。これは、throughput-stallの短縮につながる。また、page-load/page-store命令の大粒度転送により、メモリアクセス回数を削減することで、latency-stallを短縮することができる。さらに、ストライド転送機能は、無駄なトラフィック及びアクセス回数を削減でき、latency-stall、throughput-stallの短縮に有効である。
キャッシュにおけるレーテンシ隠蔽技術は、latency-stallを短縮させることができるが、throughput-stallを増大させてしまう。これは、プロセッサ・主記憶間のデータトラフィックを増大させてしまうためであり、これらレーテンシ隠蔽技術がプロセッサの総実行時間短縮に常に有効であるとは限らないことを示している。
一方、SCMを用いることでlatency-stall及びthroughput-stallの両者の短縮が可能となる。今後オフチップメモリのレーテンシ増大とスループット不足がより深刻化すると思われるが、将来的にSCIMAの有効性はさらに増すと考えられる。
3.2 最適化の指針
オンチップメモリを利用するためには、オンチップメモリ経由でアクセスするデータの選択とデータ転送のタイミングを指定しなければならない。後者についてはユーザによる最適化も可能であるが、コンパイラによるスケジューリング支援は既存技術の延長として、現在でも十分可能であると考えられる。一方、アクセスするデータの選択は性能最適化のためには特に重要となるが、これまでその指針は整理されていない。そのため、本節では主に「オンチップメモリ経由でアクセスするデータの選択」について検討を行う。
オンチップメモリ経由でアクセスするデータを決定する場合、再利用性やデータアクセスの特徴に関して同じ配列内のデータは同じ性質を持つことが多いため、配列を単位として考えるのが妥当である。そこで、プログラム中での配列について再利用性とアクセスの連続性の観点からその特徴を分類する。そして、横軸に再利用性を、縦軸に連続性をとった場合に、SCMを利用する戦略をまとめたものを図2に示す。ここで各配列の再利用性は、``対象とする配列のある要素が参照されてから再び参照される間にアクセスされる、自身の配列内の他のデータの総数(容量)''を用いて定義する。ブロッキングなどを行なうことで、この値がオンチップメモリサイズ以下になるならば、その配列は再利用性があると判断し、そうでなければ再利用性なしと判断する。図2を以下に詳述する。
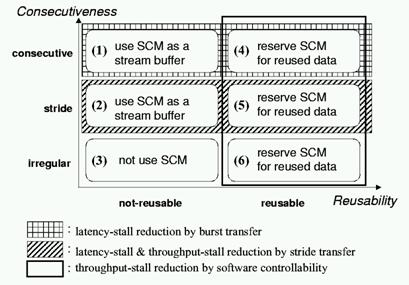
図2 配列の特徴に対するオンチップメモリの利用法
(1) 再利用性はないが連続アクセスされる配列: page-load/page-store命令により、転送回数を減らしlatency-stallの短縮を図る。オンチップメモリ上にpageサイズ分のバッファ領域を確保し、この領域をストリームバッファとして用いながらアクセスする。これは、page-load/page-store命令の転送サイズの上限が pageサイズであるためである。なお、更なる最適化として、pageサイズのストリームバッファを2つ確保し、交互にそのバッファ領域に転送しながら演算を行なうことで、演算と転送とをオーバーラップさせることも効果的である。
(2) 再利用性はないがストライドアクセスされる配列: page-load/page-storeのストライド転送の機能により、無駄なデータ転送を防ぎ効率的なデータ転送を行う。(1)と同様にオンチップメモリ上にpageサイズ分のバッファ領域を確保し、この領域をストリームバッファとして用いる。
(3) 再利用性がなくアクセスが不規則な配列: このような配列はSCIMAのオンチップメモリを用いても性能向上は見込めない。そのため、SCMは利用しない。
(4) 再利用性があり連続アクセスされる配列: ブロッキング手法を用いるなど、オンチップメモリサイズに分割してアクセスすることで他のデータとの干渉を防ぎながら再利用性を最大限に活用する。また、page-load/page-store命令によるlatency-stall短縮の効果も期待される。オンチップメモリ上に、ループ中でアクセスされるワーキングセット分のオンチップメモリ領域を割り当てる。
(5) 再利用性がありストライドアクセスされる配列: page-load/page-storeのストライド転送機能により、不連続なデータをパッキングしてオンチップメモリに載せ、チップ内記憶領域の有効利用を図ると同時に、他のデータとの干渉を防ぎながら再利用性を最大限に活用する。(4)と同様に、オンチップメモリ上にループ中でアクセスされるワーキングセット分のオンチップメモリ領域を割り当てる。
(6) 再利用性はあるがアクセスが不規則な配列: アクセスされる範囲が予めわかり、かつその範囲がオンチップメモリに載る程度の大きさであれば、オンチップメモリ上に固定してデータを載せ再利用性を活用する。
(1)〜(6)は独立な最適化であるが、まず(1)、(2)が重要である。なぜなら、再利用性がないデータに対してはキャッシュは無力であるため、まずストリームバッファを提供してlatency-stallを短縮することは効果が大きいためである。これは、HPC分野においてベクトル計算機のベクトルロード・ストア機構が非常に有効であることからも裏付けられる。その次に、キャッシュでもある程度は効果的に扱える再利用性のあるデータに対し(4)〜(6)を行い、さらなる最適化を行うのが妥当であると思われる。以上の戦略に従い、オンチップメモリを用いる最適化を行なう際に、最適化の対象となる配列をオンチップメモリへ割り当てる際は、まず図2の(1)(2)の特徴を持つ配列に対し、最適化戦略(1)、(2)に従いpageサイズ分の領域を割り当てる。次に、図2の(4)(5)(6)の特徴を持つ配列に対し、残りのオンチップメモリ領域にそれらの配列のすべてのワーキングセットが収まるようにブロックサイズを縮小し、収まりきるブロックサイズになった段階で、各配列のワーキングセット分の領域をオンチップメモリに割り当てる。