第3章 ハイエンドコンピューティング研究開発の動向
福井 義成 委員
1. はじめに
計算機の歴史、アプリケーションの開発・保守、高速化などの立場から見た現在の計算機への素朴な疑問について述べる。計算機が開発されて以来、計算機の歴史は高速化の歴史でもあった。計算機を高速化する手段はいくつか考えられる。思いつくまま挙げてみると以下のようなものがある。
(1) 素子の高速化
(2) メモリの大容量化
(3) キャッシュメモリ(データ、命令)
(4) 命令バッファの使用
(5) メモリのインタリーブ
(6) ループを効果的に行う命令を用意する
(7) ベクトル命令
(8) パイプライン化
(9) (並列処理)
この中で、すべての問題(プログラム)に満遍なく効果があるのは(1)素子の高速化だけである。その他の項目は、何らかの「仮定」を満足した場合のみに高速化の効果があるものばかりである。その様子を以下に述べる。
(1) 素子の高速化
すべての問題に効果がある。(2) メモリの大容量化
メモリが大きいと速く計算できる場合がある。メモリ不足で外部記憶を使用していたのを、すべてメモリ上で処理できる場合等。不必要に大きくしても効果はない。(3) キャッシュメモリ
メモリ参照が局所的であれば効果がある。メモリ参照が局所的でないプログラムには効果が少ない。
(4) 命令バッファの使用(命令キャッシュ)
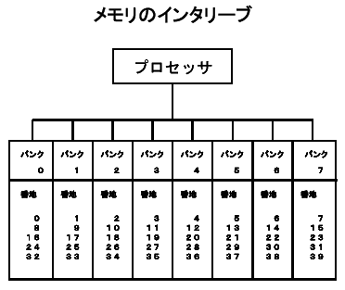
ループが命令バッファ内に入りきると命令のためのメモリへの参照が減り、高速化が可能になる。長いループや分岐が多いとダメ。(5) メモリのインタリーブ
メモリ参照を分散すると高速にデータを扱える。同じメモリバンクを連続的に使用すると効果がない。
(6) ループを効果的に行う命令を用意する
ループを速く実行できる。その命令にあてはまらないと効果がない。(7) ベクトル命令
ループを効果的に行う命令を発展させたものであり、ベクトル化できると10倍以上速くなる。
ベクトル化できないと効果がない。
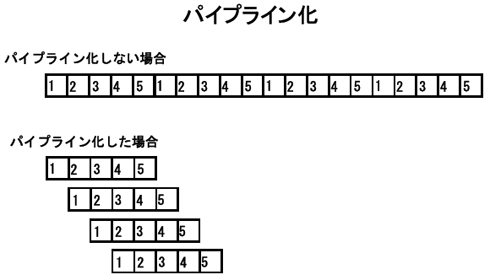
(8) パイプライン化
1つの演算を複数に分けて処理し、時間的な並列性を上げることにより、
高速化できるが、同じ種類の演算がなければ効果がない。
以上のように、(1)以外の項目は、各々の「仮定」を満足しなければ、高速化の効果が得られない。逆に言えば、(2)〜(8)については、問題(プログラム)の性質により、高速化の効果が異なると言える。(9)については別の機会に考える。
2. キャッシュについての疑問
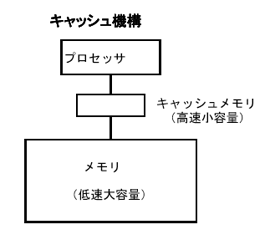
キャッシュ機構は、IBM360/81から商用機に採用されたと思われる。現在ではキャッシュ機構はプロセッサとメモリの間の速度差を埋める(隠蔽する)手法と考えられている。しかし、プロセッサとメモリの間の速度差を隠蔽する手法は、キャッシュ機構だけではない。ベクトル機構もプロセッサとメモリの間の速度差を隠蔽する手段である。スカラープロセッサでも、キャッシュ機構ではなく、大量のレジスタを準備する方法等も考えられる。その場合の問題点はレジスタを指定するための、ビット数と大量のレジスタを効率良く利用する為のコンパイラ技術であろう。
筆者の目にはキャッシュ機構は、ハードウェアの余裕が出来たが、アーキテクチャを変更出来なくなった状況での妥協策と映る。アーキテクチャが変更できる状況で命令セットを変更し、レジスタ数を増加させる方向も可能だからである。レジスタ数を増加させる方向をとった場合、問題となるのは、ビット数と大量のレジスタを効率良く利用する為のコンパイラ技術である。コンパイラの最適化能力不足により、せっかくの多数のレジスタのアロケーションができないことも起きる可能性がある。しかし、まったく自動的にコンパイラが、レジスタのアロケーションを行うのではなく、何らかの指示をユーザが行うことで、レジスタを効果的に使うことができない状況を回避することも可能である。
キャッシュ機構は、高速のプロセッサと低速のメモリの間にユーザがコントロールできない高速のメモリを配置し、頻繁に使用するデータを高速のメモリに置いて、高速処理を図ろうとする方法である。使用するデータがキャッシュ容量を越えた場合、最も使われていないデータを削除し、その後に新たなデータを移動することが行われている。このアルゴリズムは一見良さそうであるが、最も使われていないデータ(最も過去に使用されたデータ)は、削除された直後に使われることもある。行列形式のデータを左上から右下に演算をしていく場合を考えると、右下まで演算が終了した後は、また左上の要素を演算するのが自然である。この場合、「最も使われていないデータ(最も過去に使用されたデータ)」を削除し、新たなデータを移動する方式は、常にデータの移動を発生させる恐れがある。常にデータの移動ばかりを行って、キャッシュ機構のメリットがなくなる。これを防ぐには、キャッシュ機構の動作を考慮したプログラムが必要になり、これは本末転倒である。この原因はキャッシュ機構が「投機的」な方式であることに由来する。ユーザのデータの使い方とキャッシュ機構の前提としているデータの使用方法が一致している場合はキャッシュ機構が有効に働くが、一致しない場合は有効に働かないどころか、キャッシュ機構が無い場合以上に遅くなることさえある。
ユーザの多くは自分の計算におけるデータの動きを理解しており、それに従ったプログラムを作成する。キャッシュ機構がある場合は、さらにキャッシュ機構の動きを意識したプログラムを作成する必要がある。「キャッシュ機構の動き」が常に同じものであればまだしも、キャッシュサイズやキャッシュ機構のアルゴリズムが代わると「自分の解きたい問題は変わらない」にも関わらず、プログラムの修正を行わないと高速な計算ができないことになる。ユーザの立場からは、自分の意志で計算機をコントロールしたいのに、キャッシュ機構に阻まれて自由にならないこともある。キャッシュ機構は、リソースに余裕ができたが、アーキテクチャを変更できない場合の妥協策である。動きが投機的で、プログラマの自由にならない。その結果、チューニングの効果がキャッシュサイズに依存し、その効果が計算モデルに依存する。

3. メモリの遅さの隠蔽方法
現在の計算機においては、プロセッサの速度とメモリの速度に大きな差があり、その差が毎年広がりつつある。プロセッサとメモリの速度差が大きい環境で、如何に効率良く計算を行うかを考える。
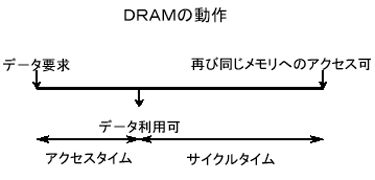
プロセッサとメモリの速度差を隠蔽する手法の1つはキャッシュ機構であるが、キャッシュ機構は、キャッシュ機構のアルゴリズムと計算におけるデータの動きが異なった場合、ユーザに不要な努力を強いることになる。ユーザが自覚しているデータの動きを、素直に反映させることが困難な場合がある。自分でデータの動きを理解しているユーザにとって、計算機が自分の思うように動いてくれないことは歯がゆいことである。科学・技術計算の場合、データの動きは比較的単純である。特に、偏微分方程式を解く場合、多数のメッシュに分割し、計算を行うので、決まった形の繰り返し演算になり、他の分野よりデータの動きが予見しやすい。
ベクトル計算機も、プロセッサとメモリの速度差を隠蔽する手法の1つである。ベクトル計算機では、以下の効果が得られる。
(1)ベクトルレジスタを利用したメモリの遅さの隠蔽
(2)1組の命令で多数の演算をすることによる命令処理の低減
−インストラクション・バッファの負荷低減
一般的には、キャッシュメモリとベクトルレジスタは異なる性質のものと考えられている。はたして、キャッシュメモリとベクトルレジスタは異なる役割のものであろうか?見方を変えるとキャッシュメモリとベクトルレジスタは同じ目的のためのものである。現在の計算機では、プロセッサの速度とメモリの速度に大きな差がある。キャッシュメモリとベクトルレジスタは、このプロセッサとメモリの速度差を隠蔽するという点でまったく同じ役割を果たしている。
キャッシュメモリは、メインメモリとの間でアドレスが連続なメモリを決まったサイズ(キャッシュライン:32バイトなど)で転送する。データの転送アルゴリズムはハードウェアで決まっており、プログラマが直接関与することはできない。ベクトルレジスタは、メモリからプロセッサへまとまったデータをブロック転送する点は同じである。ベクトルレジスタは、キャッシュと同じように、アドレスが連続なメモリを転送することもできる。違いは決まったサイズではなく、転送サイズを変更できる点にある。また、リストベクトル(英語ではscatter/gather)を使用すれば、連続アドレスのメモリでなくとも転送可能な点も異なる。また、データ転送をプログラマの意志で行うことができる。

このように見るとキャッシュメモリはベクトルレジスタのサブセットになっている。
キャッシュメモリの利用は投機的実行と呼ばれることがある。キャッシュメモリはメモリを連続するブロック(キャッシュライン)に分け、メモリとの間でブロック単位で転送される。キャッシュへ転送されたメモリは必ずしもすべて使われるとは限らない。全て使われる場合もあれば、最悪の場合、ブロックの中の1記憶単位(4バイトや8バイトなど)しか使われないこともある。そのため、投機的実行と呼ばれる。キャッシュメモリはプロセッサとメモリの速度差を隠蔽するための手法であるが、使われるデータがプログラム(主としてループ)を実行する前に確実に分かっていれば、事前にデータをメモリから転送する作業を行っておき、プロセッサでデータが必要になった時にレジスタ等に準備されていれば、プロセッサとメモリの速度差を隠蔽することができる。最近のプロセッサでは事前にデータをレジスタに転送する命令(プリフェッチ命令)を持っているものもある。プリフェッチ命令はデータが確実に使われることが分かっていてデータをあらかじめレジスタへもってきておく命令であるため、投資的実行と呼ばれる。解釈を広くすれば、ベクトルレジスタへのデータのロード命令も同じであると考えられる。
このように、プロセッサとメモリの速度差を隠蔽する方式は、キャッシュ機構だけではない。ベクトル方式もプロセッサとメモリの速度差を隠蔽する手段であり、他にも色々考えることは可能である。たとえば、ベクトル方式でなくても、高速な記憶装置(レジスタ等)をプロセッサの近くに大量に配置することによっても、プロセッサとメモリの速度差を隠蔽することは可能になる。
4. プロセッサの動向からキャッシュメモリの今後を推定
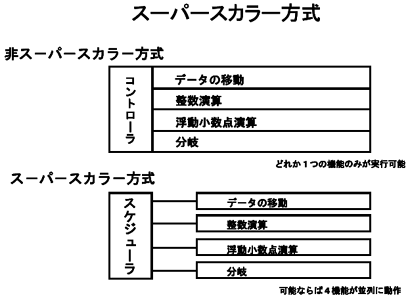
並列化以外の最近のプロセッサの動向を考えると、スカラープロセッサでは、
等が行われてきた。この流れを見ると、スーパースカラーまでは、プロセッサ内の演算順序の変更、並列化等はすべてハードウェアが行ってきた。しかし、VLIWからは、ハードウェアが行ってきた並列動作の制御等を、コンパイラを中心としたソフトウェアに依存する方向になってきたと考えることができる。この延長線上には、ソフトウェアコントロールのキャッシュ機構が来ると考えることもできる。ベクトル機構も、見方を変えるとソフトウェアコントロールのキャッシュと考えることができる。
5. 温故知新
最近、マルチスレッドをサポートするプロセッサが出現している。良く知られているのは、インテルプロセッサのハイパースレッドであろう。10数年前には、バートン・スミスのMTAが出現している。ハイパースレッドやMTAは、CDC6600のppを思い出させる。ppは1つの周辺処理装置を時分割で10個の周辺処理装置として見せるようになっていた。速度の遅さを複数の「スレッド」で隠すという観点から同じ概念と言える。実際、バートン・スミスにMTAはCDC6600のppを思い出させると話したとたんに、彼は、CDC6600のppのパワーポイントを出してきた。
また、メモリについては、HITAC-401という大昔の計算機が、最初のアドレス(4,096まで?)がコアメモリでその後は、ドラムであったそうである(残念ながら、実際に見たことはないが)。
このように計算機を速くする努力は昔から行われており、根本的な点では、共通することが多い。これからの計算機を考える上でも、参考になることが多い。