第3章 ハイエンドコンピューティング研究開発の動向
4. FastSim
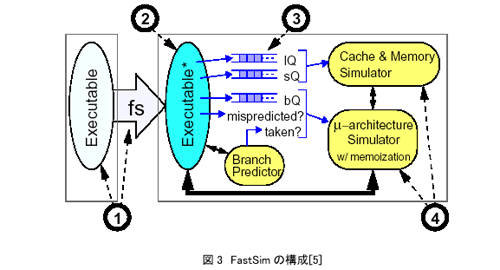
FastSim[4,5]はWisconsin大学で開発されているシミュレータであり、fast-forwardingと呼ぶ計算再利用技術を特徴としている。FastSimは図3のように構成されており、ターゲットマシンの実行形式①をfsと呼ぶツールによりシミュレータ用の実行形式②に変換し、それを直接実行することによって命令の動作をシミュレートする。このシミュレーションは命令の論理的な挙動、すなわち演算、ロード・ストア、分岐などの操作とそれに伴うレジスタやメモリの更新のみを対象とする。キャッシュの動作や命令スケジューリングなどの物理的挙動は、実行されたロード、ストア、条件分岐の情報を保持するキュー③を経由して駆動されるキャッシュ/メモリシミュレータとマイクロアーキテクチャシミュレータ④によりシミュレートされる。すなわち分岐命令の情報によりスケジュールすべき命令列が明らかになり、それらの中で遅延が一定ではないロード・ストアをキャッシュ/メモリシミュレータでシミュレートすれば、命令スケジューリングに必要な情報を全て入手することができる。
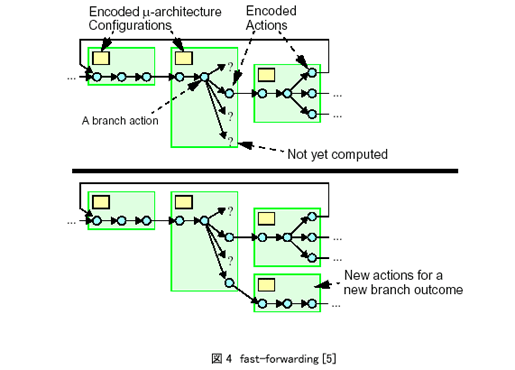
FastSimの特徴であるfast-forwardingは、マイクロアーキテクチャシミュレータの内部状態であるスケジュールされた命令群の状態を記憶しておき、それらの状態間の遷移をロード・ストアと分岐命令の挙動によって決定するという、一種の有限状態機械を動的に構築することにより行う。状態を記憶する領域であるmemoization cacheは初期的には空であり、ロード・ストアあるいは分岐命令をスケジューリングするたびに内部状態が保存される。その際、すでに保存されている状態と等しい状態であれば、前状態から現状態へのリンクがロード・ストアの遅延や分岐先情報とともに形成される(図4)。したがって記憶済の状態にあるときに、遅延が記憶済のロード・ストア、あるいは分岐先が記憶済の分岐命令をスケジューリングしようとすると、実際のスケジューリング計算は行わずに単に次状態へ遷移することによってシミュレーションが行われる。
このfast-forwardingはきわめて効果的であり、シミュレータを5~12倍に加速すること、またSimpleScalarに比べて9~15倍の性能が得られることが報告されている。一方、問題点としては、挙動が異なる全てのロード・ストアと分岐命令に対して内部状態を記憶するため、膨大な記憶領域が必要であることがあげられる。SPEC95ベンチマークを用いた性能評価によれば、3MB~900MBの記憶領域が消費されており、明らかに過大なメモリ消費である。またこの評価に用いられたターゲットマシンUltraSPARCは同時発行命令数や命令ウィンドウが小さく、ループ中での内部状態が安定しやすい傾向があり、より高度なプロセッサではさらに大きな記憶領域が必要であると予想される。
もう一つの問題点はFastSimの構成方式が特異であるため、一般の研究者・設計者がシミュレータを構築することが困難なことである。この問題に対してWisconsin大学のグループはFasileというマシン記述言語を用意することによって解決しようと試みている[5,6]。この言語では、ターゲットマシンのISAや命令スケジューラの機構に加え、memoizationのために保存・比較すべき情報を記述できるようになっている。したがってシミュレータの構築はある程度容易になると思われるが、現時点ではSimpleScalarの2倍程度の性能しか得られておらず、Fasileでの記述の最適化が課題となっている。
5. TurboScalar
TuboScalar(仮称)は本稿の著者らが開発中のシミュレータであり[7]、SimpleScalarに計算再利用の機構を組み込むことにより、マシン記述の容易性と高速化を同時に達成することを目的としている。TurboScalarとFastSimの最大の相違点は、計算再利用の対象をループにおける命令スケジューリング計算に限定していることである。ループ中では同一の命令スケジューリングが繰り返し出現することは容易に予想でき、またループであるので実行頻度も当然高いものとなる。したがってFastSimのように膨大な記憶領域を必要とすることなく、かつ計算再利用の効果を十分に発揮できるものと予想される。
TurboScalarは図5に示すように、先行実行、詳細実行、高速実行の3つの命令シミュレータから構成されている。先行実行はSimpleScalarのsim-safeをベースとしたもので、命令のエミュレーションを行って命令の論理的挙動をシミュレートするほか、詳細実行における命令スケジューリングに必要な情報である分岐命令とロード・ストアの情報を記録する。またループの検出も同時に行われ、詳細実行から高速実行への切り替え候補として記録される。
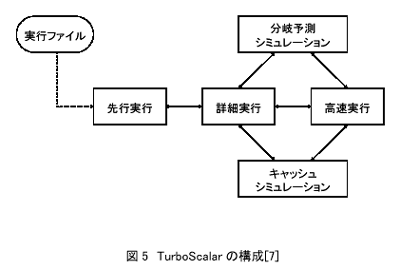
詳細実行はSimpleScalarのsim-outorderをベースとし、命令スケジューリングを行うとともに、ループが回転するたびにスケジューリング状態の保存と比較を行う。またループ中で行われたロード・ストアの遅延も保存する。このループ回転時の状態が過去の状態と一致すると、前状態から現状態へのリンクがロード・ストア遅延とともに形成され、高速実行へ移行する。高速実行ではループが継続し、かつロード・ストア遅延が過去に形成されたリンクの値と一致している間、スケジューリング計算を省略して状態遷移のみを行う。
上記のようにTurboScalarではループ回転時の状態のみを保存・比較するため、必要な記憶領域や保存・比較のオーバヘッドはFastSimに比べて格段に小さい。また予備的な評価によれば、計算再利用をループに限定しても効果は十分に発揮され、SimpleScalarの10倍程度の高速化が達成できる見込みである。なおシミュレータ構築の手間については、ベースシミュレータが広く利用されているものであるため、計算再利用のためのAPIを提供することにより比較的容易であると考えられる。
参考文献
[1] 中島浩:ハイエンドコンピュータ研究のためのシミュレーション技術.(HECC-WGの報告書),pp. 117--125, 日本情報処理開発協会, March 2001.
[2] M. Durbhakula, V. S. Pai, and S. Adve. Improving the Accuracy vs. Speed Tradeoff for Simulating Shared-Memory Multiprocessors with ILP Processors. In Proc. 5th IEEE Symp. High-Performance Computer Architecture, January 1999.
[3] D. J. Sorin, V. S. Pai, S. V. Adve, M. K. Vernon, and D. A. Wood. Analytic Evaluation of Shared-Memory Systems with ILP Processors. In Proc. 25th Intl. Symp. Computer Architecture, June 1998.
[4] Eric Schnarr and James Larus. Fast Out-Of-Order Processor Simulation Using Memoization. In Proc. ASPLOS-VIII, October 1998.
[5] Eric Schnarr. Applying Programming Language Implementation Techniques To Processor Simulation. Ph.D. Dissertation, University of Wisconsin-Madison, Computer Sciences Department, 2000.
[6] Eric Schnarr, Mark Hill, and James Larus. Facile: A Language and Compiler For High-Performance Processor Simulators. In Proc. PLDI 2001, June 2001.
[7] 中田尚、大野和彦、中島浩:高性能マイクロプロセッサの高速シミュレーションの構想.情報処理学会計算機アーキテクチャ研究会, 149-27, August 2002.
[8] D. Burger and T. M. Austin. The SimpleScalar Tool Set, Version 2.0. http://www.cs.wisc.edu/ mscalar/simplescalar.html.
[9] R. A. Uhlig and T. N. Mudge. Trace-Driven Memory Simulation: A Survey. ACM Computing Surveys, Vol. 29, No. 2, pp. 128--170, June 1997.
[10] M. Rosenblum, S. A. Herrod, E. Witchel, and A. Gupta. Complete Computer System Simulation: The SimOS Approach. IEEE Parallel & Distributed Technology, Vol. 3, No. 4, pp. 34--43, 1995.
[11] V. S. Pai, P. Ranganathan, and S. V. Adve. RSIM: An Execution-Driven Simulator for ILP-Based Shared-Memory Multiprocessors and Uniprocessors. In Proc. WS. Computer Architecture Education, February 1997.
[12] 中島康彦、緒方勝也、正西申悟、五島正裕、森眞一郎、北村俊明、富田眞治:関数値再利用および並列事前実行による高速化技術.情報処理学会論文誌ハイパフォーマンスコンピューティング、Vol. 43, No. SIG 6, pp. 1-12, September 2002.