第3章 ハイエンドコンピューティング研究開発の動向
久門 耕一 委員
1. はじめに
CPUの周波数、トランジスタ数はムーアの法則にほぼ従い向上してきた。しかし、計算機の性能という意味では、必ずしも上記の法則にしたがった向上が得られているとは言えない。良く知られた原因として、メモリアクセス時間がクロック周波数の向上に見合うだけ短縮していないことが挙げられている。しかし、これ以外にも、高周波数を達成するための長大なパイプライン構造が原因となった、非通常処理時のパイプラインブレークによるペナルティの増加が挙げられる。この状況は、HPCアプリケーションではなくビジネス向のサーバ処理に頻繁に出現するため、ビジネスサーバの性能向上に大きな障害となる。
このレポートでは、Linuxオペレーティングシステムを使ったサーバシステムにおける計算機アーキテクチャの持つ役割について述べる。
2. CPU性能の向上とそのペナルティ
1970年代にインテルのGordon Moorが提唱したいわゆるムーアの法則は、この法則をひとつの目標として努力が行われてきたこともあり、その後30年近く経た現在でも成り立ってきた。CPUの性能を向上させるには単にCPUのクロック周波数を向上させるだけではなく、処理するデータを処理に見合う速度で提供することが重要であるが、当時から1000倍近くCPUのクロック速度の向上が得られているのに対し、メモリ速度の向上は100倍程度に留まっているため、メモリアクセスがシステムのボトルネックになっていることは良く知られている[1]。
この解決のために、CPUクロックと同期して動く高速なメモリを用いたキャッシュメモリが導入され、主記憶へのアクセス頻度を低減させ、透過的にメモリアクセス時間の短縮が図られてきた。しかし、CPU速度とミスマッチを起こしているのは、主記憶へのアクセス速度だけではない。複数のCPUを使用したマルチプロセッサシステムにおいては、CPU間の通信があるCPUが書き換えたデータを他のCPUが読み出すことにより引き起こされる並列キャッシュ間のコヒーレンスミスを発生させるため、キャッシュサイズを無限に増大させてもキャッシュミスをなくすことは出来ない。また主記憶外にあるデータ、たとえばディスク上のデータへのアクセス、ネットワークから流入するデータに関しても、キャッシュへのデータ読み込みがCPUからのアクセスによるオンデマンド読み込みを行う限りキャッシュミスを引き起こす。
このようなキャッシュミスに起因する性能劣化以外に、近年の急激なCPUクロックの向上を達成するためのパイプラインの多段化、命令レベル並列度を引き出すためのスーパースカラのための内部状態の複雑化が原因となって、パイプラインの乱れが引き起こす大幅な性能劣化が急激に大きくなってきた。次章でインテルの32ビットプロセッサを例に取りサーバアプリケーションが近年のCPUでどのような性能となるのかを示しながら問題を分析する。
3. 各種インテルプロセッサによるアプリケーションの性能
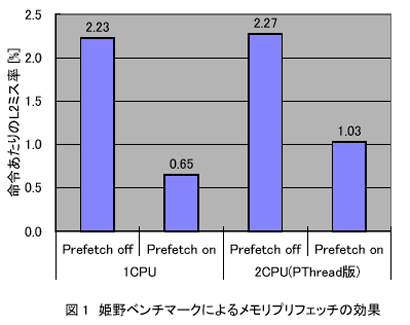
キャッシュミス時のメモリアクセス時間を隠蔽する重要な手段として、キャッシュ中に命令が実際にデータを必要とする前に準備しておくプリフェッチがある。インテルのP4マイクロアーキテクチャを採用するプロセッサは、規則的なメモリアクセスパターンをハードウェアにより検出し、先行してメモリアクセスを発行するハードウェアプリフェッチ機構を備えている。図1は、P4アーキテクチャを採用するXeonプロセッサ上で、流体系シミュレーションプログラムのベンチマークである姫野ベンチマーク[2]を実行した場合のハードウェアプリフェッチ効果をキャッシュミス率として表したものである。
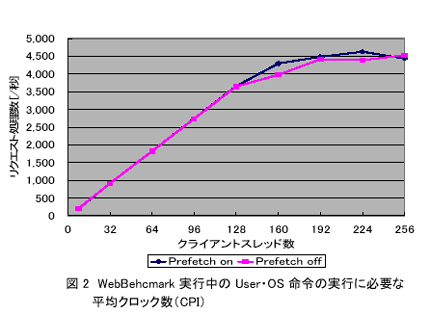
プリフェッチを行うことによりキャッシュミス率はプリフェッチを行わない場合の約1/3に減少している。この結果、プリフェッチによりアプリケーション性能は1CPU時に約2倍、2CPU時に1.5倍向上する。プリフェッチの効果をサーバアプリケーションにおいて評価するため、ZivDavis社の提供するWebBenchmarkを実行した場合のPrefetchOn/offによるサーバ性能の変化を図2に示す。姫野ベンチの場合とは異なり、プリフェッチの効果はほとんど得られず、最大でも5%程度の性能向上にとどまっている。これは、HPC系のプログラムのキャッシュミスは、規則的なメモリアクセスに基づくものが多いため、ハードウェアプリフェッチが可能であるのに対し、Webサーバのようなサーバプログラムにおけるキャッシュミスは、アクセスパターンが不規則なためプリフェッチの効果が期待しにくいことが主な原因である。
更に、サーバ系のアプリケーションプログラムの実行特性がHPC系のプログラムと大きく異なることとして、ディスク、ネットワークへのアクセスが多いため、プログラムの実行時間に占めるOS実行時間の割合が大きいことが上げられる。このように、一般にOS中の命令実行はUser部分の命令とはかなり異なった特性を示す。
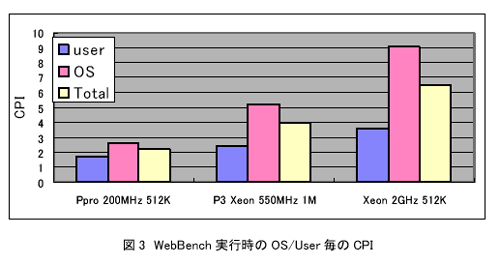
図3は前述のWebBenchmarkを実行した時の平均命令実行時間を、OS部分、User部分、総合と分けて示したものである。実行に使用したCPUは、PentiumPro 200MHz(L2Cache 512KB)、Pentium-lll 550MHz(L2Cache 1MB)、Xeon 2GHz(L2Cache 512KB)の3種類である。これらのCPUはいずれもスーパースカラ構造を持っており、理想的には1クロックあたり3命令の実行が可能である。PentiumProとPentium-lllはほぼ同じP6マイクロアーキテクチャで、パイプラインステージは10段程度であるのに対し、XeonはP4マイクロアーキテクチャで、20段以上のパイプラインステージに細分化することにより、高周波数化を達成している。これらいずれのCPUでもCPIが1を超えており、1クロックあたりの平均命令実行数は0.5〜0.1程度と、3に比較し大変に少ないことがわかる。更に、User部分のCPIとOS部分のCPIを比較するとOS部分のほうが大きく、新しい世代のCPUになるとその差が広がっていることも分かる。
User部分のCPIは200MHzのプロセッサと2GHzのプロセッサでCPIは約2倍で、10倍のクロック速度で命令は5倍高速に実行されていることが分かる。一方、OS部分のCPIは4倍弱となっており、10倍のクロックであっても実際の命令実行速度は2.5倍程度しか高速化されない。
このように、プログラム全体を平均したCPIはOS部分のCPIの増加と共に大きくなっており、プロセッサが新しくなるほどOS実行時間の割合が増加することが分かる。WebBenchのようなサーバアプリケーションではOS実行時間の割合が比較的高いため、OS部分がUser部分に比べ高速化しにくいことは、処理全体の高速化にとってのボトルネックになる。
4. CPU性能とOS実行時の性能
OSでのCPI増加が大きいことを検証するため、Linuxカーネルのシステムコールの中でも単純な処理であるgettimeofday()の実行時間を計測したのが図4である。
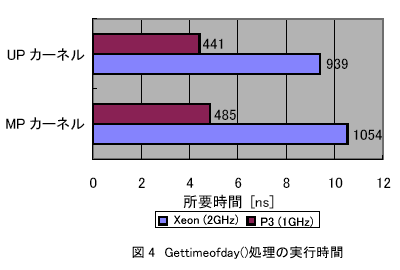
2GHzのXeonと1GHzのPentium-lllでは、クロックが高速なXeonのほうが2倍の実行時間が掛かっている。それぞれの実行に必要なクロック数は、Pentium-lllが441クロック、Xeonでは1872クロック必要で、Xeonは4倍以上のクロック数が掛かる。詳細な命令レベルの実行時間を分析することにより、これらの時間の大半はOSを呼び出すための動作モード切り替えによりパイプラインが乱されることと、内部状態の退避、復帰のために掛かることが分かっている。
また、図4のマルチプロセッサ用のLinuxカーネルと単一CPU用のカーネルの実行時間の比較から、マルチプロセッサカーネルを使用した場合には、それぞれの実行に必要なクロック数は、それぞれ44クロックと236クロック増加する。これは、複数プロセッサ間での競合を避けるためにスピンロックを行うコードが追加されるためで、1プロセッサ上での実行ではロック競合は起きないにもかかわらずこれだけのクロックが使用され、Xeonのほうがスピンロックコードの実行に多くのクロック数が掛かることが分かる。この増加は、ロック変数へのアクセスが命令実行のシリアライズを伴うLockプリフィクス付きメモリアクセスでパイプライン実行が乱されたために発生している。
5. 今後のCPUの行方
近年のコンピュータシステムの性能向上は、CPUの周波数向上と、メモリ速度の見かけ上の高速化を行うキャッシュメモリの増大により達成されてきた。パーソナルコンピュータの高性能化はマルチメディア処理を高速に行うために使用され、ビデオ編集などのマルチメディア用アプリケーションプログラムはHPCアプリケーションと同等の計算手法を用いており、最近の高速CPUはビジネスアプリケーションよりもHPCアプリケーションの実行に向いたCPUということが出来る。
HPC向けの高性能プロセッサであるベクトルプロセッサはCPUからメモリまでを長いパイプラインとして扱うことにより、メモリアクセスレイテンシをパイプライン処理の中に埋め込んできた。P6マイクロアーキテクチャからP4マイクロアーキテクチャに替わり、CPUの周波数が10倍以上高速化されてきたが、メモリアクセスレイテンシはほとんど変わらずほぼ200nsで短縮されてこなかったが、P4のハードウェアプリフェッチ機構はIA32命令互換を保ちながらベクトルプロセッサと同様のメモリアクセス時間隠蔽手段をとることで、HPCアプリケーションを高速化したと考えることが出来る。
一方、その代償として長いパイプラインステージと複雑な内部状態の管理からパイプラインが乱されたときのペナルティはクロック速度の向上を帳消しにし、性能低下が起きるほど大きくなっている。小さなトランザクションが多発するサーバアプリケーションにとっては、プリフェッチによるレイテンシ隠蔽よりはキャッシュの増大による実効アクセスレイテンシの短縮、さらには主記憶アクセスレイテンシを実際に短くする直接的な手段、またパイプラインの多段化よりは短パイプラインによる実行レイテンシの短縮が重要であることを示している。
今後、マルチメディア向け高性能プロセッサと、サーバ向け高性能プロセッサは2分化してゆくと考えられる。しかし、マルチメディアアプリケーションが今後も進展することは間違いが無く、その意味で現在のMPUを用いたPCクラスタによるHPCコンピューティングは当面高速化が続くことが予想される。これに対し、ビジネスサーバ向けのCPUの方向性は現時点ではあまり明確とはいえない状況である。
参考文献
[1] Himeno Benchmark http://w3cic.riken.go.jp/HPC/HimenoBMT/
[2] “Hitting the Memory Wall: Implications of the Obvious”, Wm. A. Wulf , et al.
ftp://ftp.cs.virginia.edu/pub/techreports/CS-94-48.ps.Z