3.1.2.1 はじめに
昨年度、高性能計算のkey technologyが計算の高精度予測であることを述べ、その中でハードウェア/ソフトウェアが協調した予測のようなメタレベル計算を実現する枠組が存在しないことを指摘した[1]。本節ではこのメタレベル計算を対象に、以下のような議論を行なう。
(1)メタレベル計算とは
高性能計算、特に並列計算に関するメタレベル計算としてどのようなものが存在するかを明らかにし、それらの必要性、重要性について議論する。
(2)メタレベル計算の枠組
メタレベル計算を実現するための枠組として考えられる候補をいくつか取り上げ、それらの利害得失について議論する。
(3)メタレベル・ハードウェア機構
メタレベル計算を支えるハードウェア機構として、どのようなものが考えられるかを議論する。
3.1.2.2 メタレベル計算とは
プログラムは一般に、問題を解くためのアルゴリズムを記述することと、プログラムを実行するプロセッサに対して指令することの、二つの側面を持っている。この後者の指令のほとんどは、前者のアルゴリズムを実現するために本質的に必要な操作、すなわちオブジェクトレベル計算のために行なわれる。しかし中には計算の効率を上げるなどの目的で、正しい解を得るためには論理的には必要ではない操作、すなわちメタレベル計算のための指令も存在する。
たとえばソフトウェアによるキャッシュ・プリフェッチは代表的なメタレベル指令であり、この操作が論理的には不必要であることは明らかである。また並列計算においては、並列実行により計算の効率を上げることがそもそもの目的であるため、メタレベル計算の頻度が逐次計算に比べて必然的に高くなる。その代表例は動的負荷分散であり、計算負荷の測定あるいは推定、それに基づく負荷の割付処理などは、全てメタレベル計算である。
これらのメタレベル計算は、プログラムに陽に書かれていたり、あるいは特定の機械命令を実行する形で行なわれるといった、狭義のものであると考えることができる。これに対して以下のような処理や操作を、広義のメタレベル計算としてとらえることができる。
コンパイラによる最適化、並列化
コンパイラに本質的に求められる処理が、プログラムの論理的な意味を充足するような機械命令列の生成であると考えれば、最適化のような処理は全てメタレベルのものであると考えることができる。すなわち、最適化はプログラムに対する実行前のメタレベル計算であり、並列化も一種の最適化である以上やはりメタレベル計算となる。この最適化や並列化がコンパイラの処理の中に占める割合は非常に高く、また今後も増大の一途をたどるものと予想される。
ハードウェアの高速化機構
キャッシュ、命令レベル並列処理、分岐予測など、高速化のためのハードウェア機構のほとんどは、メタレベルの操作を数多く含んでいる。たとえばキャッシュに関しては、データアレイのアクセスがオブジェクトレベル操作と、またタグアレイのアクセスやその結果に基づくヒット/ミスの判定などがメタレベル操作と、それぞれ考えることができる。昨年度の報告[1]でも述べたように、これらの「付加的ハードウェア機構」に費やされるトランジスタの割合は年々増加している。
また、昨年度の報告[1]で述べたように、将来の高性能計算では高精度の予測に基づく計算の効率化など、ソフトウェア/ハードウェアの協調による高度なメタレベル計算が求められる。すなわち上記の二階層の連携によるメタレベル計算が、今後のkey technologyとなる。
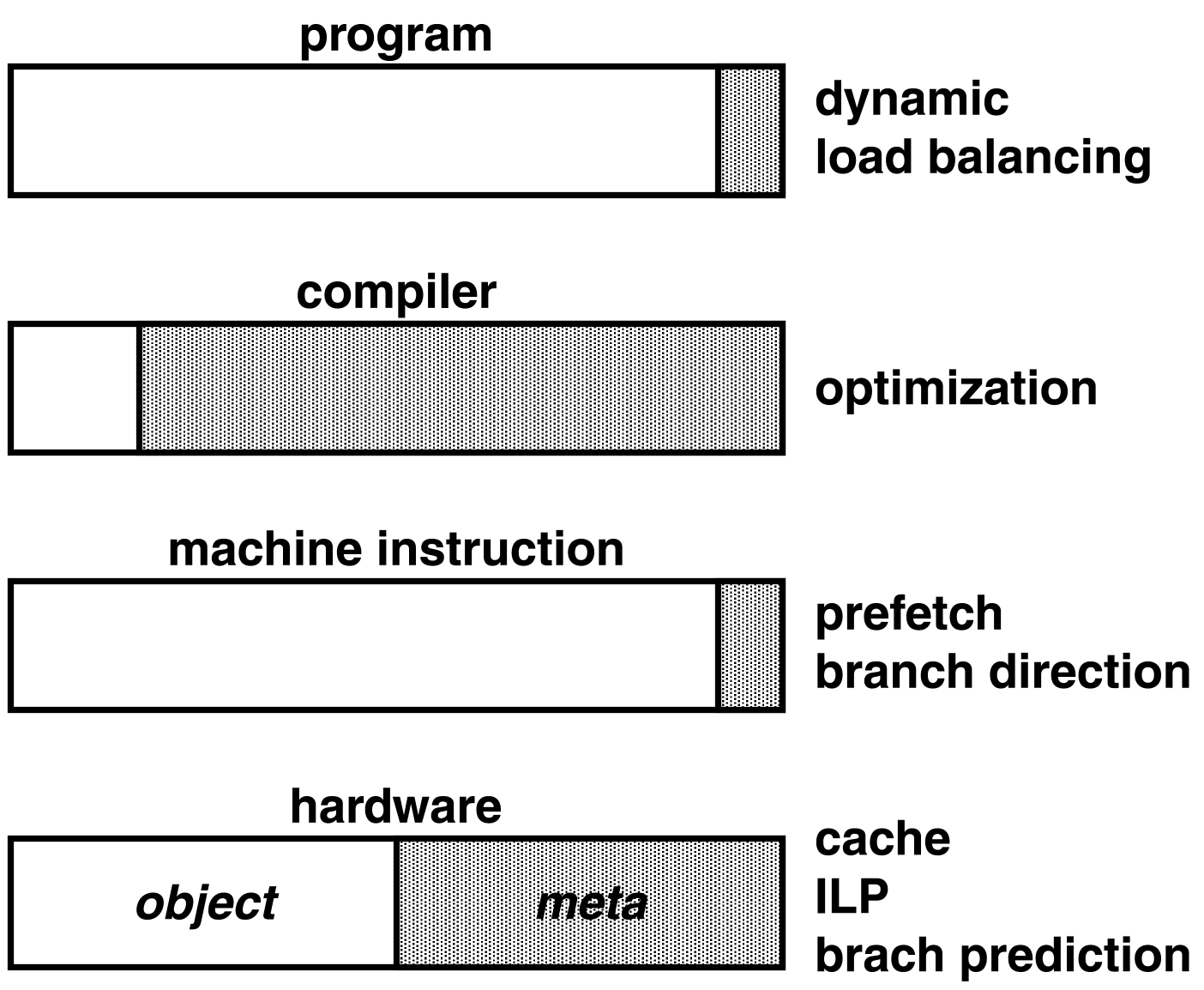
一方、以上に述べた各階層におけるメタレベル計算(処理、操作)とその比率は、図1に示すようなものとなっている。なお比率については観念的なものであるが、機械命令レベルの階層でのメタレベル計算の比率が、その上下階層に比べて極めて小さいことが示されている。すなわち、現状の機械命令セットや命令セット・アーキテクチャ(ISA)は、オブジェクトレベル計算に特化されており、メタレベル計算、特にソフトウェア/ハードウェア協調メタレベル計算には不向きな枠組であることが示唆されている。
図1 メタレベル計算とその階層
3.1.2.3 メタレベル計算の枠組[1] メタレベルISAの現状 前節で述べたように、現状のISAはメタレベル計算に十分に対応できているとは言い難いが、メタレベルの操作命令が皆無であるわけではない。将来のメタレベル計算の枠組を展望するための基礎として、ここではキャッシュ操作と分岐関連操作に関するメタレベル命令について述べる。
キャッシュ操作 前述のようにキャッシュ・プリフェッチは代表的なメタレベル操作であり、Alphaのように陽にプリフェッチ命令が存在するものや、zero registerへのロードがプリフェッチとして機能するものなどが商用レベルで存在する。より細かい操作、たとえばソフトウェア・キャッシュ・コヒーレンスのための無効化などの操作は、実装に依存した特殊な(特権)命令を必要とするのが一般的である。一方、個々のデータをキャッシュすべきか否かを動的に制御することの有効性は既に知られており、たとえばHPPA7200のassist cacheでは命令レベルでの選択が可能となっている[3]。
これらの種々のキャッシュ操作を表現するための統一的な枠組は今だ確立されていないが、命令コードに手を加えずに実現する方法の一つとしてJUMP-1のアプローチがある。これは物理メモリアドレスの上位ビットを、キャッシュに関する詳細な制御コードとして利用するものである[4]。したがって特定のアドレスに関して種々の操作が実現できる反面、利用可能な物理メモリ領域の削減、TLBエントリの消費、アドレス生成の繁雑化などの問題点がある。これらの内、アドレス生成以外の問題点は仮想アドレスのビットを利用することにより解決可能であり、64ビットアドレスの上位が未使用である現状を考えると、一つの解とみなすことができる。
分岐関連操作 分岐アドレスの方向あるいは命令コードに埋め込まれたhint bitにより、分岐方向の静的な予測結果を示唆する方法は、いくつかのプロセッサですでに採り入れられている。またAlphaのように、間接分岐アドレスの予測に関するヒントを与えるものもある。
この他、分岐を越えた危険な命令移動をサポートする枠組として、non-excepting命令やそれを拡張したsentinel schedulingなどが知られているが[5、6]、これらはIntelとHPが共同開発中のIA-64に採り入れられている[7]。
[2] メタレベルISAの将来
前項で述べた現状のメタレベルISAは、図2(a)に示すように、コンパイラによるメタレベル計算(計算状況の予測)の結果を、命令のannotationという形でハードウェアのメタレベル操作機構に伝える静的な一方通行の枠組である。
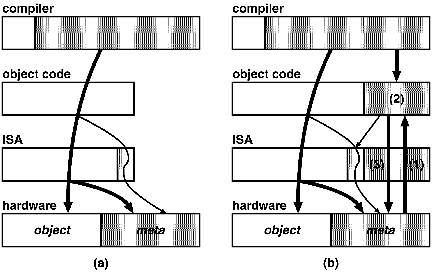
図2 メタレベルISAの現状と将来
一方、将来の高性能計算においては同図(b)に示すように、動的かつ双方向の枠組が求められる。
たとえば実行時に高精度の予測を行ない、その結果に応じて計算の効率化を図る場合、以下のような枠組が必要である。
(1)予測を行なうために必要な統計データなどを、ハードウェアのメタレベル機構から収集するための枠組。
(2)予測に必要なメタレベル計算が、オブジェクトレベル計算に与えるオーバヘッドを最小化するための枠組。
(3)予測結果によって動的に変化するメタレベル指令を、ハードウェアに伝えるための枠組。
上記のような枠組を実現する方法として、図3に示すように、以下の三つが考えられる。
(a)従来のISAを水平方向に拡張し、(1)や(3)のメタレベル操作を行なうための命令を追加する。(2)については命令レベル並列処理あるいはマルチスレッドなどの、既存のプロセッサ内並列処理技術によって対応する。ISAの連続性の面ではメリットが大きいが、ある程度の一般性と安定性を持った拡張ISAの構築が困難であることが予想される。また簡潔なマシンモデルという、ISAの一つの重要な側面を損なうおそれが強い。
(b)従来のISAよりも高いレベルに仮想ISAを、また同等あるいは低いレベルに(1)や(3)を含む実装ISAを設定し、(2)は仮想/実装ISAの中間に位置するインタープリタやダイナミック・コンパイラによって行なう。このアイデアはUniv. of WisconsinのJ.Smithらによるものであり[8]、ある意味ではマイクロプログラムの復権である。実装に依存しがちなメタレベル操作をある意味で隠蔽できるため、仮想ISAの一般性や安定性は確保できる。問題点としては、仮想ISA以下の階層の構築コストの他に、仮想ISA(SmithらはJAVA VMを想定)を介して、上位階層のコンパイラがメタレベル情報をうまく伝達できるかどうかが挙げられる。
(c)メタレベル計算に専念するコプロセッサによって(1)〜(3)の(ほとんど)全てを行なう。コプロセッサは単純なRISCで十分であり、メインプロセッサとの緊密な結合によってオブジェクトレベル計算への適切な介入を実現する。(a)と同様にISAの連続性は保たれ、また(b)と同様にメインプロセッサISAのマシンモデルとしての簡潔性や保たれる。問題点としては、生成コードの二重化に伴うコンパイラの負荷増大が最大のものであろう。
図3 メタレベルISAの将来像
3.1.2.4 メタレベル・ハードウェア機構
ソフトウェア/ハードウェア協調型の高度なメタレベル計算を行なうためには、3.1.2.2節で述べたような既存のメタレベル機構に加えて、新たなハードウェア機構が必要となる。しかし分岐予測投機機構のように複雑なハードウェアを新たに導入することは、トランジスタと設計の両面からcost effectiveではない可能性が高い。したがってソフトウェアとの協調を第一義的に考え、以下の3点に集約することが得策であると考える。
統計情報収集機構 ソフトウェアによって処理すると最もオーバヘッドが大きそうなものが、プログラムの挙動を動的に把握するための統計情報の収集である。一方ハードウェアにとっては、あらかじめ定義されたイベント集合に対して、個々の要素の生起を検出して計数することは比較的容易である。また統計情報であるという性質から、その計測結果は完璧なものである必要はなく、時間的あるいは計数そのものの誤差も一定範囲で許容される。
計算状態保存機構 予測と投機のように、オブジェクトレベルの計算状態に一定の影響をもたらすような方式は、メタレベル計算による効率化の重要なターゲットとなる。このために必要となる計算状態の保存は、やはりソフトウェアが不得手とする操作であり、ハードウェアによるサポートの効果は極めて高い。なお昨年度の報告でも述べたように、柔軟性や一般性の確保のために時間コストの最小化が困難である場合には、時間的成功コスト(すなわち保険コスト)を最小化する方向でチューニングすべきである。
一般的計算機構 単純なプロセッサは比較的低コストで設計/実装が可能であり、ソフトウェアとの協調動作という点でも適している。前節で述べたコプロセッサ型のメタレベルISAではもちろん、他のタイプのISAにおいてもメタレベル計算を部分的に担当するようなコプロセッサを導入し、ソフトウェア/ハードウェアの両面で設計コストの大幅な節約を図るのが得策である。
参考文献
[1]中島 浩. 高精度予測と高性能計算.ペタフロップスマシン技術に関する調査研究II、 pp.49-57, JIPDEC/AITEC, March 1998.
[2]中島 浩. 投機に投資しよう. 情報処理、 Vol.40, No.2, pp.195-201, February 1999.
[3]K. K. Chan, et al., Design of the HP PA7200 CPU, In HP Journal, Vol.47, No.1, February 1996.
[4]S. Tomita, et al. Hardware Architecture, In The Massively Parallel Processing System JUMP-1,pp.169-224, OHMSHA Ltd., February 1996.
[5]R.P.Colwel, et al. A VLIW Architecture for a Trace Scheduling Compiler, In Proc. ASPROS'87, pp.180--192, April 1987.
[6]S.A.Mahlke, et al. Sentinel Scheduling for VLIW and Superscaler Processors, In Proc. ASPROS'92, pp.238-247, October 1992.
[7]R.E.Curry. IA-64 Architecture Delivers New Levels of Performance and Scalability, In Platform Solution, Intel Corp.,
http://developer.intel.com/solutions/archive/issue6/stories/ia64.htm
[8]J.E.Smith and S.Sastry, Achieving High Performance via Co-Designed Virtual Machines, In Proc. IWIA'98, October 1998.