第3章 ハイエンドコンピューティング研究開発の動向
妹尾 義樹 委員
1. はじめに
分散メモリ並列システム向けの並列プログラミング言語HPF(High Performance Fortran)[1]について、その最初の仕様が定められてから、この春でちょうど10年になる。昨年11月に米国バルチモアで行われたSC2002国際会議において、地球シミュレータ上でHPFを用いたプラズマシミュレーション並列化の成果がGordon Bell Awardの言語賞を受賞した[2]。陽解法のTVD差分スキームを用いたプログラムで、並列化が比較的容易なコードではあるが、手続きにまたがったSHIFT通信やリダクション演算を含む実用コードであり、MPI[3]で記述すればプログラムの全体構造の変換や、通信のための大量のMPI呼び出しが必要になる。このコードに対して30数行程度(includeファイルに記述した共通の宣言文を複数手続きで引用しているので、実質的には10行程度)のデータマッピング指示挿入するだけで14.9テラフロップスを達成したことが認められた。ようやくここまで来たか、と感慨深いものがあるが、HPFの本当の実用化という意味では、まだまだ課題が残っているのも事実である。
本報告では、この10年間のHPFの歩みを総括するとともに、最近の並列プログラミングインタフェースの話題と、今後の方向について、私見を述べる。特に、HPFとMPIの中庸を狙ったといえる、Co-Array Fortran[4]やGA (Global Arrays)[5]を紹介し、MPIやOpenMP[6]を含めた種々のプログラミングインタフェースの比較を行い、今後の方向性について考えてみたい。
2. 分散メモリ向けプログラミングインタフェースとHPF
2.1 分散メモリプログラミングインタフェース
並列計算機のアーキテクチャは大別して、共有メモリ型と分散メモリ型に分けることができる。共有メモリモデルは、複数のプロセッサ間で主記憶のデータが共有されるシステムである。このため、プロセッサ間でのデータの明示的な受渡しは不要である。そのためプログラミングは容易になるが、接続できるプロセッサ台数に限界があるなどの欠点がある。分散メモリモデルは、プロセッサと主記憶から構成されるシステムが複数個互いに接続されたシステムである。共有メモリモデルに比較して、大規模なシステムを構築可能であるという特徴がある。しかし、他のプロセッサのデータを利用するためには、明示的にデータの授受を行う必要があるなど、プログラミングは共有メモリモデルに比較すると難しい。また、この2つの中間に位置づけられる分散共有メモリアーキテクチャ[7][8][9]もある。物理的には、分散メモリとして構成されているシステムを基にしているため、HWまたはSW制御によりプログラムからデータを共有メモリとして扱うことができるが、データが分散メモリのどこに格納されているかによって、性能差が生ずる。
分散メモリシステム(あるいは、分散共有メモリ)上の並列化における最も重要な2つのポイントは、データ分割(処理対象データの分散メモリ上への配置)と、計算マッピング(計算処理の各要素プロセッサ(以後PEと記す)への分配)である。並列化の良し悪しは、並列性の抽出のみならず、いかにデータアクセスの局所性を高め、プロセッサ間通信を減らすかに大きく依存する。プログラマの立場からすると、データ分割と計算マッピングの両方を指定するというのは、大変な重荷になる。これが分散メモリマシン上での並列化の難しさの本質なのであるが、データ分割を主に考えてプログラミングする場合には、決めたデータ分割に合わせるように計算マッピングを指定する必要があるし、逆に、計算マッピングを主に並列化を決めた場合は、これに合わせたデータ分割およびデータ転送処理の記述が必要となる。
このデータ分割と計算マッピングをユーザがプログラム上でどのように記述するかによって、並列プログラミングインタフェースを類型化することができる。詳細は後述するが、MPI(Message Passing Interface)は両者をすべて利用者が指定するインタフェースであり、商用コンパイラとしては存在しないが、完全自動並列化コンパイラというものがあれば、これは何も指定しないというインタフェースになる。主に片方を指定する方法が中庸として考えられ、HPFなどのデータパラレル言語は、データ分割をユーザが明示的に指示し、それ以外の仕事を処理系(コンパイラ)に任せようというものである。逆に、計算マッピングだけを指示するのが、共有メモリ用システム用のインタフェースとして発展したOpenMPなどの言語である。
2.2 HPF
HPF(High Performance Fortran)は、その名の通り高性能コンピューティング用に開発されたプログラミング言語である。 Fortran言語に最小限の指示文を付加することにより、分散メモリ並列システムで簡単に高い性能を得ることを目指している。
HPFの本質的な考え方は、データ分割をユーザが明示的に指示し、それ以外の仕事を処理系(コンパイラ)に任せようというものである。これにより、ユーザは煩わしいプログラムのSPMD化や通信管理から解放され、従来のFortranプログラミングと非常に親和性の高い方法で分散メモリシステムを利用することが可能となる。HPFでは、プログラムは従来の逐次言語と同様にシングルストリームのセマンティックスで記述され、データはすべて大域的に扱われる。これに対して、MPIなどのメッセージパッシングプログラムでは、SPMD (Single Program Multiple Data Stream)形式であり、プログラムは、並列実行に参加するすべてのプロセッサがそれぞれ独自の制御を持つ。つまり、IF文などによるプログラムの実行経路がプロセッサごとに異なることをユーザが意識してプログラムする必要がある。また、プログラム上で宣言されたデータは、すべてのプロセッサが独自のコピーを持つことが前提であり、プロセッサ1上の配列Aとプロセッサ2上の配列Aは別々のデータとして扱われる。
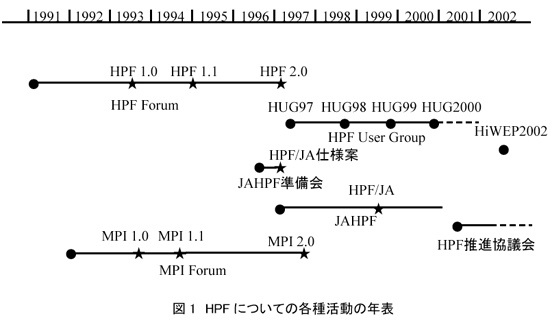
HPF言語の標準化活動は、ISOやANSIなどの公式な標準制定機関ではなく、Rice大学のKen Kennedy教授を中心とするプライベートな組織HPFF(HPF Forum)で行なわれた。ANSIを中心に行なわれたFortran90の仕様制定に10年以上かかった反省からである。言語仕様に組み込むべき新機能ごとにサブワーキンググループを作り、ここで仕様案が作られ、これらが参加者の投票を経て正式に仕様に組み込まれる。活動は1991年に開始され、1993年にHPF1.0が制定された。その後もHPFF2において、仕様の曖昧性のチェックや、HPF1.0で不十分であった機能拡張が検討され、1997年1月にHPF2.0[10][11]の仕様がまとめられた。
HPFFのホームページが、http://www.vcpc.univie.ac.at/information/mirror/HPFF/ にあり、HPF言語の仕様や関連研究プロジェクトの情報が得られる。
2.3 HPFのこれまでの歩み
筆者は、1987年あたりから並列化言語の研究開発に携わるようになり、以降15年以上にわたり、並列マシンアーキテクチャ、言語インタフェース、コンパイラ技術の変遷とともに歩んできた。この15年を振り返るとともに、HPFの歩みを総括してみたい。
(1)1990以前の並列化インタフェースの状況
1985年から1990年にかけてという時代は、商用システムとしてベクトルマシンの全盛期であり、CRAY、NEC、富士通、日立のハイエンドスーパーコンピュータに加え、AlliantやConvexなどのミニスーパーといわれるシステムも広く使われた。また、分散メモリを採用したスカラプロセッサベースの高並列システムも多く開発・商用化された時期でもある。今では、ほとんどが消えてしまったが、Thinking Machine(CM5)やNcube、FPS、Cenju、AP1000など、種々の工夫をこらしたマシンがいろいろと現れ、Supercomputing(SC)国際会議では、種々のアーキテクチャ、デバイス、コンパイラ、通信ライブラリなどが所狭しと出展され、楽しい時代であった。
この時代、自動ベクトル化技術は、すでに成熟しており、共有メモリ向けの自動並列化技術に各社がしのぎを削っていた。ベクトル化も自動並列化もデータ依存関係解析という意味では、ほとんど同様の技術で良いのだが、ベクトル化が局所的なループネストだけを対象に最適化できるのに対し、並列化はできるだけ並列処理単位を大きくし、並列処理や同期などのオーバヘッドを減らす必要があり、このために手続きをまたがる最適化が必須となる。手続き間解析は、技術的には完成の域に達し、Convexなどいくつかの商用コンパイラで実装されたが、手続き間の解析時間が実用の大規模なプログラムになると膨大になることや、手続きごとに別ファイルにして、変更があったファイルだけ再コンパイルするmakeの環境で、オブジェクトの管理がややこしくなるなどの理由であまり日の目を見ることはなかった。一方で手続きをインライン展開する手法は、展開すべき手続きをユーザが指定するなどの方法で、簡便に用いることができ、また効果も大きいことから、現在でも広く用いられている。
自動並列化のもうひとつの問題は、ベクトル化に比べて最適化の選択肢が多いということである。ループネストの並列化ひとつにしても、ループ入れ替えやアンローリング、並列化すべきループの選択などが複雑に絡み合い、選択によって性能が大幅に変動するケースが多い。また、変な並列化を行うと、性能が極端に劣化するという問題もある。このため、並列化で最初にユーザに普及したのは、CRAY-XMPやNECのSX-3などでサポートされたマイクロタスキングとマクロタスキングというインタフェースである[12]。マイクロタスキングとは、プログラム中の主にループに対して並列化指示文を挿入するインタフェースであり、ワークシェアリングといって、並列化対象以外の部分は、全プロセッサで重複して実行されるというプログラミングモデルを採用している。OpenMPの原型となったインタフェースでもある。自動並列化(autotasking)との相違点は、コンパイラが勝手に並列化を判断することが一切ないという点と、ワークシェアリングモデルのため、指示文を無視して逐次実行したものと、プログラムの意味が変わってしまうという点である。自動並列化もループに並列化の指示文を挿入していくが、あくまでもコンパイラの自動処理の助けとなる情報を埋め込むという形式で、指示文を無視した実行が、並列処理と(指示文が正しく指定されていれば)一致する。
マクロタスキングとはスレッド並列処理の枠組みであり、手続きを非同期に呼び出し、呼び出された手続きを別々のプロセッサで実行することで並列処理を実現する。呼び出された手続き間の同期処理や排他制御は、イベントやロックという特別な変数を用いたライブラリ呼び出しで実現されている。Pthreadライブラリと同様のものと考えてもらえると分かりやすい。
1980年台の後半には、マクロタスキング/マイクロタスキング/自動並列化の技術が共有メモリシステムを対象としてほぼ確立され、計算機システムベンダや、Kuck & Assciates、PSR、APRなどのベンチャー企業により製品化されたシステムが多数の実用コード開発に用いられるようになった。
この一方で、性能の追求とともに、分散メモリ型のマシンも多く開発され、計算機ベンダそれぞれが固有のメッセージパッシングライブラリを提供した。PVM[13]やPARAMACSなどのたくさんのシステムで共通的に使えるライブラリも開発された。他方、これらのシステム上での並列化コンパイラを実現しようという研究活動も世界各地で立ち上がり、データマッピングを明示指定するという考え方の元になったPurdue大学のKALIコンパイラ、Rice大学のFortran D[14]、欧州ではHans ZimaらのSUPERBなど多くの研究がなされた。また、SIMDマシンのThinking Machine上インタフェースとして、Forall文を用いた並列化が特徴であるCM Fortranも、この時代に実用化されている。Fortran DとCM FortranはHPFの言語仕様開発に大きな影響を与えた。日本では、この時期スーパーコン大プロが最終段階にあり、共有メモリとローカルメモリの階層構造を持ったベクトル型のスーパーコンの上で、PhilやParagramという並列言語が開発された。我々は、CenjuやSX-3をターゲットにして並列化支援環境PCASEの開発を行い、自動並列化エンジンを搭載した半自動の並列化システムを実現して、後のHPF開発の礎を築いた。
データ依存解析などの並列化のための基礎理論は、Illinois大学などの研究活動によって、この時期にはすでに完成されていたが、これを実用化するための技術が非常に進歩した時期であった。リダクションなどの、プログラム中の特定構造(イディオム)の認識、ループ融合・分割・入れ替えなどのループリストラクチャリング技術、先に述べた手続き間解析・インライン展開、ループ長などの実行時パラメータに基づく最適化切り替え、種々の指示行の導入によるユーザによる最適化促進技術などである。キャッシュ最適化やスーパースカラ処理などRISC用のコンパイル技術も大きく発展した時代であり、コンパイラ技術者にとってはやりがいのある時期であった。
(2)HPF誕生前後の状況
分散メモリマシン用の標準のプログラミングインタフェースを作ろうという機運が高まり、データパラレル言語HPFの言語仕様を定めるべく、HPFF(HPFフォーラム)の設立が決まったのは1991年11月のSupercomputing 91国際会議のBOFであった。欧米のアカデミアおよび企業のコンパイラ技術者およびNASAなどのユーザが1月半に一度のペースで集まり、基本仕様が1年間でまとめられた。リーダはRice大学のKen Kennedyであり、言語仕様のベースとなったのはFortran-Dであった。言語仕様策定のポイントの1つとなったのは、ベース言語をFortran77にするのかFortran90にするのかという点であった。安定したFortran90処理系がまだない状況で、これをベースとするのはリスクが高いし、HPF処理系の早期実装の妨げになるとベンダから反対意見があったが、結局Fortran90がベースに選定された。今、振り返ってみると、この後、巨大仕様のFortran90の処理系開発に各ベンダとも手間取り、この選択がHPFの実装を大きく遅らせる要因となった。F77、F90の両方での実装が可能な仕様にしておけば、その後の米国でのHPFの事情はかなり変わったのではと思う。
HPFFにおける言語策定作業は、Fortran90の仕様策定が10年近くかかったことと比べると、よく1年と少しでまとめられたと思う。毎回の会合は普通3日間行われ、この中で検討項目ごとのワーキンググループに別れ、それぞれ仕様案が検討される。毎日の最後には全体で仕様案の採択が深夜まで行われる。技術課題は宿題として参加者が分担して持ち帰り、次回以降に引き続き検討される。会議を開いて、この中で実のある議論を尽くして、参加者で協力して新たなものを作っていくというやり方は、なかなか日本ではできない。参考にすべきだと思う。
1993年の春にHPF1.0言語仕様が定まり、そのあとすぐに、APR(Applied Parallel Research)やDECなどが、フル実装ではないが、HPFコンパイラの開発に成功した。アカデミアでは、ドイツGMDのThomas BrandesがAdaptor[15]というHPFシステムを早期に開発した。やはり、Fortran90への対応とHPF開発の両立は難しく、初期のHPFは性能・品質の両面で問題が多く、期待が大きかった分、欧米でのユーザ離れを招く要因となった。我々は、1992年の段階で、簡単なデータ分散指示を受理するCenju用のコンパイラの開発に成功し、これを元にHPFコンパイラの開発を開始した[16]。Fortran77ベースであり、HPF Conformingとは言えないものではあったが、最初のHPF処理系が動き出したのは1994年の夏であった。アカデミアでは、Vienna大学のVienna Fortran Compiler[17]、 Rice大学のD system[14]などで、通信最適化の種々の方式(Communication Vectorization, Communication Aggregation, Communication Coalescing)や非定型処理への対応技術[18]などが開発された。
(3)HPFの成熟への歩み
HPFFは、1993年から1年間は言語拡張の活動をストップし、言語のバグフィックスに努めた。アカデミアは、それまでのHPFの弱点と言われた、非定型データ構造への対応や計算マッピング指示、タスク並列処理への対応などのHPF拡張活動の継続を求めたが、ベンダサイドからの、「成熟したコンパイラが完成しないうちに、次々と新規言語機能を追加するのは、ベンダの処理系開発が追いつかず、マイナスに作用する」との意見を採用した結果である。
そして、1994年からHPFFが再開され、HPF2.0の仕様策定作業が始まった。筆者はHPF1.0策定作業には、あまり参加できなかったが、Rice大学での勤務の機会を得たこともあり、HPF2.0の作業にはずっと参加することができた。アカデミア主導で、非定型分散(GEN_BLOCK、Indirect分散)やタスク並列化など応用範囲を広げるための新機能追加が検討され、ベンダ中心でコンパイラ能力不足を補うための計算マッピング指示(ON指定)やMPIなど他の並列化インタフェースとの共存機能(Extrinsicインタフェース)が検討された。最大の議論となったのは、言語仕様の肥大化にどう対応するかということであった。HPF1.0では、すべての機能の実装が大変で、どのベンダも自コンパイラをHPF1.0準拠と言えなかったためである。その結果、HPF1.0から、実行時分散変更機能(ダイナミック分散)など、実装が大変な機能を除いた、より基本機能だけのセットをHPF2.0と定義し、HPF1.0から除いた機能と、新規に策定した機能を、HPF2.0 Approved Extensionsとして定義することとなった。
1996年にHPF2.0が定まり、1997年にHPFFは散会し、活動はユーザ主体でHPFを利用技術を検討する、あらたに設立されたHPF User Group(HUG)[19]に引き継がれた。ただし、欧米では、並列アプリケーション開発プロジェクトが、1995年ごろから多数立ち上がり、これらがすべてMPIを採用したことにより、徐々にHPFに対するユーザの興味は薄れていった。
この時期、日本では、NEC、富士通、日立がHPFやVPP Fortranコンパイラ[20]を開発しており、また地球シミュレータプロジェクトも開始の時期であった。地球シミュレータプロジェクトの生みの親である故三好さんは、この壮大なマシン用の並列プログラミングインタフェースをどうするか検討を開始していた時期であり、また上記3社も、欧米でHPFに暗雲が立ち込める中で、将来のコンパイラ開発をどうするかの岐路にあった。三好さんには、「欧米はMPIベースで良いが、日本で分散メモリマシンを普及させるには、ユーザフレンドリーな並列化インタフェースが不可欠」との思いがあった。これらの人たちの思惑が一致し、1996年から、日本主導で次世代のデータ並列言語の開発するための活動が開始された。まったく白紙の状態から言語仕様検討が開始されたが、議論の末、一応世界標準として認知されているHPFがもっとも有望だとの結論に達し、これをベースにインタフェース検討を行うことになった。三好さんと3社の技術者15名程度を中心に1996年の夏から、月に2度の検討会を繰り返し、半年でHPF2.0の問題点の洗い出し、不足機能の検討を行った。1997年1月までに、主なHPFへの拡張機能を固め、この時点から、日本の主なHPCユーザを交えたおよそ40人で、JAHPF(Japan Association of HPF)がスタートした。約2年の議論を経て、HPF/JA 1.0仕様[21]が定められた。拡張は、新機能の採用よりも、実用性を優先させ、ユーザの手軽な指示追加で高性能を得られるようなものを中心に採用した。主な拡張機能は、複数のSHIFT転送を最適化するためのSHADOW機能拡張、実用コードで現れる複雑なReduction並列化機能、通信スケジュール再利用機能、非同期データ転送機能などである。VPP Fortranや3社のコンパイラ開発の知見、JAHPFでのユーザコードの並列化実践による必要機能洗い出し、HPF+[22]などの欧米での研究成果などが検討のベースになった。ユーザプログラムの並列化もユーザ・コンパイラ技術者の共同作業として多数進められ、プラズマ流体コードや粒子コードなどで多数の成果を納めた。東京で開かれたHUG2000がこの集大成である。2001年から、仕様検討から、HPFの普及促進に重点を移す目的で、JAHPFはHPF推進協議会(HPFPC、www.hpfpc.org参照)として体制の刷新を行った。図1にこれら活動を年表形式にまとめておく。地球シミュレータ用のHPFコンパイラはSX用の処理系HPF/SX V2[23][24]を拡張して2002年に完成したが、これまで述べてきたコンパイラ技術開発、HPF活動の集大成である。富士通からもHPFコンパイラが正式に製品化された[25]。MHDシミュレーションで大規模VPPシステムを用いて300GFLOPS以上の性能が達成された[26]。
HPFPCは現在も活動を継続しており、地道ながら新たなHPFユーザの獲得や、フリーのPCクラスタ用処理系の開発、ドキュメント整備などの活動を行っている。HPF/JA仕様を装備したコンパイラはNECおよび富士通から製品化されており、多くの利用者の並列化負荷を大幅に軽減できる、安定した処理系になったと思っている。もう5年早く、現在のコンパイラが実現できていれば、HPFの現状はかなり変わったのにと思う。NECも実はF77ベースからF90ベースに移行するのに、余計に3年を費やしている。他社も同じであろうと思うと、最初にF90ベースを選択したことが残念である。