3.2.2 自動並列化コンパイラとアーキテクチャ支援 笠原博徳 委員
3.2.2.1 はじめに
現在日本のスーパーコンピュータメーカは世界トップのハードウェア技術を有し、現時点でのピーク性能は1TFLOPSを越え、21世紀初頭には数十TFLOPS以上のピーク性能をもつマシンが開発されると予想される。しかし、現在のスーパーコンピュータは、ピーク性能の向上と共にプログラムを実行したときの実効性能との差が大きくなっている、すなわち価格性能比が必ずしも優れていると言えない状況になっている。また、使い勝手的にも、ユーザは問題中の並列性を抽出し、HPF、MPI、PVMなどの拡張言語あるいはライブラリを用いハードウェアを効果的に使用できるようなプログラムを作成しなければならず、一般のユーザには使い方が難しいあるいは使いこなせないという問題が生じている。さらに、これらにも起因して、世界のHPC市場を拡大できないということが産業界にとって大きな問題となっている。
この価格性能比、使いやすさの問題を解決し、スーパーコンピュータのマーケットを拡大するためには、ユーザが使い慣れているFortran等の逐次型言語で書かれたプログラムを自動的に並列化する自動並列化コンパイラ[4-10、18]の開発が重要となる。
一方、汎用マイクロプロセッサの分野では、我が国の産業界が世界をリードしているとは言い難い状況にあることが認識されている。しかし、従来我が国の電気産業を支える一つの柱となっていたDRAMによる利益確保が将来的に困難と予想される状況では、より付加価値の高い汎用マイクロプロセッサの開発を検討することが必要である。
その際、海外企業が大きなシェアをもち、さらに命令レベルの並列性[1-3]の限界から将来的な実効性能の向上が難しいと予測されるスーパースカラやVLIWではなく、21世紀初頭の有力なアーキテクチャの一つとなると考えられるシングルチップ・マルチプロセッサ[2、24]について検討を行うことは、産業界がこの分野で一定のシェアを獲得するために重要と考えられる。また、このようなシングルチップ・マルチプロセッサに関する検討は、上述のHPCの価格性能比向上に対しても重要な役割を果たすものと思われる。
ただ、このようなシングルチップ・マルチプロセッサの研究開発を行う際にも、単に従来の主記憶共有アーキテクチャでプロセッサを集積しただけでは、近隣諸国の技術レベルの向上も著しい現在、世界に対する国産プロセッサの優位性は得られない。21世紀に向け十分な利益を上げることを可能とするためにはアーキテクチャの独自性、高性能化、低価格の達成が必須である。
このためには、プログラム中の命令レベル並列性、ループ並列性、粗粒度並列性をフルに使用できるマルチグレイン並列処理[4]のように、真に実行すべき命令列からより多くの並列性を抽出し、システムの高価格性能比の達成すると共に、誰にでも使えるユーザフレンドリなシステムの構築を可能とする新しい自動並列化コンパイル技術と、それを生かせるようなアーキテクチャの開発が重要であると思われる。
本報告書ではこのマルチグレイン並列化コンパイラと、それをサポートするマルチプロセッサアーキテクチャについて述べる。
3.2.2.2 マルチグレイン並列化コンパイラ
マルチグレイン並列処理[4、8、25]とは、サブルーティン、ループ、基本ブロック間の粗粒度並列性[16]、ループイタレーション間の中粒度並列性(ループ並列性)[5-9、18、19]、ステートメントあるいは命令間の(近)細粒度並列性[11、14]を階層的に利用する並列処理方式である。この方式により、従来の市販マルチプロセッサシステム用自動並列化コンパイラで用いられていたループ並列化、あるいはスーパースカラ、VLIWにおける命令レベル並列化のような局所的で単一粒度の並列化とは異なり、プログラム全域に渡るグローバルかつ複数粒度によるフレキシブルな並列処理が可能となる。
(1)粗粒度並列処理
単一プログラム中のサブルーティン、ループ、基本ブロック間の並列性を利用する粗粒度並列処理は、マクロデータフロー処理とも呼ばれ[8、16、17]、OSCARマルチグレインFortran並列化コンパイラで世界で初めて自動並列化が実現された[4、25]。
OSCARコンパイラでは、粗粒度タスク(マクロタスク)として、単一のFortranプログラムよりRB (Repetition Block)、 SB (Subroutine Block)、 BPA(Block of Pseudo Assignment Statements)の3種類のマクロタスクを生成する。RBは各階層での最外側ナチュラルループであり、SBはサブルーティン、BPAはスケジューリングオーバーヘッドあるいは並列性を考慮し融合あるいは分割された基本ブロックである。
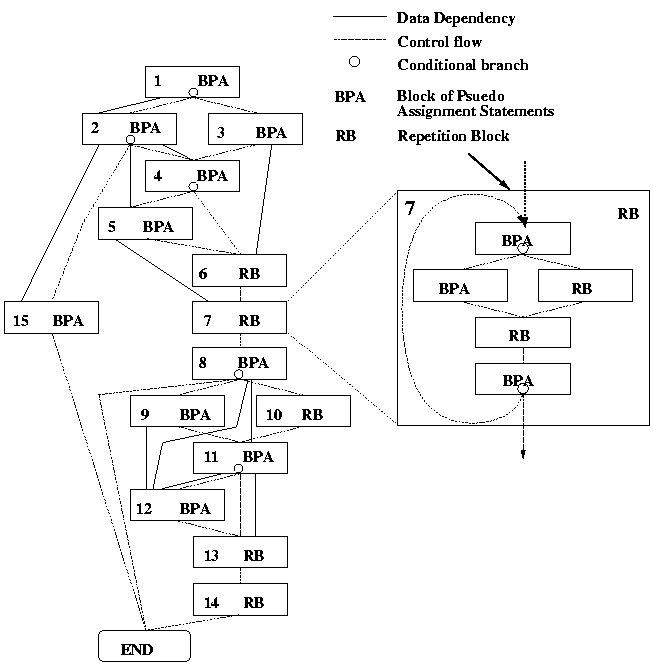
次にマクロタスク間の制御フロー[7、8]とデータ依存[5、7、8]を解析し、図1のようなマクロフローグラフ(MFG)を生成する。MFGでは、各ノードがマクロタスク(MT)、点線のエッジが制御フロー、実線のエッジがデータ依存、ノード内の小円が条件分岐文を表している。また、MT7のループ(RB)は、内部で階層的にMT及びMFGを定義できることを示している。
次に、マクロタスク間制御依存[7、8]及びデータ依存より各マクロタスクが最も早く実行できる条件(最早実行可能条件)[4、8、26]すなわちマクロタスク間の並列性を検出する。この並列性をグラフ表現したのが図2に示すマクロタスクグラフ(MTG)である。MTGでも、ノードはMT、実線のエッジがデータ依存、ノード内の小円が条件分岐文を表す。ただし点線のエッジは拡張された制御依存を表し、矢印のついたエッジは元のMFGにおける分岐先、実線の円弧はAND関係、点線の円弧はOR関係を表している。例えば、MT6へのエッジは、MT2中の条件分岐がMT4の方向に分岐するか、MT3の実行が終了した時、MT6が最も早く実行が可能になることを示している。
図1 マクロフローグラフ(MFG)
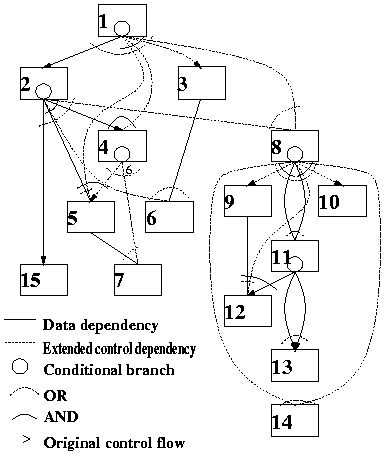
図2 マクロタスクグラフ(MTG)
次にコンパイラは、MTG上のMTをプロセッサクラスタ(プロセッサのグループ)への割当てを行う(スタティックスケジューリング)か、実行時に割当てを行うためのダイナミックスケジューリングコードをDynamic CPアルゴリズムを用いて生成し、これをプログラム中に埋め込む。これは、従来のマルチプロセッサのようにOSあるいはライブラリに粗粒度タスクの生成、スケジューリングを依頼すると数千から数万クロックのオーバーヘッドが生じてしまう可能性があり、これを避けるためである。
また、このスタティックスケジューリング及びダイナミックスケジューリングコードの生成の時には、各プロセッサ上のローカルメモリあるいは分散共有メモリを有効に使用し[19-22]プロセッサ間データ転送量を最小化するためのデータローカライゼーション手法[17、27]も用いられる。
データローカライゼーションは、MTG上でデータ依存のある複数の異なるループにわたりイタレーション間のデータ依存を解析し(インターループデータ依存解析)、データ転送が最小になるようにループとデータを分割(ループ整合分割)後、それらのループとデータが同一のプロセッサにスケジューリングされるように指定するパーシャルスタティックスケジューリングアルゴリズムを用いてダイナミックスケジューリングコードを生成する。
またこの際、データローカライゼーションによっても除去できなかったプロセッサ間データ転送を、データ転送とマクロタスク処理をオーバーラップして行うことにより、データ転送オーバーヘッドを隠蔽しようとするプレロード・ポストストアスケジューリングアルゴリズムも使用される[15]。
(2) ループ並列処理
マルチグレイン並列化では、マクロデータフロー処理によりプロセッサクラスタ(PC)に割当てられるループ(RB)は、そのRBがDoall、 あるいはDoacrossループ)の場合PC内のプロセッサによりイタレーションレベルで並列処理される。
ループ・リストラクチャリングとしては、以下のような従来の技術をそのまま利用できる。
(a)ステートメントの実行順序の変更
(b)ループディストリビューション
(c)ノードスプリッティング、スカラエクスパンション
(d)ループインターチェンジ
(e)ループアンローリング
(f)ストリップマイニング
(g)アレイプライベタイゼーション
(h)ユニモジュラー変換(ループリバーサル、パーミュテーション、スキューイング)
また、ループ並列化が適用できないループに関しては、図3の階層的なマクロタスクの定義のように、ループボディ部を後述する(近)細粒度並列処理か、ボディ部を階層的にマクロタスクに分割しマクロデータフロー処理を適用する。
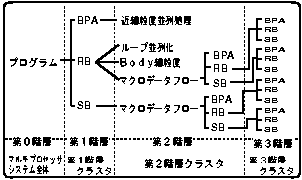
図3 階層的なマクロタスクの定義
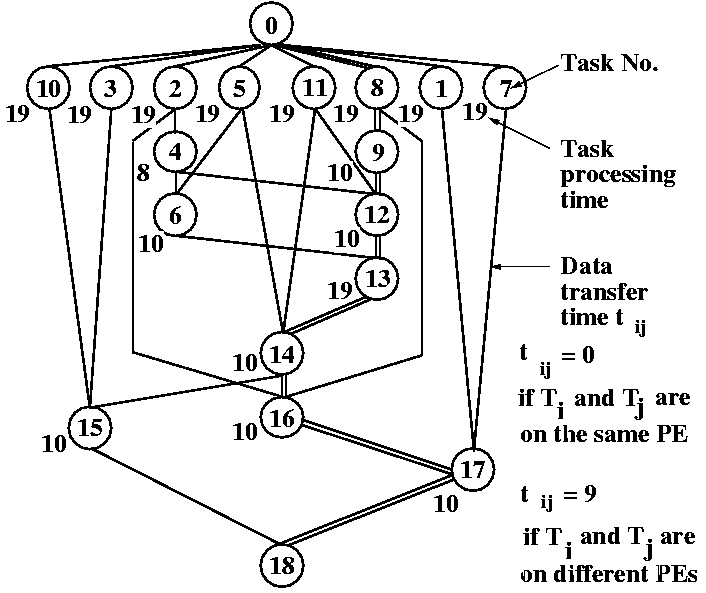
図4 近細粒度タスクグラフ
(3)(近)細粒度並列処理 PCに割当てられるMTがBPA、またはループ並列化あるいは階層的にマクロデータフロー処理を適用できないRB等の場合には、BPA内部のステートメントあるいは命令を(近)細粒度タスクとしてPC内プロセッサで並列処理する。
マルチプロセッサシステムあるいはシングルチップ・マルチプロセッサ上での近細粒度並列処理[11、14]では、プロセッサ間の負荷バランスだけでなくプロセッサ間データ転送をも最小にするようにタスクをプロセッサにスケジューリングしなければ、効率良い並列処理は実現できない。さらに、この近細粒度並列処理で要求されるスケジューリングでは、図4に示すようにタスク間にはデータ依存による実行順序制約があるため強NP完全な非常に難しいスケジューリング問題[13]となるが、CP/DT/MISF (Critical Path/Data Transfer/Most Immediate Successors First)法等のスタティックヒューリスティック・アルゴリズムの使用により実マルチプロセッサシステム上でも効率良い並列処理が行えることが確かめられている。
次にコンパイラは、図5に示すようにタスクスケジューリング、データ分割・配置決定後、各プロセッサで実行される並列化マシンコードあるいは拡張Fortran言語等を生成する。各プロセッサで実行されるべき並列マシンコードは、そのプロセッサに割当てられたタスクコード、プロセッサ間でのデータ転送のためのコード、及び同期のためのコード等から構成される。
このマシンコード生成時には、同一プロセッサに割当てられたタスク間でのデータ授受のためのレジスタ利用の最適化、データ転送オーバーヘッド最小化を目指したプロセッサ間データ転送モードの最適化、同期オーバーヘッドの最小化を目指した冗長な同期コードの削除等が行われる。特にシングルチップ・マルチプロセッサでは、コード生成時に厳密なコード実行スケジューリングを行うことにより、実行時のデータ転送タイミングを含めた全ての命令実行をコンパイラが制御し、全ての同期コードを除去して並列実行を可能とする無同期並列化[11]のような究極的な最適化も行える。
3.2.2.3 アーキテクチャサポート
3.2.2.2で述べたマルチグレイン並列処理をマルチプロセッサシステム上で実現しようとする時に望まれるアーキテクチャサポートについて述べる。
(1)集中・分散共有メモリとローカルメモリ
粗粒度並列処理では、条件分岐に対処するためにダイナミックスケジューリングが使用される。この場合、マクロタスクがどのプロセッサで実行されるかはコンパイル時には分からない。したがって、ダイナミックにスケジューリングされるマクロタスク間の共有データは(集中)共有メモリに配置できることが好ましい。
また、粒度によらずスタティックスケジューリングが適用できる場合には、あるマクロタスクが定義する共有データをどのプロセッサが必要とするかはコンパイル時に分かるため、生産側のプロセッサが消費側のプロセッサ上の分散共有メモリにデータと同期用のフラグを直接書き込めることが好ましい。これにより集中共有メモリを介してデータ転送する場合に比べ同期を含めたオーバーヘッドが1/2以下に軽減される。
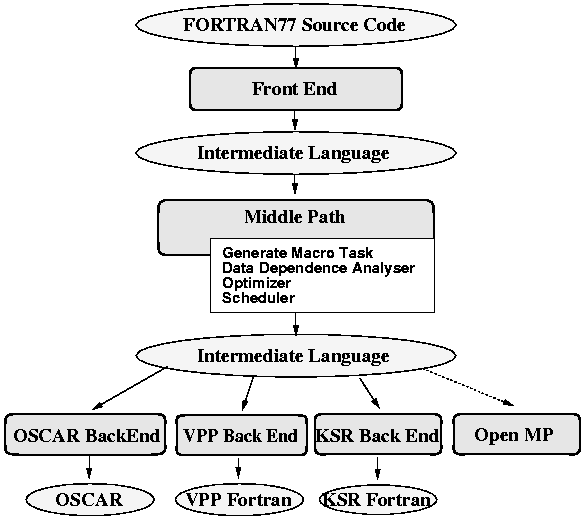
図5 OSCAR Multigrain Compilerの構成
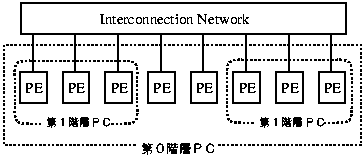
図6 プロセッサクラスタの階層的定義
さらにタスクローカルなデータあるいはデータローカライゼーション手法によりマクロタスク間でローカルにデータの授受が可能な場合には、各プロセッサ上のローカルメモリあるいは分散共有メモリにそれらのデータを割当てることによりデータ転送オーバーヘッドを顕著に削減できる。
また、プログラムコードはデータと比べ小さいことが多く、さらにスタティックスケジューリングを行う場合には各プロセッサ毎に別々のプログラムを生成した法が効率良い並列処理が行えるため、できる限りローカルメモリにおくことが望ましい。
(2)可変プロセッサクラスタリングと同期
マルチグレイン並列処理では、図3のようなプログラム中の何階層目にどの粒度の並列性がどの程度あるのかによって、階層的なプロセッサクラスタの構成(図6)もソフトウェア的に変えられるクロスバのようなネットワークが望ましい。また、それに応じクラスタ内でバリア同期が高速にとれること(可変バリア)が望ましい。
また、近細粒度並列処理においては分散あるいは集中共有メモリ、共有キャッシュ、共有レジスタ等を用いた細粒度データ転送及びデータ同期を高速にとることを可能とするアーキテクチャサポートが必要である。
さらに、プロセッサをクラスタリングした場合でも各プロセッサから集中共有メモリへ直接アクセスできることが望ましい。
(3)処理とデータ転送オーバーラッピング用データ転送ユニット
データローカライゼーションあるいはデータ転送を考慮したスケジューリングで除去できなかったプロセッサ間データ転送は、マクロタスクの実行とオーバーラップして行なわれる。すなわち、スタティックスケジューリングモードでも、ダイナミックスケジューリングモードでもマクロタスクの実行が始まる前にデータが自プロセッサ上のメモリにロードされていることが好ましい。このためには、コンパイラが制御できる高機能なデータ転送ユニットが必要である。
(4)ソフトウェア制御キャッシュ
マクロデータフロー処理のようなダイナミックスケジューリング環境下での、データローカライゼーション及び高度データ転送ユニットを用いた処理とデータ転送のオーバーラッピングスケジューリング技術の融合は、コンパイラとコンパイラがプログラム情報を埋め込んだダイナミックスケジューリングコードによって、ノーミスヒットのキャッシュの実現にもつながると考えられる。
現在筆者らは、以上のような要求をほぼ満たしているマルチプロセッサOSCARをベースに、次世代のスーパーコンピュータアーキテクチャ及びシングルチップ・マルチプロセッサの評価・検討を行っている[23、24]。
3.2.2.4 まとめ
本報告書では、今後シングルチップ・マルチプロセッサからスーパーコンピュータまで適用可能なフレキシブルかつ強力な並列処理手法であるマルチグレイン並列コンパイレーション技術と、そのためのアーキテクチャ・サポートについて述べた。
マルチグレイン並列化は、データローカライゼーション(データ自動分散技術)、データプレロード・ポストストアスケジューリング技術(処理とデータ転送のオーバーラッピング技術)等の技術と共に、マルチプロセッサシステムの実効性能を向上させシステムの価格性能比の向上を可能とするだけではなく、逐次プログラム全域から細粒度から粗粒度に至る全ての並列性を自動的に抽出することを可能とする使い易いマルチプロセッサシステムの構築を可能とする。
このようなマルチグレイン並列化コンパイラとそれを効果的に実現するアーキテクチャの実用化により、ハイパフォーマンスコンピュータの市場を拡大、及びシングルチップ・マルチプロセッサによる汎用マイクロプロセッサ市場への参入を可能とすると考えられる。
特に、現在劣性の汎用マイクロプロセッサ市場への参入し、21世紀に情報産業で世界をリードする技術を得るためには、デバイス技術、アーキテクチャ技術、コンパイラ技術、OS技術等をバーティカル・インテグレーションする新しい形態の国家プロジェクトの推進が望まれる。
参考文献
[1] D.Burger, J.R.Goodman, "Billion Transistor Architectures," IEEE Computer,
Vol.30,No.9, pp.47-49, Sep.,1997.
[2] L.Hammond, et.al, "A Single-Chip Multiprocessor", IEEE Computer, Vol.30, No.9,
pp.79-85, Sep.,1997.
[3] M.H.Lipasti, J.P.Shen, "Superspeculative Microarchitecture for Beyond AD
2000," IEEE Computer, Vol.30, No.9, Vol.30, No.9,pp59-66, Sep.1997.
[4] H.Kasahara, et.al., "A Multi-Grain Parallelizing Compilation Scheme for OSCAR
(OptimallyScheduled Advanced Multiprocessor)," Proc. Languages and Compilers
for Parallel Computing, Lect. Notes Comput Sci., Springer-Verlag, Vol.589, 1992.
[5] U.Banerjee, Loop Parallelization, Kluwer Academic Pub., 1994.
[6] D.J.Lilja, "Exploiting the Parallelism Available in loops," IEEE Computer,
pp.13-26, Vol.27, No.2, Feb.1994.
[7] M. Wolfe, High Performance Compilers for Parallel Computing, Addison Wesley,
1996.
[8] 笠原, 並列処理技術、コロナ社、 1991年.
[9] 笠原、情報処理学会編情報処理ハンドブック第3編計算機アーキテクチャ 7章・
並列計算機 6節・基本ソフトウェア、 オーム社、1995年.
[10] 笠原、 "並列処理のためのシステムソフトウェア"、 情報処理 Vol.34, No.9,
1993年9月.
[11] 笠原、 ”マルチプロセッサシステム上での近細粒度並列処理”、情報処理、Vol.37,
No.7, Jul. 1996.
[12] B. Blume, R.Eigenmann, D.Padua, et.al., "Polaris: Then Next Generation
on Parallelizing Compilers", 7th Annual Workshop on Languages and Compilers for
Parallel Computing, 1993.
[13] H.Kasahara, S.Narita, "Practical Multiprocessor Scheduling Algorithms
for Efficient Parallel Processing," IEEE Trans. on Computers, Vol.C-33, No.11,
Nov. 1984.
[14] H.Kasahara, H.Honda, et.al., "Parallel processing of Near Fine Grain Tasks
Using Static Scheduling on OSCAR (Optimally Scheduled Advanced Multiprocessor),"
Proc. of IEEE Supercomputing '90, Nov. 1990.
[15] 藤原、笠原等、"データプレロードおよびポストストアを考慮したマルチプロセッ
サスケジューリングアルゴリズム"、 電子情報通信学会論文誌D-1、 Vol.75,
No.8,pp.495-503, 1992年8月.
[16] 笠原、吉田、本多、合田等、"Fortranマクロデータフロー処理のマクロタスク生
成手法"、電子情報通信学会論文誌D-1、 Vol.75, No.8, 1992年8月.
[17] A.Yoshida, H.Kasahara, et.al., "Data-Localization for Fortran Macrodataflow
Computation Using Partial Static Task Assignment," Proc. ACM Int. Conf.
on Supercomputing, May 1996.
[18] U. Banerjee, R. Eigenmann, A. Nicolau, D.Padua, "Automatic program
parallelization," Proceedings of IEEE, Vol.81, No.2, pp.211-243, Fev. 1993.
[19] P.Tu and D.Padua, "Automatic Array Privatization," 6th Annual Workshop
on Languages and Compilers for Parallel Computing, 1993.
[20] M.Gupta and P.Banerjee, "Demonstration of Automatic Data Partitioning
Techiniques for Parallelizing Compilers on Multicomputers," IEEE Trans.
on Parallel and Ditributed System, Vol.3, No.2, pp.179-193, 1992.
[21] J.M.Anderson amd M.S.Lam, "Global Optimizations for Parallelism and Locality
on Scalable Parallel Machines," Proc. of the SIGPLAN '93 Conference
on Programming Language Design and Implementation, pp.112-125,1993.
[22] A.Agrawal, D.A.Kranz, V.Natarajan, "Automatic partitioning of parallel loops and data arrays for distributed shared-memory multiprocessors", IEEE Trans.
on Parallel and Distributed System, Vol.6, No.9,pp.943-962, 1995.
[23] 小幡、笠原等、"科学技術計算プログラムにおけるマルチグレイン並列性の評価"、情報処理学会第56回全国大会、 2E-07,Mar. 1998.
[24] 木村、笠原等、"マルチグレイン並列処理用シングルチップマルチプロセッサアーキテクチャ"、情報処理学会第56回全国大会、 1N-03,Mar. 1998.
[25] H.Kasahara, et.al, "OSCAR Multigrain Architecture and its performance", Proc.
International Workshop on Innovative Architecture for Futer Generation
High-Performance Processors and Sytems, IEEE Press, Oct. 1997.
[26] 本多、笠原等、"Fortranプログラム粗粒度タスク間の並列性検出手法"、 電子情報通信学会論文誌D-1 Vol.73, No.12, pp.951-960, 1990年12月.
[27] H.Kasahara, A.Yoshida,, et.al, "A Data-Localization Compilation Scheme Using Partial Static Task Assignment for Fortran Coarse Grain Parallel Processing ", Journal on Parallel Computing (Special Issue on Languages and Compilers for Parallel Computing), May. 1998.